标签:style blog http 数据 width 2014
马尔科夫链(Markov chain)是一个具有马氏性的随机过程,其时间和状态参数都是离散的。马尔科夫链可用于描述系统在状态空间中的各种状态之间的转移情况,其中下一个状态仅依赖于当前状态。因为系统是随机变化的,所以不可能百分百预测出未来某个时刻的系统状态,但是我们可以预测出未来时刻系统处在某个状态的概率。 下面我们从实际生活中的天气预测问题入手解析马尔科夫链。现将天气的状态粗分为三种:1-雨雪天气、2-多云、3-天晴。假设明天的天气情况仅和今天的天气有关,根据大量的气象数据,我们统计出了今明两天之间的天气变化规律,如图1中的表格所示。天气状态变化对应的概率图模型为图1(b),其中状态值之间的边的权值表示转移概率,且每个状态的所有指出去的边的权值之和为1。如果今天为雨天,那么明天下雨的概率为0.4;如果今天为多云,明天出现多云天气的概率为0.6;如果今天为晴天,明天最有可能出现的天气依然是晴天,其概率为0.8。基于今天的天气状况和明天可能出现的天气状况,我们可以估算一个星期后的各种天气状况对应的概率。根据该实例,我们可知运用马尔科夫模型预测未来天气状况需要几个要素:1)当前的天气(初始状态);2)连续两天的天气之间转变模式(转移概率)。 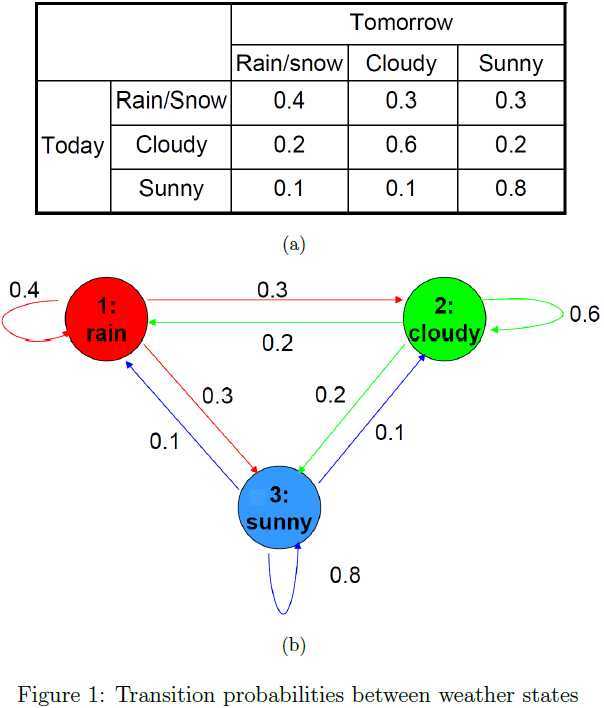
我们进一步用数学语言对马尔科夫链相应的知识点进行抽象和概括。马尔科夫链是由随机变量组成的序列,每个随机变量可能的值组成该马尔科夫链的状态空间\(\mathcal{S}\),且该序列满足马氏性,马氏性的数学表述如下: \begin{equation} P(X_{t+1}=x|X_1=x_1,X_2=x_2,\cdots,X_t=x_t)=P(X_{t+1}=x|X_t=x_t) \end{equation} 其中条件概率\(a_{ij}(t)=P(X_{t+1}=j|X_t=i)\)的含义为随机游动的质点在时刻\(t\)处于状态\(i\)的前提下,下一步转移到状态\(j\)的概率。当\(a_{ij}(t)\)与时刻\(n\)无关时,马尔科夫链具有平稳转移概率,下面我们只讨论这种情况。设\(A\)为转移概率组成的矩阵,且状态空间\(\mathcal{S}=\{1,2,\cdots,N\}\),则状态转移矩阵\(A\)的形式如下: \begin{equation} A=\left[\begin{array}{cccc} a_{11}& a_{12} &\cdots &a_{1N}\\ a_{21}& a_{22} &\cdots &a_{2N}\\ \vdots & \vdots &\ddots&\vdots\\ a_{N1}& a_{N2} &\cdots &a_{NN} \end{array} \right] \end{equation} 其中转移概率具有如下性质: \begin{equation} \begin{cases} a_{i,j}\geq 0, &i,j\in\mathcal{S}\\ \sum_{j\in\mathcal{S}}a_{ij}=1, &i,j\in\mathcal{S} \end{cases} \end{equation} 由定义可知,从时刻0到\(n\)的马尔科夫链状态序列对应的概率为: \begin{equation} \begin{array}{ll} &P(X_0=x_0,X_1=x_1,\cdots,X_t=x_t)\\ =&P(X_t=x_t|X_0=x_0,X_1=x_1,\cdots,X_{t-1}=x_{t-1})\\ & \cdot P(X_0=x_0,X_1=x_1,\cdots,X_{t-1}=x_{t-1})\\ =&P(X_t=x_t|X_{t-1}=x_{t-1})P(X_0=x_0,X_1=x_1,\cdots,X_{t-1}=x_{t-1})\\ =& \cdots\\ =&P(X_0=x_0)\prod_{i=0}^{t-1}P(X_{i+1}=x_{i+1}|X_i=x_i)\\ =&\pi_{x_0}\prod_{i=0}^{t-1}a_{x_ix_{i+1}} \end{array} \end{equation} 其中\(\pi_i\)表示初始状态为\(i\)的概率。如果今天是晴天,那么后面一个星期的天气状况观察序列\(O\)是"sun-sun-rain-rain-sun-cloudy-sun"的概率是多大呢?在前面给出的天气变化模型中,天气状态有三种\(s1\)(雨雪)、\(s2\)(多云)和\(s3\)(晴),根据这个公式,我们可以计算出对应的概率值: \begin{equation} \begin{array}{rl} P(O|model)=&P(s3,s3,s3,s1,s1,s3,s2,s3|model)\\ =&P(s3)P(s3|s3)P(s3|s3)P(s1|s3)\\ &\cdot P(s1|s1)P(s3|s1)P(s2|s3)P(s3|s2)\\ =&P(s3)a_{33}a_{33}a_{13}a_{11}a_{31}a_{23}a_{32}\\ =&1\cdot 0.8\cdot 0.8\cdot 0.1\cdot 0.4\cdot 0.3\cdot 0.1\cdot 0.2\\ =&1.536\times 10^{-4} \end{array} \end{equation} 如图2所示,如何求解随机游动的质点在时刻\(t\)处于状态\(s\in\mathcal{S}\)的概率\(P(X_t=s)\)呢? 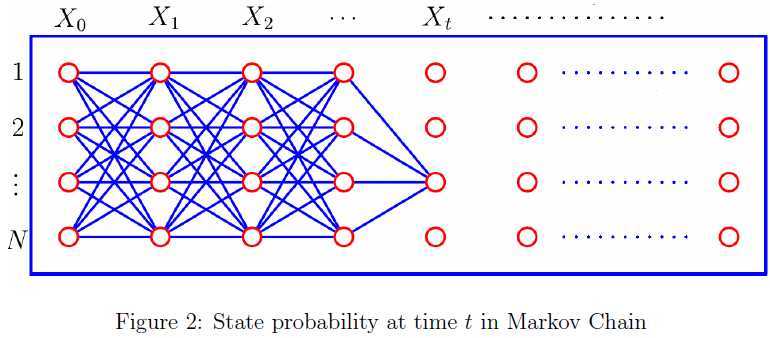
