标签:
MapRduce保证reducer的输入是按照key进行排过序的,原因和归并排序有关,在reducer接收到不同的mapper输出的有序数据后,需要再次进行排序,然后是分组排序,如果mapper输出的是有序数据,将减少reducer阶段排序的时间消耗.一般将排序以及Map的输出传输到Reduce的过程称为混洗(shuffle).Shuffle是MapReduce过程的核心,了解Shuffle非常有助于理解MapReduce的工作原理。如果你不知道MapReduce里的Shuffle是什么,那么请看下面这张图
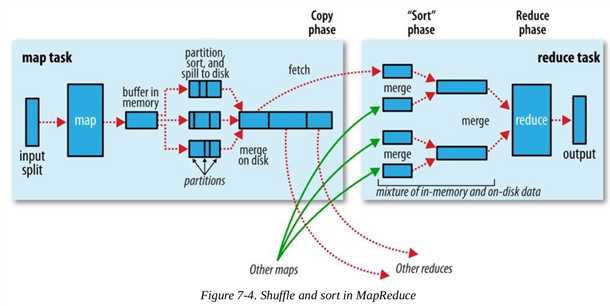
上图中明显分为两个大部分Map任务和Reduce任务,图中的红色虚线代表数据流的一个过程,下面分两部分进行说明:
MAP部分
每一个mapper都有一个circular buffer(环形缓存),环形缓冲区是一个先进先出的循环缓冲区,不用频繁的分配内存,而且在大多数情况下,内存的反复使用也使得我们能用更少的内存块做更多的事,默认情况下大小为100M(可以通过mapreduce.task.io.sort.mb来进行修改).Mapper的输出会首先写进这个缓存里面,当里面的内容达到一个阈值(mapreduce.map.sort.spill.percent,默认情况下为80%),一个后台线程就会开始向磁盘spill这些内容,同时Map将继续向该缓存区写内容.当缓存区写满时,Map被阻塞,直到spill过程完成才会被唤醒.Spills 将会循环写进 mapreduce.cluster.local.dir定义的目录下面,也就是说会产生多个spill磁盘文件.
在spill过程写进磁盘之前还会做一些事情,步骤如下:
(1) 首先线程会先把写的内容分成多个分组,这个和reducer的分组是一致的,partitioner的算法请参考我的另外一篇文章:hadoop之定制自己的Partitioner
(2) 针对每一个分组,线程会实现内存的排序,排序的过程请参考另外一篇文章: hadoop之定制自己的sort过程
(3) 如果存在combiner的话,combiner会在sort之后,在每一个分组进行执行,combiner的执行会导致写到磁盘的数据减少.
每一次环形缓存达到阈值,就会产生一个spill的文件,也就是说可能会产生很多个spill文件.在任务结束之前,这些文件会被合并为统一的带有分组和排好序的文件作为输出.其中mapreduce.task.io.sort.factor定义了一次合并的文件的最大个数,默认的个数为10.另外如果文件个数大于3的话,combiner会再次被调用.如果仅有2个或者更少的文件,没有必要调用combiner了.
Reduce部分
标签:
原文地址:http://www.cnblogs.com/wzyj/p/4693119.html