标签:
毕竟XPath 可以比较迅速的从格式化的html查找解析相应的元素。


比较正规的网站布局,可以通过 chrome 的调试器 直接复制XPATH 路径。如图:
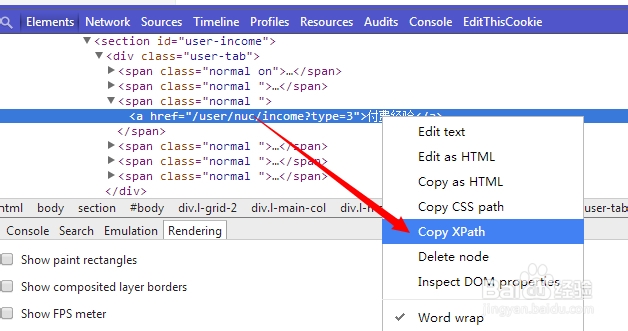
但是呢这种方法可能实现不了效果,得不到正确搜寻的值集合。
如何通过xpath 来查找一个 指定 class=‘xxx‘的元素的内容呢。
DocumentNode.SelectNodes("//div[@class=‘mainArea‘]/ul/li");
大家可以 通过 如此:
//div[@class=‘mainArea‘]的意思是:从根部(//)查找 class值为 mainArea的Node.
所以,那么就很简单了 //某元素[@class=‘CLASS值‘]
大家可以按照这个公式来查找 class的元素了。
剩下的 /ul/li 表示的是,继续查找 class=‘mainArea‘的div包括的ul元素下面的li 节点集合。
上面只是一种情况。大家可以查看 W3C 的 XPATH课
标签:
原文地址:http://my.oschina.net/airship/blog/485331