上述问题涉及到马尔科夫链的\(n\)步转移概率,表示随机移动的质点在两个前后相差\(n\)个时刻的状态值分别为\(i\)和\(j\)的概率,数学描述形式如下: \begin{equation} a_{ij}^{(n)}=P(X_{m+n}=j|X_m=i), i,j\in\mathcal{S},m\geq 0,n\geq 1 \end{equation} 则\(n\)步状态转移矩阵\(A^{(n)}\)的形式如下: \begin{equation} A^{(n)}=\left[\begin{array}{cccc} a_{11}^{(n)}& a_{12}^{(n)} &\cdots &a_{1N}^{(n)}\\ a_{21}^{(n)}& a_{22}^{(n)} &\cdots &a_{2N}^{(n)}\\ \vdots & \vdots &\ddots&\vdots\\ a_{N1}^{(n)}& a_{N2}^{(n)} &\cdots &a_{NN}^{(n)} \end{array} \right] \end{equation} 其中\(n\)步转移概率具有如下性质: \begin{equation} \begin{cases} a_{i,j}^{(n)}\geq 0, &i,j\in\mathcal{S}\\ \sum_{j\in\mathcal{S}}a_{ij}^{(n)}=1, &i,j\in\mathcal{S}\\ a_{i,j}^{(n)}=\sum_{k=1}^Na_{i,k}^{(l)}a_{k,j}^{(n-l)}\\ A^{(n)}=AA^{(n-1)} \end{cases} \end{equation} 根据全概率公式及马氏性,可证明第三条性质: \begin{equation} \begin{array}{rl} a_{i,j}^{(n)}&=P(X_{m+n}=j|X_m=i)=\frac{P(X_m=i,X_{m+n}=j)}{P(X_m=i)}\\ &=\sum_{k=1}^N\frac{P(X_m=i,X_{m+l}=k,X_{m+n}=j)}{P(X_m=i,X_{m+l}=k)}\cdot \frac{P(X_m=i,X_{m+l}=k)}{P(X_m=i)}\\ &=\sum_{k=1}^NP(X_{m+n}=j|X_{m+l}=k)P(X_{m+l}=k|X_m=i)\\ &=\sum_{k=1}^Na_{i,k}^{(l)}a_{k,j}^{(n-l)} \end{array} \end{equation} 求出了\(n\)步转移概率矩阵后,求某个状态在特定时刻出现的概率\(P(X_t=s)\)也就迎刃而解了 \begin{equation} P(X_t=s)=\sum_{j=1}^NP(X_0=j)a_{js}^{(n)} \end{equation} 计算\(A^{(n)}\)需要完成\(n-1\)个\(N\times N\)的矩阵相乘,计算\(P(X_t=s)\)需要两个\(N\)维向量相乘,因此最终计算\(P(X_t=s)\)的时间为复杂度\(O(tN^2)\),空间复杂度为\(O(N^2)\)。 假设现有\(L\)条马尔可夫序列\(\{X^1,X^2,\cdots X^L\}\),如何基于这些训练数据学习一个最合理的Markov模型呢?我们采用最大似然估计的方法估计Markov模型的最优参数。假设训练数据之间相互独立,则整个训练集上的似然函数的对数形式如下: \begin{equation} \begin{array}{rl} &L(A,\pi)\\ =&\log P(X^1,X^2,\cdots X^L)\\ =&\sum_{s=1}^L\log P(X^s)\\ =&\sum_{s=1}^L\log\pi_{x_0^s}+\sum_{t=1}^{T^s}\log a_{x^s_{t-1}x_t^s}\\ =&\sum_{s=1}^L\sum_{i=1}^N1\{x^s_0=i\}\log \pi_i\\ \quad &+\sum_{s=1}^L\sum_{i=1}^N\sum_{j=1}^N\sum_{t=1}^{T^s}1\{x^s_{t-1}=i,x_t^s=j\}\log a_{ij} \end{array} \end{equation} 其中各符号的上标\(s\)表示该符号与第\(s\)条训练数据\(X^s\)有关。又转移概率\(a_{ij}\)和初始概率必须满足约束条件 \begin{equation} \begin{cases} \sum_{i=1}^N\pi_i=1\\ \sum_{j=1}^Na_{ij}=1 \end{cases} \end{equation} 我们引入Lagrange乘子法求得使上述似然函数最大且满足约束条件的参数,构造的Lagrange函数如下: \begin{equation} \begin{array}{rl} \mathcal{L}(A,\pi,\alpha,\beta)=L(A,\pi)+\beta(1-\sum_{i=1}^N\pi_i)+\sum_{i=1}^N\alpha_i(1-\sum_{j=1}^Na_{ij}) \end{array} \end{equation} 用Lagrange函数分别对参数\(a_{ij}\)和\(\alpha_i\)求偏导 \begin{equation} \frac{\partial\mathcal{L}(A,\pi,\alpha,\beta)}{\partial a_{ij}}=\frac{1}{a_{ij}}\sum_{s=1}^L\sum_{t=1}^{T^s}1\{x^s_{t-1}=i,x_t^s=j\}-\alpha_i=0 \end{equation} \begin{equation} \frac{\partial\mathcal{L}(A,\pi,\alpha,\beta)}{\partial \alpha_{i}}=1-\sum_{j=1}^Na_{ij}=0 \end{equation} 结合上面两个等式,可得 \begin{equation} a_{ij}=\frac{\sum_{s=1}^L\sum_{t=1}^{T^s}1\{x^s_{t-1}=i,x_t^s=j\}}{\sum_{s=1}^L\sum_{t=1}^{T^s}1\{x^s_{t-1}=i\}} \end{equation} 用Lagrange函数分别对参数\(\pi_{i}\)和\(\beta\)求偏导 \begin{equation} \frac{\partial\mathcal{L}(A,\pi,\alpha,\beta)}{\partial \pi_{i}}=\frac{\sum_{s=1}^L1\{x_0^s=i\}}{\pi_{i}}-\beta=0 \end{equation} \begin{equation} \frac{\partial\mathcal{L}(A,\pi,\alpha,\beta)}{\partial \beta}=1-\sum_{i=1}^N\pi_i=0 \end{equation} 结合上面两个等式,可得 \begin{equation} \pi_{i}=\frac{\sum_{s=1}^L1\{x^s_{0}=i\}}{L} \end{equation} 根据上面的参数学习规则,很容易看出来这些参数的学习都是基于统计的,\(a_{ij}\)等于所有从状态\(i\)跳转到状态\(j\)的次数与所有状态为\(i\)的比值,而\(\pi_i\)则为\(L\)条训练数据中以状态\(i\)开始的比率。
在马尔可夫链中,状态是直接可见的。可是,在现实世界中,我们观察到的情况难免被噪声或错误干扰,使得"What you see is the truth"不再是有效的假设。某种现象的背后必然存在与实际相符的内在因素,也许这些内在因素还未被揭示出来,但由内在因素驱动的外部现象往往可以作为研究内在因素的线索,这也就是隐马尔可夫模型(Hidden Markov Model,HMM)的内在哲理。在HMM中,状态是不可见的,但依赖于状态的输出值是可见的;每个状态在所有可能的输出上都有一个概率分布,由HMM模型产生的输出序列为相应的状态序列提供了部分信息[1]。 我们结合图3所示的瓷缸问题具体描述HMM的思想。假设有\(N\)个瓷缸,\(M\)种不同颜色的球随机分布在瓷缸中。实验人员根据某种随机过程选择一个初始的瓷缸,从该瓷缸随机取出一个球并记录下其颜色,然后将球放回原瓷缸;接着,实验人员根据与当前选择的瓷缸相关的随机选择过程选择一个新的瓷缸,记录球的颜色后放回原瓷缸;不断重复该过程,最后得到了一个有限的颜色观测序列。我们想要基于这些已知的颜色序列运用HMM建模数学模型,那么HMM的状态对应特定的瓷缸,取出的球的颜色则对于该状态对应的输出值。HMM在具有时序性质的模式识别中有着广泛的应用,包括语音识别、手写体识别、手势识别和基因序列分析等。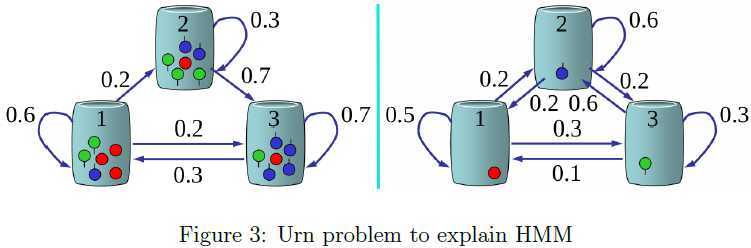
HMM可以被视为混合模型(mix model)的推广,因为HMM中的隐含状态间存在一定的上下文关系;而在Gaussian Mixture Model(GMM)等混合模型中,也是由多个隐含状态支配所有观测值,只是其中的隐含状态彼此间是独立的。因此,HMM中存在两个随机过程,一是隐含状态间随机跳转且具有马氏性,二是隐含状态产生的输出值也具有随机性。与这两个随机过程相关联的所有参数组成了HMM的参数,如图4所示,\(x\)表示隐含状态,各状态间的转移概率(transition probabilities)为\(a\),每个状态值对应的输出变量\(o\)取值为\(y\)的输出概率(output probabilities)为\(b\)。 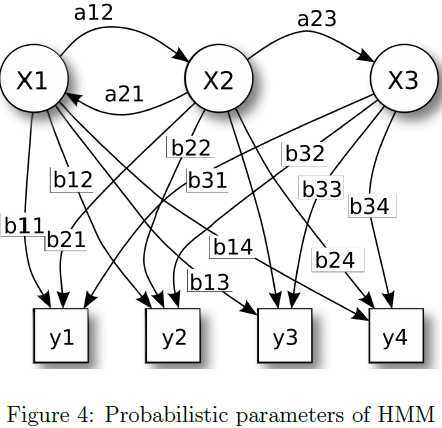
HMM的一般性结构如图5所示,其中每个椭圆表示随机变量,\(x(t)\)为\(t\)时刻的隐含状态,\(o(t)\)为表示\(t\)时刻的观察值的随机变量,箭头表示条件依赖性。从图示可知,\(x(t)\)仅依赖于\(x(t-1)\),\(o(t)\)仅依赖于\(x(t)\)。在标准的HMM中,状态空间是离散的,但观测变量既可以是离散的变量也可以是服从高斯分布等连续型变量。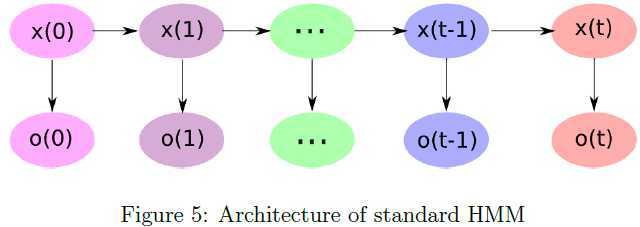
接下来,我们对HMM进行形式化描述。HMM的模型参数为 \begin{equation} \lambda=(A\in\mathbb{R}^{N\times N},B\in\mathbb{R}^{N\times M},\pi\in\mathbb{R}^{1\times N}) \end{equation} 参数的具体说明如下:
围绕着HMM有三个基本问题,这也是HMM在现实应用中发挥作用的关键性问题[3]。
下面,我们就对这三个关键问题逐个击破。
给定模型参数\(\lambda\)和长度为\(T\)的观测序列\(O=o_0o_1\cdots o_{T-1}\),求观测序列对应的概率值: \begin{equation} P(O|\lambda)=\sum_XP(X,O|\lambda)=\sum_XP(O|X,\lambda)P(X|\lambda) \end{equation} 其中\(X=x_0x_1\cdots x_{T-1}\)为观测序列对应的未知的状态序列,且有 \begin{equation} P(O|X,\lambda)=\prod_{t=0}^{T-1}P(o_t|x_t)=\prod_{t=0}^{T-1}b_{x_t}(o_t) \end{equation} \begin{equation} P(X|\lambda)=P(x_0)\prod_{t=1}^{T-1}P(x_t|x_{t-1})=\pi_{x_0}\prod_{t=1}^{T-1}a_{x_{t-1}x_t} \end{equation} 解决上述问题的最简单的方法就是穷举法,时间复杂度为\(O(TN^T)\)。