标签:
目录
1.1.2.????虚拟桶(virtual bucket)????3
1.1.3.????一致性哈希(consistent hashing)????4
?
?
?
?
大数据可以用4V来描述。
?
数据源,包括结构化数据、半结构化数据、非结构化数据。数据类型多样化。
结构化数据指的是数据描述和数据本身是分离的,存放在关系数据库中。
半结构化数据指的是数据的描述和数据本身掺杂在一起,比如邮件、xml文件、json格式、HTML页面。一般使用树、图结构存储。
非结构化数据指的是没有描述信息,比如音视频文件、图像等。没有固定的存储模型。
数据抽取与集成,指的是从原始的数据源中把数据提取出来,存放到一定的存储模型中,如HDFS、HBase、Redis等。
数据分析,指的是进行数据挖掘、机器学习、统计分析等,可以获取更加深层次的信息。
数据展示,指的是数据的显示,包括数据可视化、人机交互等。
传统的数据库中,数据量大了、运行速度慢了以后,可以通过提高单机的硬件水平来提高存储量或者查询速度,这叫做纵向扩展。缺点是成本高,收效越来越弱。
在大数据领域,一般是通过增加服务器来进行横向扩展。数据被分散存储在很多台服务器上,数据的查询通过对分散在很多台机器上面的数据查询进行汇总得到。
海量的数据按照什么规则分配到这么多服务器上?如何快速的查询位于某台服务器上的数据?当添加服务器或者下架服务器的时候,怎么办?
数据分配到服务器的方式称作数据分区。
快速查询位于服务器集群上的某条数据,称作数据路由。
?
当数据通过分区存储到集群后,会怎加数据访问失败的概率,这称作数据的可靠性。最简单的方式是使用副本机制。工业标准是副本数量为3。
?
副本机制,可以提高数据的安全性,可以通过并发读提高并发读取效率,可以通过查询最近位置提高单次读取效率。
?
副本机制,带来一个问题,就是写操作时,如何保持副本数据的一致性。
?
实现数据的分区与路由的方式,一般是二级映射机制。
?
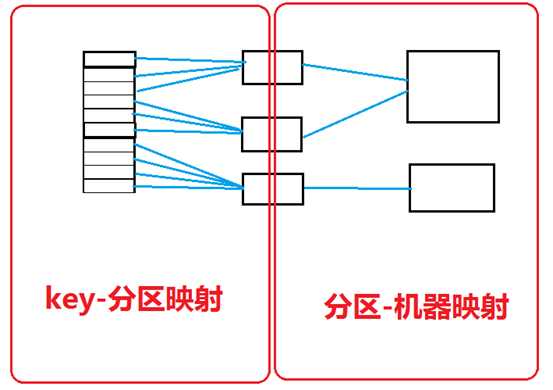
其中,key是划分到哪些分区上的?有两种算法,一是哈希分区算法,一是范围分区算法。
?
哈希分区是把某个key根据哈希算法计算的结果,放到指定的分区中,适合"键查询"。
?
范围分区是把一段联系的key放到指定的分区中,适合"范围查询"。
?
假设有k机器,把所有的机器从0到k-1编号,使用哈希函数hash(key) mod K 就可以把所有数据存放到K台机器中。取得时候,也按照哈希函数取值即可。
优点是实现简单。缺点是缺乏灵活性,比如增加或者减少机器时。
在key和机器之间,引入中间层,称作"虚拟桶",实现二级映射,就可以完美解决机器扩展性的问题。如数据库CouchBase。
?
哈希算法的致命缺陷是没有实现二级映射。
在分布式存储中,哈希算法在增删机器的场景下效率非常低,有解决方案吗?这就是一致性哈希算法。
Consistency强一致性、availability可用性、partition tolerance分区容错性,在一个大规模的分布式服务系统中不可能同时存在。
?
C指的是更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致
A指的是读和写操作都能成功
P指的是节点宕机不影响服务的运行。
?
?
? 1. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功
在没有出现网络故障的时候,满足CA原则,C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致, A 即我的读写操作都能够成功,但是当出现网络故障时,我不能同时保证CA,即P条件无法满足
? 2. 假设DB的更新操作是只写本地机房成功就返回,通过binlog/oplog回放方式同步至侧边机房
这种操作保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ,但是它不满足C,因为更新操作返回成功后,双边机房的DB看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
? 3. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务
降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足A可用性原则
?
选择权衡
通过上面的例子,我们得知,我们永远无法同时得到CAP这3个特性,那么我们怎么来权衡选择呢?
