标签:
上一篇中分析了Scala版的console producer代码,这篇文章来分析一下console consumer的工作原理。其实不论是哪个consumer,大部分的工作原理都是类似的。我们用console consumer作为切入点,既容易理解又不失一般性。
首先需要说明的,我使用的Kafka环境是Kafka0.8.2.1版本,这也是最新的版本。另外我们主要分析consumer的原理,没有过分纠结于console consumer的使用方法——所以我在这里选用了最简单的一条命令作为开始:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test-topic
通过查看kafka-console-consumer.sh脚本,可以看到主要的调用方法是:exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleConsumer $@
这个shell脚本调用了kafka.tools包下的ConsoleConsumer类,并将命令行参数全部传给了这个类。我们现在来看看这个类的主要逻辑。Console consumer的主要工作原理如下图所示:
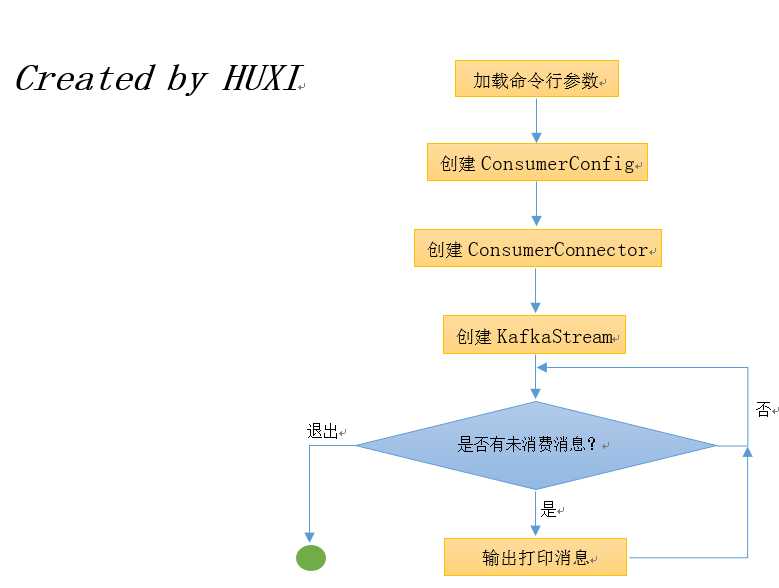
从根本上来说,console consumer启动之后会创建一个KafkaStream不停地等待消费新的消息——具体原理是通过LinkedBlockingQueue阻塞队列来实现(后面会分析是怎么做的)。下面我们就从ConsoleConsumer.scala开始说起。
1. 先从ConsoleConsumer开始看
这个类有个main方法,可以看出这个是可执行的Scala类。类的前100多行几乎都在处理命令行参数的解析。其中真正必要的参数只有zookeeper.connect一个,如下面代码所示。
// REQUIRED表示这是一个必须要指定的参数 val zkConnectOpt = parser.accepts("zookeeper", "REQUIRED: The connection string for the zookeeper connection in the form host:port. " + "Multiple URLS can be given to allow fail-over.") .withRequiredArg .describedAs("urls") .ofType(classOf[String])
乍一看这和官网上说的似乎不匹配,因为官网中说consumer真正必要的参数实际上有两个:zookeeper.connect和group.id。很显然console consumer会自己生成group.id的值。console consumer本质上也是一个consumer,必然属于一个消费组,也有它自己的consumer id。下面的代码中展示了console consumer如何生成自己的group id: (consumer id的生成后面再说)
// 如果没有显式指定group.id,那么代码就自己合成一个 // 具体格式: console-consumer-[10万以内的一个随机数] // 10万是一个很大的数,因此只有非常低的几率会碰到多个console consumer的group id相同的情况 if(!consumerProps.containsKey("group.id")) { consumerProps.put("group.id","console-consumer-" + new Random().nextInt(100000)) groupIdPassed=false }
确定了consumer的group.id之后,下面就要开始把这些参数封装进ConsumerConfig类中并把后者传给Consumer的create方法以构造一个ConsumerConnector——即初始化consumer了,具体逻辑见下面的代码:
1 val config = new ConsumerConfig(consumerProps) // 封装ConsumerConfig配置类 2 val skipMessageOnError = if (options.has(skipMessageOnErrorOpt)) true else false 3 val messageFormatterClass = Class.forName(options.valueOf(messageFormatterOpt)) // 创建消息格式类,用于最后的输出显示 4 val formatterArgs = CommandLineUtils.parseKeyValueArgs(options.valuesOf(messageFormatterArgOpt)) 5 val maxMessages = if(options.has(maxMessagesOpt)) options.valueOf(maxMessagesOpt).intValue else -1 6 val connector = Consumer.create(config) // 创建ConsumerConnector,Consumer核心接口
上面代码中的最后一句非常重要,因为console consumer在启动的时候必须要创建一个ConsumerConnector接口。该接口实际上是一个Scala的trait类型,类似于Java的interface,里面定义了很多抽象方法,比较重要的方法有createMessageStreams, createMessageStreamsFilter和commitOffsets等。Kakfa官网把这个接口称为high level的consumer API。 对于大多数consumer来说,这个high level的consumer API就已经足够了,但有些程序可能有重设位移这样的需求,此时Kafka推荐它使用low level的consumer API —— SimpleConsumer。okay,扯得有点远了,大家可以参考这篇文章来学习high level API的具体用法。