穷举法中存在很多重复计算,更为有效的是采用前向或后向的动态规划算法,这里讨论前向和后向两种动态规划的策略。 假设\(t\)时刻的状态\(x_t=j\)且已知的观察序列为\(o_0o_2\cdots o_t\)的概率为: \begin{equation} \begin{array}{rl} \alpha_t(j)&=P(o_0o_2\cdots o_t,x_t=j)\\ &=\sum_{i=1}^NP(o_0o_2\cdots o_t,x_{t-1}=i,x_t=j)\\ &=\sum_{i=1}^NP(o_t,x_t=j|o_0\cdots o_{t-1},x_{t-1}=i)P(o_0\cdots o_{t-1},x_{t-1}=i)\\ &=\sum_{i=1}^NP(o_0\cdots o_{t-1},x_{t-1}=i)P(x_t=j|x_{t-1}=i)P(o_t|x_t=j)\\ &=\sum_{i=1}^N\alpha_{t-1}(i)a_{ij}b_j(o_t) \end{array} \end{equation} 由上式可知,只要计算出所有的\(\{\alpha_{t-1}(i)|i=1\cdots N\}\),就能算出\(\alpha_t(j)\),所以称之为前向算法(forward algorithm)。那么在初始时刻对应的\(\alpha_0(i)\)为 \begin{equation} \alpha_0(i)=\pi_ib_i(o_0),1\leq i\leq N \end{equation} 根据前向算法的推理规则不断计算,最后合并\(T-1\)时刻的所有结果即可得到观测序列的概率: \begin{equation} P(O|\lambda)=\sum_{i=1}^N\alpha_{T-1}(i) \end{equation} 对应的算法描述参见1,算法时间复杂读为\(O(TN^2)\),空间复杂度为\(O(N)\)。
假设在\(t\)时刻的状态\(x_t=j\)的前提下,\(t+1\)至\(T-1\)的时间段内对应的观察序列为\(o_0o_2\cdots o_t\)的概率为: \begin{equation} \begin{array}{rl} \beta_t(i)&=P(o_{t+1}\cdots o_{T-1}|x_t=i)\\ &=\sum_{j=1}^NP(o_{t+1}\cdots o_{T-1},x_{t+1}=j|x_t=i)\\ &=\sum_{j=1}^NP(x_{t+1}=j|x_t=i)P(o_{t+1}|x_{t+1}=j)P(o_{t+2}\cdots o_{T-1}|x_{t+1}=j)\\ &=\sum_{j=1}^N\beta_{t+1}(j)a_{ij}b_j(o_{t+1}) \end{array} \end{equation} 由上式可知,要要计算出\(\beta_t(i)\),必须先算出所有的\(\{\beta_{t+1}(j)|j=1\cdots N\}\),所以称之为后向算法(backward algorithm)。在初始时刻对应的\(\beta_{T-1}(j)\)都为\(1\)。根据后向算法的推理规则不断计算,最后合并\(0\)时刻的所有结果即可得到观测序列的概率: \begin{equation} \begin{array}{rl} P(O|\lambda)&=\sum_{i=1}^NP(o_0\cdots o_{T-1},x_0=i)\\ &=\sum_{i=1}^NP(o_1,\cdots o_{T-1}|x_0=i,o_0)P(o_0|x_0=i)P(x_0=i)\\ &=\sum_{i=1}^NP(o_1,\cdots o_{T-1}|x_0=i)P(o_0|x_0=i)P(x_0=i)\\ &=\sum_{i=1}^N\beta_0(i)b_i(o_0)\pi_i \end{array} \end{equation} 对应的算法描述参加2,算法时间复杂读为\(O(TN^2)\),空间复杂度为\(O(N)\)。 
给定模型参数\(\lambda\)和长度为\(T\)的观测序列\(O=o_0o_1\cdots o_{T-1}\),求最优的状态序列\(X^\star=x_0x_1\cdots x_{T-1}\): \begin{equation} X^\star=\underset{X}{arg\max}P(O,X|\lambda)=\underset{X}{arg\max}P(O|X,\lambda)P(X|\lambda) \end{equation} 基于动态规划的Viterbi算法[2]可用于寻找一条最优的隐含状态序列。假设已知的前\(t\)个观测值有多条以状态值\(i\)收尾的状态序列,这些状态序列与观测序列最大的联合概率为 \begin{equation} \delta_t(i)=\underset{x_0x_1\cdots x_{t-1}}{\max}P(x_0x_1\cdots x_{t-1},x_t=i,o_0o_1\cdots o_t) \end{equation} 进一步推理,可知前\(t+1\)个观察值对应的状态序列以\(j\)收尾的最大概率为 \begin{equation} \delta_{t+1}(j)=b_j(o_{t+1})\underset{1\leq i\leq N}{\max}\delta_t(i)a_{ij} \end{equation} 根据上式不断向前计算\(\delta_{t}(j)\)直至最后时刻\(T-1\),此时可知最优状态序列\(X^\star\)对应的概率为 \begin{equation} P(O,X^\star|\lambda)=\underset{1\leq i\leq N}{\max}\delta_{T-1}(i) \end{equation} 那么在\(T-1\)时刻对应的最优状态\(x^\star_{T-1}\)为 \begin{equation} x^\star_{T-1}=\underset{1\leq i\leq N}{arg\max}\delta_{T-1}(i) \end{equation} 假设我们已经知道最优状态序列在\(t+1\)至\(T-1\)时时间段内对应局部状态序列,且\(t+1\)时刻的状态值为\(x_{t+1}=j\),那么\(t\)时刻的状态\(x_t\)为何值时为最优呢?