选择的关键点取决于业务场景
对于大多数互联网应用来说(如网易门户),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须需要保证的,所以只有设置一致性来保证服务的AP,通常常见的高可用服务吹嘘5个9 6个9服务SLA稳定性就本都是放弃C选择AP
对于需要确保强一致性的场景,如银行,通常会权衡CA和CP模型,CA模型网络故障时完全不可用,CP模型具备部分可用性,实际的选择需要通过业务场景来权衡(并不是所有情况CP都好于CA,只能查看信息不能更新信息有时候从产品层面还不如直接拒绝服务)
Atomicity原子性、consistency一致性、isolation独立性、durability持久性
?
关系数据库采用这套模型,保证高可靠和强一致性。
Basically availible基本可用、soft state软状态、eventual consistency最终一致性
?
Base是通过牺牲一致性来获得高可用。目前的大部分NoSQL数据库都是base理论。
数学中的幂等指的是如max(x,y)=x、and操作等等。
?
分布式系统中的幂等性指的是无论多少次调用,结果都是相同的。
?
因为在分布式系统中,有可能网络中断,造成通讯失败,幂等性非常重要。Zookeeper就是幂等性系统。
略
假设服务器A是一个反垃圾邮件服务器,A维护了一个可疑IP列表,列表中包含了大量的可疑的 IP地址。服务器B是另一个反垃圾邮件服务器,B也维护了一个可疑IP列表,列表中包含了大量的可疑的IP地址。两台服务器只能通过互联网通信。有一天, 服务器A需要确认自己的列表和服务器B的列表的相似度(即两者包含的相同的IP地址占所有IP地址的比例)。
?
首先,让我们来看看什么是Bloom Filter吧。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

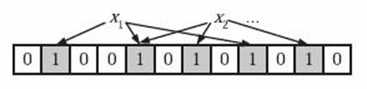
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为 1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。如下图所示,我们可以所有的元素xk映射到位数组 中。而m位的位数组就可以作为描述所有元素的简化版。
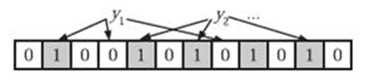
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
m的单位是bit,而n则是以元素个数为单位(准确的说是不同元素的个数,可以是字符串或者复制对象)。所以使用bloom filter内存上通常都是节省的。?
?
?
具有良好的时间和空间效率,尤其是空间效率极高。对于判断元素是否属于集合非常高效。比如google chrome使用它进行恶意url判断,网络爬虫使用它检查是否爬过特定的url,缓存数据等。如cassandra、hbase都采用了。
?
对一棵查找树(search tree)进行查询/新增/删除 等动作, 所花的时间与树的高度h 成比例, 并不与树的容量 n 成比例。如果可以让树维持矮矮胖胖的好身材, 也就是让h维持在O(lg n)左右, 完成上述工作就很省时间。能够一直维持好身材, 不因新增删除而长歪的搜寻树, 叫做balanced search tree(平衡树)。
构造平衡树,非常复杂。但是构造跳表非常简单,而且功能相同、效率相近。
跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,
它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,
就能轻松实现一个 SkipList。
?
?
?
有序表的搜索
考虑一个有序表:

从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数
为 2 + 4 + 6 = 12 次。有没有优化的算法吗?? 链表是有序的,但不能使用二分查找。类似二叉
搜索树,我们把一些节点提取出来,作为索引。得到如下结构:
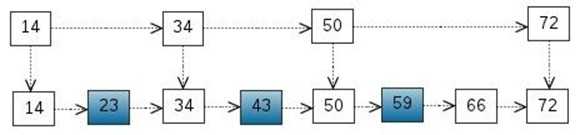
这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:
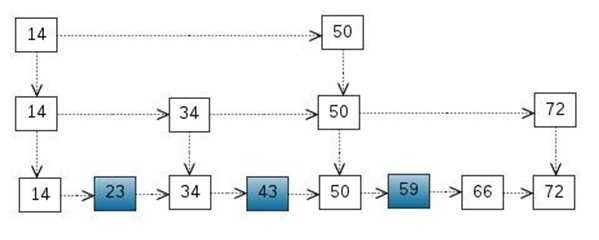
这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。
这基本上就是跳表的核心思想,其实也是一种通过"空间来换取时间"的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳表
下面的结构是就是跳表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的搜索
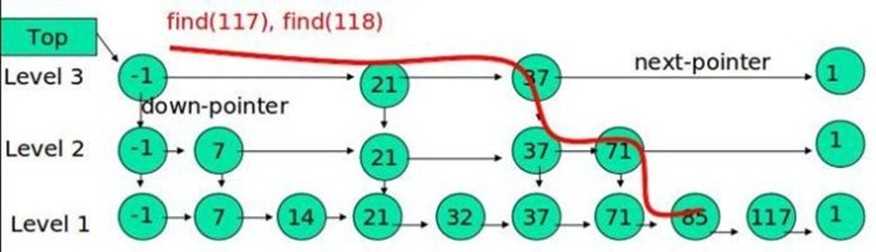
?
