标签:
Spout数据源:Message queue 消息队列 必须使用
MQ、Db、文件
直接流数据源:MQ
从db只能读配置文件
Log文件增量数据:1、读出内容写入MQ,2、Storm处理
Spout读文件:学习用,其他无用
读文件:1、分布式应用无法读;2、spout开并发会重复读
Stream grouping 策略 只适用于多并发
stream grouping就是用来定义一个stream应该如果分配给Bolts上面的多个
Executors(多线程,并发度)
注:不是一个spout或bolt emit到多个bolt(广播方式)。
storm里面有6种类型的stream grouping。
单线程下均等同于All Grouping(得到全部的数据)
1.Shuffle Grouping
轮询,平均分配。随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同。
平均分配:

结果:

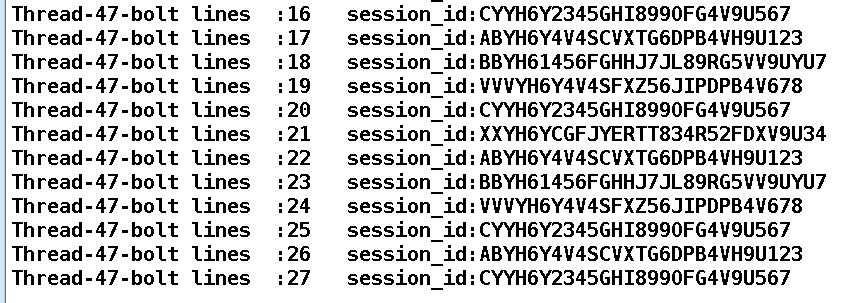
两个线程平均分配数据
2. Non Grouping: 无分组, 这种分组和Shuffle grouping是一样的效果,多线程下不平均分配。

结果
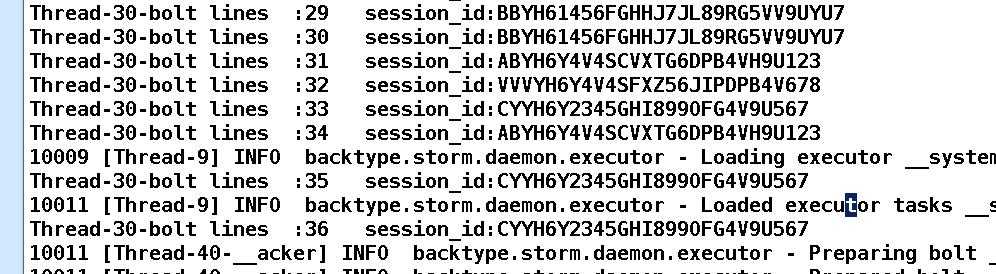
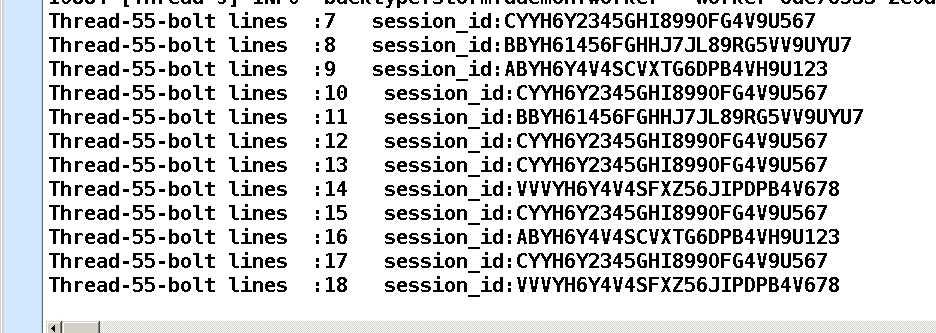
3. Fields Grouping:按Field分组,比如按word来分组, 具有同样word的tuple会被分到相同的Bolts, 而不同的word则会被分配到不同的Bolts。
作用:1、过滤,从源端(Spout或上一级Bolt)多输出Fields中选择某些Field
2、相同的tuple会分发给同一个Executer或task处理
典型场景:去重操作、Join
Join 需要两个源,数据源必须及时同步。否则容易出错