由于\(x_{t+1}\cdots x_{T-1}\)均已确定,意味着最优状态序列从\(t+1\)时刻开始的状态转移概率和输出概率对剩下的各状态变量而言是常数了,又\(P(X,O)\)可通过初始状态概率及一系列的状态转移概率和输出概率相乘得到,则 \begin{equation} \begin{array}{rl} &\underset{X}{\max} P(O,X|\lambda)\\ =&\underset{X}{\max} P(O|X,\lambda)P(X|\lambda)\\ =&\underset{X}{\max} \pi_{x_0}b_{x_0}(o_0)\prod_{t‘=1}^{T-1}a_{x_{t‘-1}x_{t‘}}b_{x_{t‘}}(o_{t‘})\\ =&\underset{X}{\max} \pi_{x_0}b_{x_0}(o_0)(\prod_{t‘=1}^{t}a_{x_{t‘-1}x_{t‘}}b_{x_{t‘}}(o_{t‘}))(a_{x_{t}x_{t+1}}b_{x_{t+1}}(o_{t+1}))\\ &\quad \cdot(\prod_{t‘=t+2}^{T-1}a_{x_{t‘-1}x_{t‘}}b_{x_{t‘}}(o_{t‘}))\\ =&\underset{{x_0\cdots x_t}}{\max}P(o_0\cdots o_t,x_0\cdots x_t)a_{x_{t}x_{t+1}}\\ &\quad\cdot \underbrace{b_{x_{t+1}}(o_{t+1})\prod_{t‘=t+2}^{T-1}a_{x_{t‘-1}x_{t‘}}b_{x_{t‘}(o_{t‘})}}_{constant}\\ =&\underset{1\leq i\leq N}{\max}\delta_t(i)a_{ij}\cdot {constant} \end{array} \end{equation} 由上式可知,当确定\(t+1\)及以后所有时刻的局部最优状态序列后,\(t\)时刻的最优状态值为 \begin{equation} x_t^\star=\Psi_{t+1}(j)=\underset{1\leq i\leq N}{arg\max}\delta_t(i)a_{ij}=\underset{1\leq i\leq N}{arg\max}\delta_t(i)a_{ij}b_{x_{t+1}}(o_{t+1}) \end{equation} 根据上述分析,在遍历完整个观测序列后,\(\Psi\)记录下的状态间的连接关系如图6所示。在Viterbi算法计算过程中,关键是要记录所有时间段内的状态链连接关系\(\{\Psi_t(j)|t=1\cdots T-1,j=1\cdots N\}\)即可,而局部路径对应的最大概率\(\delta_t(i)\)只需要保存前一个时刻和当前时刻的即可。Viterbi算法对应的算法描述见3,时间复杂度为\(O(TN^2)\),空间复杂度为\(O(TN)\)。 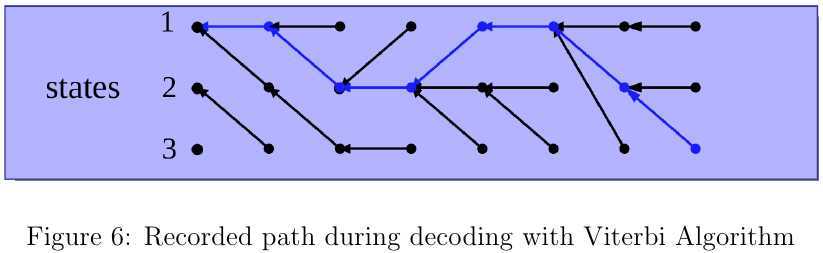

给定观测序列的集合\(\mathcal{O}=\{O^1,O^2,\cdots,O^L|O^s=o_0^s\cdots o^s_{T^s}\}\),HMM的模型参数\(\lambda=\{A,B,\pi\}\)为何值时才能是观测序列集合\(\mathcal{O}\)出现的概率最大?接下来,我们基于前面的前向算法、后向算法,用Lagrange乘子处理参数的约束条件,最后用EM(Expection Maximization)算法的思想完成模型的训练问题[4]。 根据前面知识,观察序列和隐含状态序列的联合概率计算形式如下: \begin{equation} P(O,X|\lambda)=\pi_{x_0}\left(\prod_{t=0}^{T-1}a_{x_{t}x_{t+1}}\right)\left(\prod_{t=0}^{T}b_{x_t}(o_t)\right) \end{equation} EM算法的基本思想是利用Jasen不等式为对数似然函数构造一个下界函数,E步骤中在固定模型参数的情况下通过使隐含状态序列满足特定的概率分布使得下界函数与真实目标函数相等,M步骤则在固定隐含状态序列概率分布情况下优化模型参数使得下界函数取得局部最优解;如此不断重复前面两个步骤,直至收敛为止。虽然EM算法只能找到局部最优解,幸运的是大多时候局部最优解已经可以满足我们的要求。假设训练集中的观测序列相互独立,则EM算法中的下界函数\(L(A,B,\pi)\)推导如下: \begin{equation} \begin{array}{rl} &\log P(O^1,O^2,\cdots,O^L|\lambda)\\ =&\log\prod_{l=1}^LP(O^l|\lambda)=\sum_{l=1}^L\log P(O^l|\lambda)\\ \geq&\sum_{l=1}^L\sum_{X^l}Q(X^l)\log\frac{P(O^l,X^l)}{Q(X^l)}\\ =&\sum_{l=1}^L\sum_{X^l}Q(X^l)\left[\log P(O^l,X^l)-\log Q(X^l)\right]\\ =&\sum_{l=1}^L\sum_{X^l}Q(X^l)\left[\log\pi_{x^l_0}+\sum_{t=0}^{T^l-1}\log a_{x^l_{t}x^l_{t+1}}\right.