?
LSM树的本质是将大量的随机写操作转换成批量的序列写,这样可以极大的提升磁盘数据写入速度,所以LSM树非常适合对写操作效率有高要求的应用场景。但是读效率有些低,可以通过bloom filter或者缓存优化读性能。
LSM(Log Structured Merge Trees)数据组织方式被应用于多种数据库,如LevelDB、HBase、Cassandra等,下面我们从为什么使用LSM、LSM的实现思路两方面介绍这种存储组织结构,完成对LSM的初步了解。
? ?
存储背景回顾
LSM相较B+树或其他索引存储实现方式,提供了更好的写性能。究其原因,我们先回顾磁盘相关的一点背景知识。
? ?
顺序操作磁盘的性能,较随机读写磁盘的性能高很多,我们实现数据库时,也是围绕磁盘的这点特性进行设计与优化。如果让写性能最优,最佳的实现方式就是日志型(Log/Journal)数据库,其以追加(Append)的方式写磁盘文件。
? ?
有得即有舍,万事万物存在权衡,带来最优写性能的同时,单纯的日志数据库读性能很差,为找到一条数据,不得不遍历数据记录,要实现范围查询(range)几乎不可能。为优化日志型数据库的读性能,实际应用中通常结合以下几种优化措施:
二分查找(Binary Search): 在一个数据文件中使用二分查找加速数据查找
哈希(Hash): 写入时通过哈希函数将数据放入不同的桶中,读取时通过哈希索引直接读取
B+树: 使用B+树作为数据组织存储形式,保持数据稳定有序
外部索引文件: 除数据本身按日志形式存储外,另对其单独建立索引加速读取,如之前介绍的《一种Bitcask存储模型的实现》
以上措施都很大程度提升了读性能(如二分查找将时间复杂度提升至O(log(N))),但相应写性能也有折损,第一写数据时需要维护索引,这视索引 的实现方式,最差情况下可能涉及随机的IO操作;第二如果用B+树等结构组织数据,写入涉及两次IO操作,先要将数据读出来再写入。
LSM存储结构
LSM存储实现思路与以上四种措施不太相同,其将随机写转化为顺序写,尽量保持日志型数据库的写性能优势,并提供相对较好的读性能。具体实现方式如下:
1. 当有写操作(或update操作)时,写入位于内存的buffer,内存中通过某种数据结构(如skiplist)保持key有序
2. 一般的实现也会将数据追加写到磁盘Log文件,以备必要时恢复
3. 内存中的数据定时或按固定大小地刷到磁盘,更新操作只不断地写到内存,并不更新磁盘上已有文件
4. 随着越来越多写操作,磁盘上积累的文件也越来越多,这些文件不可写且有序
5. 定时对文件进行合并操作(compaction),消除冗余数据,减少文件数量
以上过程用图表示如下:
LSM存储结构的写操作,只需更新内存,内存中的数据以块数据形式刷到磁盘,是顺序的IO操作,另外磁盘文件定期的合并操作,也将带来磁盘IO操作。
LSM存储结构的读操作,先从内存数据开始访问,如果在内存中访问不到,再顺序从一个个磁盘文件中查找,由于文件本身有序,并且定期的合并减少了磁盘文件个数,因而查找过程相对较快速。
合并操作是LSM实现中重要的一环,LevelDB、Cassandra中,使用基于层级的合并方式(Levelled compaction),生成第N层的时候,对N-1层的数据进行排序,使得每层内的数据文件之间都是有序的,但最高层除外,因为该层不断有数据文件产 生,因而只是数据文件内部按key有序。
除最高层外,其他层文件间数据有序,这也加速了读过程,因为一个key对应的value只存在一个文件中。假设总共有N层,每层最多K个数据文件,最差的情况下,读操作先遍历K个文件,再遍历每层,共需要K+(N-1)次读盘操作。
总结
LSM存储框架实现的思路较简单,其先在内存中保存数据,再定时刷到磁盘,实现顺序IO操作,通过定期合并文件减少数据冗余;文件有序,保证读取操作相对快速。
我们需要结合实际的业务场景选择合适的存储实现,不存在万金油式的通用存储框架。LSM适用于写多、读相对少(或较多读取最新写入的数据,该部分数据存在内存中,不需要磁盘IO操作)的业务场景。
?
