标签:style blog class ext int string
MapReduce job中,可以使用FileInputFormat和FileOutputFormat来对输入路径和输出路径来进行设置。在输出目录中,框架自己会自动对输出文件进行命名和组织,如:part-(m|r)-00000之类。但有时为了后续流程的方便,我们常需要对输出结果进行一定的分类和组织。以前常用的方法是在MR job运行过后,用脚本对目录下的数据进行一次重新组织,变成我们需要的格式。研究了一下MR框架中的MultipleOutputs(是2.0之后的新API,是对老版本中MultipleOutputs与MultipleOutputFormat的一个整合)。
1. 需求,下面是有些测试数据,要对这些数据按类目输出到output中:
1512,iphone5s,4英寸,指纹识别,A7处理器,64位,M7协处理器,低功耗
1512,iphone5,4英寸,A6处理器,IOS7
1512,iphone4s,3.5英寸,A5处理器,双核,经典
50019780,ipad,9.7英寸,retina屏幕,丰富的应用
50019780,yoga,联想,待机18小时,外形独特
50019780,nexus 7,华硕&google,7英寸
50019780,ipad mini 2,retina显示屏,苹果,7.9英寸
1101,macbook air,苹果超薄,OS X mavericks
1101,macbook pro,苹果,OS X lion
1101,thinkpad yoga,联想,windows 8,超级本
2. API简介:
MutipleOutput是调用自己的writer方法来实现输出路径的定制的。首先来看看writer方法的几种重载方式:
(1). write(String namedOutput,Text key,IntWritable value) throws IOException,InterruptedException
讲key,value写入到以namedOutput开头的文件中,格式如:{namedOutput}-(m|r)-{part-number}
(2).write(Text key,IntWritable value,String baseOutputPath) throws IOException,InterruptedException
将key,value写入到baseOutputPath所指定的目录下,在目录下系统会自动为文件生成unique的文件名字;
(3).write(String namedOutput,Text key,Object value,String baseOutputPath) throws IOException,InterruptedException
应用在第1种和第2种需要共用的场景;
3. 下面来看一下代码,为了演示的简便只写了mapper函数,reducer同理:


需要引入:import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
在setup函数中
实例化MultipleOutputs对象mlo:mlo = new MultipleOutputs<Text,Text>(context);
在map()函数中,根据逗号对输入数据进行分割,然后直接调用mlo进行输出;采用了两种形式进行输出。
要注意的是hadoop是不承认未经注册namedOutput的,必须先在主函数中注册,然后才能写入,否则运行时会报not defined错误;所以要在主函数中用MultipleOutputs.addNamedOutput将对应的namedOutput文件注册一下,告诉hadoop可以写入:MultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class);
4. 运行这个数据后可以看到最终的数据结构目录如下:

(1) 其中/*/*/mlo/1101(隐私原因将具体名称隐去)、/*/*/mlo/1512、/*/*/mlo/50019780是对应:mlo.write(new Text(tokens[0]),new Text(line),outputPath + "/" + tokens[0]+ "/" ) 的按类目输出;
用hadoop fs -ls /*/*/mlo/1101看一下类目文件夹下面的结构如下:
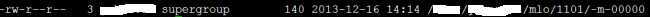
Hadoop框架会自动文件夹下的输出指定unique name;
用hadoop fs -cat /*/*/mlo/1101/-m-00000查看如下:

(2)其中/*/*/mlo/MOSText-m-00000是对应:mlo.write("MOSText", new Text(tokens[0]),line)的输出,
用hadoop fs -cat /*/*/mlo/MOSText-m-00000查看如下:

包含我们所有的输入数据
(3)另一个/*/*/mlo/part-m-00000文件应该是hadoop自己生成的,由于我们没有使用context进行写入操作,这个文件是空的。
使用hadoop multipleOutputs对输出结果进行不一样的组织,布布扣,bubuko.com
使用hadoop multipleOutputs对输出结果进行不一样的组织
标签:style blog class ext int string
原文地址:http://www.cnblogs.com/yuhan-TB/p/3705665.html