\\ \quad&+\left.\sum_{t=0}^{T^l} \log b_{x^l_t}(o^l_t)-\log Q(X^l)\right]\\ =&\sum_{l=1}^L\sum_{X^l}Q(X^l)\left[\sum_{i=1}^N1\{x_0^l=i\}\log\pi_{i}\right.\\ \quad&+\sum_{t=0}^{T^l-1}\sum_{i=1}^N\sum_{j=1}^N1\{x_t^l=i,x_{t+1}^l=j\}\log a_{ij}\\ \quad&+\left.\sum_{t=0}^{T^l} \sum_{i=1}^N\sum_{k=1}^M 1\{x_t^l=i,o_t^l=k\}\log b_{i}(j)-\log Q(X^l)\right]\\ =&L(A,B,\pi) \end{array} \end{equation} 在M步骤中需要求得使\(L(A,B,\pi)\)最大的参数,而且参数必须满足下列约束 \begin{equation} \begin{cases} \sum_{j=1}^Na_{ij}=1\\ \sum_{k=1}^Mb_i(k)=1\\ \sum_{i=1}^N\pi_i=1 \end{cases} \end{equation} 引入Lagrange乘子处理上述约束条件,构造如下的Lagrange函数 \begin{equation} \begin{array}{rl} \mathcal{L}(A,B,\pi)=&L(A,B,\pi)+\sum_{i=1}^N\theta_i(1-\sum_{j=1}^Na_{ij})\\ &+\sum_{i=1}^N\mu_i\left(1-\sum_{k=1}^Mb_i(k)\right)+\eta(1-\sum_{i=1}^N\pi_i) \end{array} \end{equation} 下面用最大似然的参数估计方法计算最优参数。Lagrange函数分别对状态转移概率\(a_{ij}\)和\(\theta_i\)求偏导并使其为0。 \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\partial a_{ij}}=\frac{1}{a_{ij}}\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l-1}1\{x_t^l=i,x_{t+1}^l\}=0 \end{equation} \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\partial \theta_i}=1-\sum_{j=1}^Na_{ij}=0 \end{equation} 结合上述两式,可得\(a_{ij}\)的参数求解如下 \begin{equation} a_{ij}=\frac{\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l-1}1\{x_t^l=i,x_{t+1}^l=j\}}{\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l-1}1\{x_t^l=i\}} \end{equation} 同理,Lagrange函数分别对输出概率\(b_i(k)\)和\(\mu_i\)求偏导并使其为0。 \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\partial b_i(k)}=\frac{1}{b_i(k)}\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l}1\{o_t^l=k,x^l_{t}=j\}-\mu_i=0 \end{equation} \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\partial \mu_i}=1-\sum_{k=1}^Mb_i(k)=0 \end{equation} 结合上述两式,可得输出概率\(b_i(k)\)的计算规则为 \begin{equation} b_i(k)=\frac{\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l}1\{o_t^l=k,x_{t}^l=i\}}{\sum_{l=1}^L\sum_{X^l}Q(X^l)\sum_{t=0}^{T^l}1\{x_t^l=i\}} \end{equation} Lagrange函数分别对初始状态概率\(\pi_i\)和\(\eta\)求偏导并使其为0。 \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\pi_i}=\frac{1}{\pi_i}\sum_{l=1}^L\sum_{X^l}Q(X^l)1\{x_0^l=i\}-\eta=0 \end{equation} \begin{equation} \frac{\partial \mathcal{L}(A,B,\pi)}{\eta}=1-\sum_{i=1}^N\pi_i=0 \end{equation} 结合上述两式,可得初始状态概率\(\pi_i\)的计算方式为 \begin{equation} \pi_i=\frac{\sum_{l=1}^L\sum_{X^l}Q(X^l)1\{x_0^l=i\}}{\sum_{l=1}^L\sum_{i=1}^N\sum_{X^l}Q(X^l)1\{x_0^l=i\}} \end{equation} 是否通过上述的参数计算规则,我们就能得到了最优参数呢?因为隐含状态序列\(X^l\)未知,所有以无法计算\(Q(X^l)\)。我们先来看两个基本问题,在已知模型参数\(\lambda\)和观测序列\(O\)的前提下,求任意单个时刻或连续两个时刻的隐含状态为特定值的概率