shuffleGrouping
=============================================a b c d
=============================================b c d e f
=============================================a d e f
Thread-16-count ------------------------ word=c; count=1
Thread-18-count ------------------------ word=a; count=1
Thread-18-count ------------------------ word=d; count=1
Thread-16-count ------------------------ word=d; count=1
Thread-16-count ------------------------ word=f; count=1
Thread-18-count ------------------------ word=e; count=1
Thread-16-count ------------------------ word=c; count=2
Thread-18-count ------------------------ word=d; count=2
Thread-18-count ------------------------ word=e; count=2
Thread-20-count ------------------------ word=b; count=1
Thread-20-count ------------------------ word=a; count=1
Thread-20-count ------------------------ word=b; count=2
Thread-20-count ------------------------ word=f; count=1
可以看出线程是无规律的
如18线程管理着d 16线程也管理着d 这样排序结果就有问题
Fields Grouping:
=============================================a b c d
=============================================b c d e f
=============================================a d e f
Thread-20-count ------------------------ word=a; count=1
Thread-20-count ------------------------ word=d; count=1
Thread-16-count ------------------------ word=b; count=1
Thread-16-count ------------------------ word=b; count=2
Thread-18-count ------------------------ word=c; count=1
Thread-16-count ------------------------ word=e; count=1
Thread-16-count ------------------------ word=e; count=2
Thread-20-count ------------------------ word=a; count=2
Thread-20-count ------------------------ word=d; count=2
Thread-18-count ------------------------ word=c; count=2
Thread-20-count ------------------------ word=d; count=3
Thread-18-count ------------------------ word=f; count=1
Thread-18-count ------------------------ word=f; count=2
各自线程所分到的word相同
16.b,e
18.c,f
20.a,d
即:具有同样word的tuple会被分到相同的Bolts,
4. All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到。

结果:
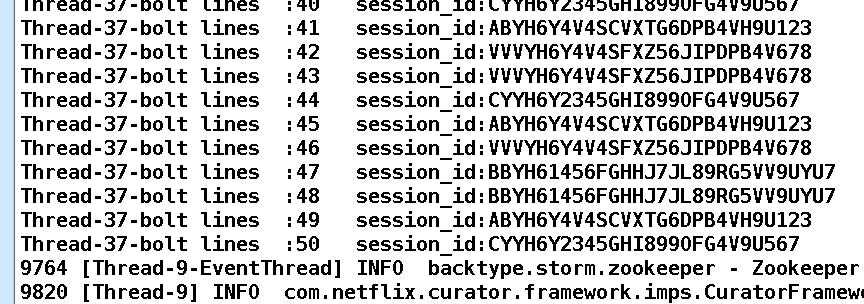
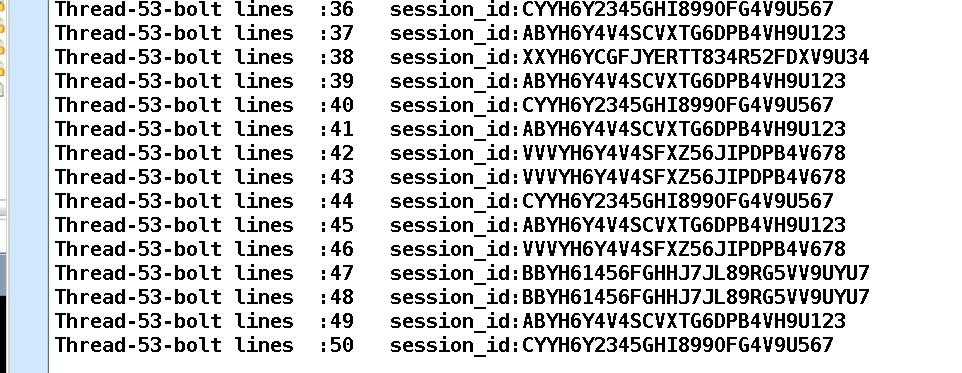
5. Global Grouping: 全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。适合场景:想象不到。
只分配到其中的一个task,其他的接收不到数据

只有一个线程接收到了tuple,其他的均无输出,线程最小的task接收到了
6. Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者决定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
并发度
场景分析:
单线程下:加减乘除,和任何处理类Operate,汇总
多线程下:
1、局部加减乘除
2、做处理类Operate,如split
3、持久化,如入DB
以WordCountTopology.java 为例讲解
思考题:如何计算:word总数和word个数 ?并且在高并发下完成
前者是总行数,后者是去重word个数
类似企业场景:计算网站PV和UV
并行度与并发度
读文件源的话开了两个线程读取文件,所以读取两份数据。
1.这样分布式源无法读取
2.spout开并发会重复读取

如果spout是消息队列的话,消费完数据就消费不到了,无论如何也不会得到重复的数据
而bolt的话,有6种group策略,使用Shuffle Grouping会使用轮询的方式,平均获取到数据.
一个spout到多个blot 这种方式就是广播方式
标签:
原文地址:http://www.cnblogs.com/thinkpad/p/4699601.html