Merkle哈希树校验方式为我们提供了一个很好的思路,它试图从校验信息获取及实际校验过程两个方面来改善上述问题。先说说什么是哈希树,以最简 单的二叉方式为例,如下图所示,设某文件共13个数据块,我们可以将其padding到16(2的整数次方)个块(注意,padding的空白块仅用于辅 助校验,而无需当作数据进行实际传输),每个块均对应一个SHA1校验值,然后再对它们进行反复的两两哈希,直到得出一个唯一的根哈希值为止(root hash, H0),这一计算过程便构成了一棵二元的Merkle哈希树,树中最底层的叶子节点(H15~H30)对应着数据块的实际哈希值,而那些内部节点 (H1~H14)我们则可以将其称为"路径哈希值",它们构成了实际块哈希值与根哈希值H0之间的"校验路径",比如,数据块8所对应的实际哈希值为 H23,则有:SHA1(((SHA1(SHA1(H23,H24),H12),H6),H1)应该等于H0。当然,我们也可以进一步采用n元哈希树来进 行上述校验过程,其过程是类似的。
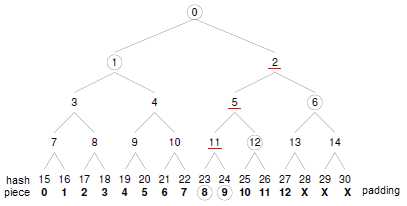
采用Merkle哈希树校验方式能够极大地减小.torrent文件的尺寸,这是因为,一旦采用这种方式来校验数据块,那么便没有必要 在.torrent文件中保存所有数据块的校验值了,其中仅需保存一个20字节的SHA1哈希值即可,即整个下载文件的根哈希值H0。想象一下一个3、 4GB的文件,其对应.torrent文件却只有100-200字节的样子?
通常设计是在各个日志服务器安装代理,通过代理收集数据。
数据总线的作用是能够形成数据变化通知通道,当集中存储的数据源中的数据发生变化时,能尽快通知对数据变化敏感的相关应用或者系统构建,使得他们能尽快捕获这种数据变化。
近乎实时的数据扩散,如linkedIn的databus。
sqoop
在集群硬件上抽象出一个功能独立的集群资源管理系统。把所有资源当成一个整体,并对其他所有计算任务提供统一的资源管理与调度框架和接口。计算任务按需申请资源、释放资源。
好处:
集群整体资源利用率高;
可增加数据共享能力;
支持多类型计算框架和多版本计算模型。
?
核心包含三部分:资源组织模型、调度策略、任务组织模型。
设计中,通常有节点管理器,负责收集本节点的资源使用情况,汇报给资源收集器。并对分配给本节点的任务放入容器中执行。通用调度器包括资源收集器、资源池、任务池、调度策略。资源收集器负责接收各个节点管理器提交的各节点使用情况,并更新到资源池中。资源池维护者本集群最新的可用资源。任务池存放着待执行的各种任务。调度策略负责把任务取出分配可用的资源去执行任务。调度策略通常有FIFO、公平调度、能力调度等。
?
数据局部性,包括节点局部性优先、机架局部性优先、全局局部性优先。
抢占式调度、非抢占式调度,前者用于优先级调度,后者用于公平调度。
资源分配粒度,包括全分或不分式、增量满足式、资源储备式。资源分配可能出现任务饿死、死锁问题。
资源隔离方面通常采用容器技术,LXC是一种轻量级的内核虚拟化技术,LXC依赖于Linux内核的cgroups子系统。
?
典型的案例包括Mesos和Yarn。
序列化与RPC主要用于网络中不同节点的进程直接的交互。
许多分布式系统都会在进程间进行信息交换。RPC就是这种技术。当A调用B进程时,A进程挂起,把参数传给B进程,B进程执行后把结果传给A进程。B进程结束,A进程继续执行。
数据序列化是为了保证高效的数据传输的,一般采用json或者xml格式,也有采用专门协议的。
常见的框架包括protocol buffer、thrift、avro。
消息队列主要用于大规模分布式系统中,用于解除相互之间的功能耦合,这样可以减轻各个子系统之间的依赖,使得各个子系统可以独立演进、维护或者重用。这里的消息指的是数据传输的基本单位,可以是简单的字符串,也可以是复杂的对象。
常见的框架有ActiveMQ、ZeroMQ、RabiitMQ、Kafka等。
Gossip协议。应用于cassandra、bittorrent、s3等。还可以用于维护贮备数据的最终一致性以及负载均衡等领域。
标签:
原文地址:http://www.cnblogs.com/chaoren399/p/4684658.html