在E步骤中,我们有\(Q(X)=P(X|O;\lambda)\),则 \begin{equation} \begin{array}{rl} &\sum_XQ(X)\sum_{t=0}^{T-1}1\{x_t=i,x_{t+1}=j\}\\ =&\frac{1}{P(O)}\sum_X\sum_{t=0}^{T-1}1\{x_t=i,x_{t+1}=j\}P(O,X)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T-1}P(O,x_t=i,x_{t+1}=j)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T-1}\alpha_t(i)a_{ij}\beta_{t+1}(j)b_j(o_{t+1}) \end{array} \end{equation} \begin{equation} \begin{array}{rl} &\sum_XQ(X)\sum_{t=0}^{T-1}1\{x_t=i\}\\ =&\frac{1}{P(O)}\sum_X\sum_{t=0}^{T-1}1\{x_t=i\}P(O,X)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T-1}P(O,x_t=i)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T-1}\sum_{j=1}^NP(O,x_t=i,x_{t+1}=j)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T-1}\sum_{j=1}^N\alpha_t(i)a_{ij}\beta_{t+1}(j)b_{j}(o_{t+1}) \end{array} \end{equation} \begin{equation} \begin{array}{rl} &\sum_XQ(X)\sum_{t=0}^{T}1\{x_t=i,o_t=k\}\\ =&\frac{1}{P(O)}\sum_X\sum_{t=0}^{T}1\{x_t=i,o_t=k\}P(O,X)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T}1\{o_t=k\}P(O,x_t=i)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T}\sum_{j=1}^N1\{o_t=k\}P(O,x_{t}=i,x_{t+1}=j)\\ =&\frac{1}{P(O)}\sum_{t=0}^{T}\sum_{j=1}^N1\{o_t=k\}\alpha_{t}(i)a_{ij}\beta_{t+1}(j)b_{j}(o_{t+1}) \end{array} \end{equation} 将上述三式带入各参数更新规则中,令\(\gamma_t(i,j)=\alpha_t(i)a_{ij}\beta_{t+1}(j)b_j(o_{t+1})\),则 \begin{equation} a_{ij}=\frac{\sum_{l=1}^L\sum_{t=0}^{T^l-1}\gamma^l_t(i,j)}{\sum_{l=1}^L\sum_{t=0}^{T^l-1}\sum_{j=1}^N\gamma^l_t(i,j)} \end{equation} \begin{equation} b_{i}(k)=\frac{\sum_{l=1}^L\left(\sum_{t=0}^{T^l-1}\sum_{j=1}^N1\{o_t=k\}\gamma^l_t(i,j)+1\{o_{T^l}=k\}\alpha_{T^l}(i)\right)}{\sum_{l=1}^L\left(\sum_{t=0}^{T^l-1}\sum_{j=1}^N\gamma^l_t(i,j))+\alpha_{T^l}(i)\right)} \end{equation} \begin{equation} \pi_i=\frac{\sum_{l=1}^L\sum_{j=1}^N\gamma^l_0(i,j)}{\sum_{l=1}^L\sum_{i=1}^N\sum_{j=1}^N\gamma^l_0(i,j)} \end{equation}