2. ConsumerConnector与它的实现类ZookeeperConsumerConnector
目前,Kafka代码中只定义了一个实现类,即ZookeeperConsumerConnector。在具体讨论这个类的构造之前,我们先理清一些基本概念。Kafka consumer的位移信息默认是保存在Zookeeper中的,具体的路径是/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset)。Kafka 0.8.2版本开始支持在Kafka中保存consumer的位移,因为Kafka团队认为zookeeper并不适合频繁地做更新,因此Kafka用一个特殊topic来保存consumer的位移。我们可以使用offsets.storage属性来指定到底使用哪种存储来保存位移——值得注意的是,目前zookeeper还是默认的保存方式,本文也将以zookeeper的方式进行讨论。
继续说回ZookeeperConsumerConnector类实例的创建,这个类在创建的时候都做了什么呢?如果浏览该类的代码,可以发现这是一个很长的类。我们目前不用去管那些东西,只需要关注下面的几行语句:
1 // topicRegistry是一个ConcurrentHashMap,key是topic名,value是另一个ConcurrentHashMap,后者的key是分区Id,后者的value是PartitionTopicInfo 2 // PartitionTopicInfo数据结构很重要,里面包含了要处理的消息队列以及位移信息 3 // 后面会说到这个变量 4 private var topicRegistry = new Pool[String, Pool[Int, PartitionTopicInfo]] 5 // 当前这个consumerConnector缓存过的topic分区对应的位移值,后面提交位移的时候需要使用它与要提交的位移进行比较,也是很重要的一个变量 6 private val checkpointedZkOffsets = new Pool[TopicAndPartition, Long] 7 // 定义了哪个topic的哪个消费线程所使用的消息阻塞队列 8 private val topicThreadIdAndQueues = new Pool[(String, ConsumerThreadId), BlockingQueue[FetchedDataChunk]] 9 // Kafka的调度器,不用太管它的具体实现。只需要知道它后面会创建一个定时任务用于定时提交位移到zookeeper中 10 private val scheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "kafka-consumer-scheduler-") 11 ... 12 // 这段代码就是要计算consumer.id,可以看出格式就是[group id]_[主机名]_随机UUID的前8位——如果没有指定consumer id的话 13 val consumerIdString = { 14 var consumerUuid : String = null 15 config.consumerId match { 16 case Some(consumerId) // for testing only 17 => consumerUuid = consumerId 18 case None // generate unique consumerId automatically 19 => val uuid = UUID.randomUUID() 20 consumerUuid = "%s-%d-%s".format( 21 InetAddress.getLocalHost.getHostName, System.currentTimeMillis, 22 uuid.getMostSignificantBits().toHexString.substring(0,8)) 23 } 24 config.groupId + "_" + consumerUuid 25 ... 26 connectZk() // 创建一个zookeeper客户端用于操作ZK 27 createFetcher() // 创建一个Fetcher,后面会展开细说 28 ensureOffsetManagerConnected() //如果是使用zookeeper来保存则没有作用
上面的代码基本覆盖了ZookeeperConsumerConnector启动时候的主要工作,其中值得细说的就是createFetcher方法,以下是它的代码:
1 private def createFetcher() { 2 if (enableFetcher) 3 fetcher = Some(new ConsumerFetcherManager(consumerIdString, config, zkClient)) 4 }
ConsumerFetcherManager是为consumer使用的获取线程管理器。
未完待续。。。
【原创】Kafka console consumer源代码分析
标签:
原文地址:http://www.cnblogs.com/huxi2b/p/4671925.html