标签:
从官网搬过来的 囧rz
哈工大讯飞语言云 由哈工大 和科大讯飞 联合研发的中文自然语言处理云服务平台。结合了哈工大“语言技术平台——LTP” 高效、精准的自然语言处理核心技术和讯飞公司在全国性大规模云计算服务方面的 丰富经验,显著提升 LTP 对外服务的稳定性和吞吐量,为广大用户提供电信级稳定 性和支持全国范围网络接入的语言云服务,有效支持包括中小企业在内开发者的商 业应用需要。
作为基于云端的服务,语言云具有如下一些优势:
在运算资源有限,编程语言受限的情况下,语言云无疑是用户进行语言分析更好的选择。
有关更多语言云API的使用方法,请参考:http://www.ltp-cloud.com/document/
中文分词 (Word Segmentation, WS) 指的是将汉字序列切分成词序列。 因为在汉语中,词是承载语义的最基本的单元。分词是信息检索、文本分类、情感分析等多项中文自然语言处理任务的基础。
例如,句子
国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。
正确分词的结果是
国务院/ 总理/ 李克强/ 调研/ 上海/ 外高桥/ 时/ 提出/ ,/ 支持/ 上海/ 积极/ 探索/ 新/ 机制/ 。
如果分词系统给出的切分结果是
国务院/ 总理/ 李克/ 强调/ 研/ 上海 …因为强调也是一个常见的词,所以很可能出现这种分词结果。 那么,如果想要搜索和李克强相关的信息时,搜索引擎就很难检索到该文档了。
切分歧义是分词任务中的主要难题。 LTP的分词模块基于机器学习框架,可以很好地解决歧义问题。 同时,模型中融入了词典策略,使得LTP的分词模块可以很便捷地加入新词信息。
词性标注(Part-of-speech Tagging, POS)是给句子中每个词一个词性类别的任务。 这里的词性类别可能是名词、动词、形容词或其他。 下面的句子是一个词性标注的例子。 其中,v代表动词、n代表名词、c代表连词、d代表副词、wp代表标点符号。
国务院/ni 总理/n 李克强/nh 调研/v 上海/ns 外高桥/ns 时/n 提出/v ,/wp 支持/v 上海/ns 积极/a 探索/v 新/a 机制/n 。/wp词性作为对词的一种泛化,在语言识别、句法分析、信息抽取等任务中有重要作用。 比方说,在抽取“歌曲”的相关属性时,我们有一系列短语:
儿童歌曲
欢快歌曲
各种歌曲
悲伤歌曲
...如果进行了词性标注,我们可以发现一些能够描述歌曲属性的模板,比如
[形容词]歌曲
[名词]歌曲
而[代词]歌曲往往不是描述歌曲属性的模板。
词性标记集:LTP中采用863词性标注集,其各个词性含义如下表:
| Tag | Description | Example | Tag | Description | Example |
|---|---|---|---|---|---|
| a | adjective | 美丽 | ni | organization name | 保险公司 |
| b | other noun-modifier | 大型, 西式 | nl | location noun | 城郊 |
| c | conjunction | 和, 虽然 | ns | geographical name | 北京 |
| d | adverb | 很 | nt | temporal noun | 近日, 明代 |
| e | exclamation | 哎 | nz | other proper noun | 诺贝尔奖 |
| g | morpheme | 茨, 甥 | o | onomatopoeia | 哗啦 |
| h | prefix | 阿, 伪 | p | preposition | 在, 把 |
| i | idiom | 百花齐放 | q | quantity | 个 |
| j | abbreviation | 公检法 | r | pronoun | 我们 |
| k | suffix | 界, 率 | u | auxiliary | 的, 地 |
| m | number | 一, 第一 | v | verb | 跑, 学习 |
| n | general noun | 苹果 | wp | punctuation | ,。! |
| nd | direction noun | 右侧 | ws | foreign words | CPU |
| nh | person name | 杜甫, 汤姆 | x | non-lexeme | 萄, 翱 |
命名实体识别 (Named Entity Recognition, NER) 是在句子的词序列中定位并识别人名、地名、机构名等实体的任务。 如之前的例子,命名实体识别的结果是:
国务院 (机构名) 总理李克强 (人名) 调研上海外高桥 (地名) 时提出,支持上海 (地名) 积极探索新机制。
命名实体识别对于挖掘文本中的实体进而对其进行分析有很重要的作用。
命名实体识别的类型一般是根据任务确定的。LTP提供最基本的三种实体类型人名、地名、机构名的识别。 用户可以很容易将实体类型拓展成品牌名、软件名等实体类型。
依存语法 (Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关 系。仍然是上面的例子,其分析结果为:
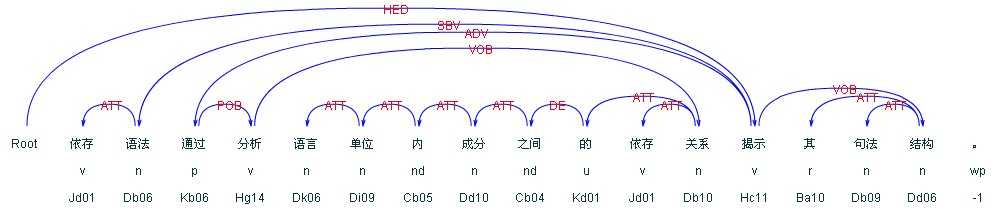
从分析结果中我们可以看到,句子的核心谓词为“提出”,主语是“李克强”,提出的宾语是“支持上海…”,“调研…时”是“提出”的 (时间) 状语,“李克强”的修饰语是“国务院总理”,“支持”的宾语是“探索 新机制”。有了上面的句法分析结果,我们就可以比较容易的看到,“提出者”是“李克强”,而不是“上海”或“外高桥”,即使它们都是名词,而且距离“提出”更近。
依存句法分析标注关系 (共14种) 及含义如下:
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <-- 送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花 (送 --> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花 (送 --> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读 (书 <-- 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 --> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <-- 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <-- 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 --> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 --> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 --> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <-- 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 --> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