前面的内容已经从理论上解决了HMM相关的问题,但是要实现HMM相关算法却有很多细节要处理,scaling就是其中之一。在解决前面的任何一个问题时,我们都要用到众多范围在\([0,1]\)之间的概率值的乘积,所以得到的结果很容易向下溢出。为了处理这中情况,在实现HMM算法时有必要引入scaling的技巧,使得计算机处理的中间结果不至于向下溢出,而且最终可以得到与原问题相同的解。对于联合概率\(P(O,X)\)的求解,可采用对数等价转换 \begin{equation} P(O,X)=\exp\left(\log\pi_{x_0}+\sum_{t=0}^{T-1}\log a_{x_tx_{t+1}}+\sum_{t=0}^T\log b_{x_t}(o_t)\right) \end{equation} Scaling技巧最主要是用在HMM的模型参数估计过程中,这里根据文献\cite{rabiner1989tutorial}中的scaling策略进行简单分析,最后给出HMM在实际的参数学习过程中的方法。假设对所有的\(\alpha_t(i)\)和\(\beta_t(i)\)都进行如下放缩 \begin{equation} \begin{array}{cc} &\hat{\alpha}_t(i)=\alpha_t(i)/c_t\\ &\hat{\beta}_t(i)=\beta_t(i)/c_t \end{array} \end{equation} 其中\(c_t=\sum_{i=1}^N\alpha_t(i)\)。前向算法和后向算法中的迭代公式变为如下形式: \begin{equation} \begin{array}{cc} &\alpha_t(j)=\sum_{i=1}^N\hat{\alpha}_{t-1}(i)a_{ij}b_j(o_t)\\ &\beta_t(i)=\sum_{j=1}^N\hat{\beta}_{t+1}(j)a_{ij}b_j(o_{t+1}) \end{array} \end{equation} 最终很容易得到 \begin{equation} \begin{array}{cc} &\hat{\alpha}_t(j)=\alpha_{t}(i)/(\prod_{t‘=1}^tc_{t‘})\\ &\hat{\beta}_{t+1}(j)=\beta_{t+1}(i)/(\prod_{t‘=t+1}^Tc_{t‘}) \end{array} \end{equation} 由于各变量放缩后对任意\(t\)都满足\(\sum_{i=1}^N\hat{\alpha}_t(i)=1\),则有 \begin{equation} \begin{array}{ll} &\sum_{i=1}^N\hat{\alpha}_T(i)=\sum_{i=1}^N\alpha_T(i)/\left(\prod_{t=1}^Tc_t\right)=P(O)/\left(\prod_{t=1}^Tc_t\right)=1\\ &\Longrightarrow \prod_{t=1}^Tc_t=P(O) \end{array} \end{equation} 经过scaling后,参赛更新中的\(\gamma_t(i,j)\)也相应得到了放缩 \begin{equation} \begin{array}{ll} \hat{\gamma}_t(i,j)&=\hat{\alpha}_t(i)a_{ij}\hat{\beta}_{t+1}(j)b_j(o_{t+1})\\ &=\alpha_t(i)a_{ij}\beta_{t+1}(j)b_j(o_{t+1})/\left(\prod_{t=1}^Tc_t\right)\\ &=\gamma_t(i,j)/\left(\prod_{t=1}^Tc_t\right)=\gamma_t(i,j)/P(O) \end{array} \end{equation} 如果用\(\hat{\gamma}_t(i,j)\)去学习HMM的最优参数,而且要求scaling前后是完全一致的,则有 \begin{equation} a_{ij}=\frac{\sum_{l=1}^LP(O^l)\sum_{t=0}^{T^l-1}\hat{\gamma}^l_t(i,j)}{\sum_{l=1}^LP(O^l)\sum_{t=0}^{T^l-1}\sum_{j=1}^N\hat{\gamma}^l_t(i,j)} \end{equation} \begin{equation} b_{i}(k)=\frac{\sum_{l=1}^LP(O^l)\left(\sum_{t=0}^{T^l-1}\sum_{j=1}^N1\{o_t=k\}\hat{\gamma}^l_t(i,j)+1\{o_{T^l}=k\}\alpha_{T^l}(i)\right)}{\sum_{l=1}^LP(O^l)\left(\sum_{t=0}^{T^l-1}\sum_{j=1}^N\hat{\gamma}^l_t(i,j))+\alpha_{T^l}(i)\right)} \end{equation} \begin{equation} \pi_i=\frac{\sum_{l=1}^LP(O^l)\sum_{j=1}^N\hat{\gamma}^l_0(i,j)}{\sum_{l=1}^LP(O^l)\sum_{i=1}^N\sum_{j=1}^N\hat{\gamma}^l_0(i,j)} \end{equation}
[1] Hidden markov model. http://en.wikipedia.org/wiki/Hidden_Markov_model.
[2] Viterbi algorithm. http://en.wikipedia.org/wiki/Viterbi_algorithm.
[3] Lawrence Rabiner. A tutorial on hidden markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2):257–286, 1989.
[4] Daniel Ramage. Hidden markov models fundamentals. Lecture Notes. http://cs229. stanford. edu/section/cs229-hmm. pdf, 2007.
Hidden Markov Model,布布扣,bubuko.com
标签:style blog http 数据 width 2014
原文地址:http://www.cnblogs.com/jeromeblog/p/3832751.html