标签:
VJ
VJ算法是object detection中提出较早的方法了,将它归类于DF (decision forests 决策森林)方法的范畴。
References中的[1],提出了 VJ 算法来进行人脸识别:
采用的特征、分类器、算法的结构
1) 采用的特征为rectangle features,种类有3种: two-rectangle feature、three-rectangle feature、four-rectangle feature
论文原图如下:
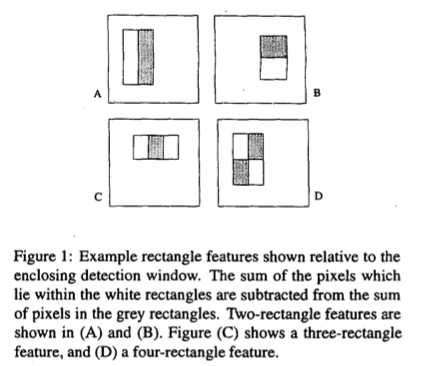
这三种特征都有一横一竖两种情况,且由于矩形的高宽可变,所以事实上,一张图里边的特征数量是非常多的。这几种特征怎么计算在图示里都有说明。
2) 分类器
原始版本的Adaboost是用来把弱分类器激发成强分类器来提升算法性能的。通过对Adaboost算法的改变,新算法可以从图像的大量特征中选取一个小集合的特征,并训练对应的分类器。
3) 算法的结构
算法的结构是由一个个由变种的Adaboost算法训练出来的分类器级联得到的。输入一个子图,如果它在途中的一个分类器的识别中判断为负,那么它就被认定不含目标(这里是人脸),不再接受后续的分类。像下面这样:
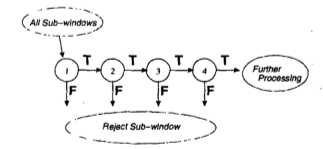
“瀑布结构”中的每一个阶段就是一个分类器。构造过程: 通过Adaboost训练,得到一个naive的分类器。然后,使用validation set 通过最小化 false negatives 来调整这个分类器的阀值。(降低分类器阀值的同时会提升成功检测的概率,但同时也会提升 false positive 的概率) 。循环往复,就得到了结构中的每一个分类器。
另外,在分类器的级联结构中,越靠前的分类器使用的特征越简单。算法利用前面较简单的分类器来筛选掉绝大多数不可能包含目标的子图,从而提高检测的速度。越往后的分类器由于需要负责更精细的甄别任务,使用的特征会更复杂,当然消耗的计算时间也会更多。另外,由于这个瀑布结构分类器群的筛选能力较强,在训练的过程中,越往后面的分类器能用于学习的数据越少,检测结果为“false positive”的概率也更高。
例:文章里级联结构的第一个分类器使用了两种特征。这两种特征的是由Adaboost算法的执行过程中选取的,意义也比较直观,详情请看下面的图示。

把每个分类器当成一个节点,这个级联结构相当于把n个节点用n-1条边连起来,就像退化的树,所以也说这种分类器的级联结构是决策树的弱化 (degenerate decision tree),将此方法归入decision forests的阵营中。
最后,由于训练的样本和实际测试的数据都是原始图片上的子图,不免会出现一些干扰。比如,针对同一个目标出现在多张子图的情况,论文中采取了计算覆盖的方法减小误差。
朴素的VJ算法只需要输入灰度图,就能进行快速的计算。论文实验表明,使用一些额外的信息能提升算法的性能,但是数据显示非常有限。在object detection的发展过程中,它是很早的一种算法,在难度比较大的现代数据库比如 INRIA、Caltech中的表现基本就是垫底的。不过由于这种算法的结构相对简单,直接,还是有学习的意义的。
References:
[1] A decision-theoretic generalization of on-line learning and an application to boosting. In Computational Learning Theory 1995
[2] Rapid Object Detection using a Boosted Cascade of Simple Features. Paul Viola, Michael Jones. In CVPR 2001
object detection--Decision Tree
标签:
原文地址:http://www.cnblogs.com/zhangzph/p/4695474.html