语义角色标注 (Semantic Role Labeling, SRL) 是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等。其能够对问答系统、信息抽取和机器翻译等应用产生推动作用。 仍然是上面的例子,语义角色标注的结果为:

其中有三个谓词提出,调研和探索。以探索为例,积极是它的方式(一般用ADV表示),而新机制则是它的受事(一般用A1表示)
核心的语义角色为 A0-5 六种,A0 通常表示动作的施事,A1通常表示动作的影响等,A2-5 根据谓语动词不同会有不同的语义含义。其余的15个语义角色为附加语义角色,如LOC 表示地点,TMP 表示时间等。附加语义角色列表如下:
| 标记 | 说明 |
| ADV | adverbial, default tag ( 附加的,默认标记 ) |
| BNE | bene?ciary ( 受益人 ) |
| CND | condition ( 条件 ) |
| DIR | direction ( 方向 ) |
| DGR | degree ( 程度 ) |
| EXT | extent ( 扩展 ) |
| FRQ | frequency ( 频率 ) |
| LOC | locative ( 地点 ) |
| MNR | manner ( 方式 ) |
| PRP | purpose or reason ( 目的或原因 ) |
| TMP | temporal ( 时间 ) |
| TPC | topic ( 主题 ) |
| CRD | coordinated arguments ( 并列参数 ) |
| PRD | predicate ( 谓语动词 ) |
| PSR | possessor ( 持有者 ) |
| PSE | possessee ( 被持有 ) |
中文分词指的是将汉字序列切分成词序列的问题。 因为在汉语中,词是承载语义的最基本的单元,分词成了是包括信息检索、文本分类、情感分析等多项中文自然语言处理任务的基础。
由于在自然语言处理框架中的基础地位,很多学者对于中文分词任务进行了深入的研究。 主流的分词算法包括基于词典匹配的方法和基于统计机器学习的方法。 LTP分词模块使用的算法将两种方法进行了融合,算法既能利用机器学习较好的消歧能力,又能灵活地引入词典等外部资源。
在LTP中,我们将分词任务建模为基于字的序列标注问题。 对于输入句子的字序列,模型给句子中的每个字标注一个标识词边界的标记。
同时,为了提高互联网文本特别是微博文本的处理性能。我们在分词系统中加入如下一些优化策略:
分词模块在人民日报数据集上的性能如下
| P | R | F | |
| 开发集 | 0.973152 | 0.972430 | 0.972791 |
| 测试集 | 0.972316 | 0.970354 | 0.972433 |
与分词模块相同,我们将词性标注任务建模为基于词的序列标注问题。 对于输入句子的词序列,模型给句子中的每个词标注一个词性标记。 在LTP中,我们采用的北大标注集。
词性标注模块在人民日报数据集上的性能如下。
| P | |
|---|---|
| 开发集 | 0.979621 |
| 测试集 | 0.978337 |
与分词模块相同,我们将命名实体识别建模为基于词的序列标注问题。对于输入句子的词序列,模型给句子中的每个词标注一个标识命名实体边界和实体类别的标记。在LTP中,我们支持人名、地名、机构名三类命名实体的识别。
基础模型在几种数据集上的性能如下:
| P | R | F |
|---|---|---|
| 开发集 | 0.924149 | 0.909323 |
| 测试集 | 0.939552 | 0.936372 |
基于图的依存分析方法由McDonald首先提出,他将依存分析问题归结为在一个有向图中寻找最大生成树(Maximum Spanning Tree)的问题。
在依存句法分析模块中,LTP分别实现了
在LDC数据集上,三种不同解码方式对应的性能如下表所示。
| model | 1o | 2o-sib | 2o-carreras | |||
|---|---|---|---|---|---|---|
| Uas | Las | Uas | Las | Uas | Las | |
| Dev | 0.8190 | 0.7893 | 0.8501 | 0.8213 | 0.8582 | 0.8294 |
| Test | 0.8118 | 0.7813 | 0.8421 | 0.8106 | 0.8447 | 0.8138 |
| Speed | 49.4 sent./s | 9.4 sent./s | 3.3 sent./s | |||
| Mem. | 0.825g | 1.3g | 1.6g |
在LTP中,我们将SRL分为两个子任务,其一是谓词的识别(Predicate Identification, PI),其次是论元的识别以及分类(Argument Identification and Classification, AIC)。对于论元的识别及分类,我们将其视作一个联合任务,即将“非论元”也看成是论元分类问题中的一个类别。在SRL系统中,我们在最大熵模型中引入 L1正则,使得特征维度降至约为原来的1/40,从而大幅度地减小了模型的内存使用率,并且提升了预测的速度。同时,为了保证标注结果满足一定的约束条 件,系统增加了一个后处理过程。
在CoNLL 2009评测数据集上,利用LTP的自动词性及句法信息,SRL性能如下所示。
| Precision | Recall | F-Score | Speed | Mem. |
|---|---|---|---|---|
| 0.8444 | 0.7234 | 0.7792 | 41.1 sent./s | 94M(PI+AIC) |
标签:
原文地址:http://www.cnblogs.com/CheeseZH/p/4682353.html