标签:
将Adaboost和decision tree相结合,需要注意的地主是,训练时adaboost需要改变资料的权重,如何将有权重的资
料和decision tree相结合呢?方法很类似于前面讲过的bagging,通过采样资料来使资料获得不同的权重。

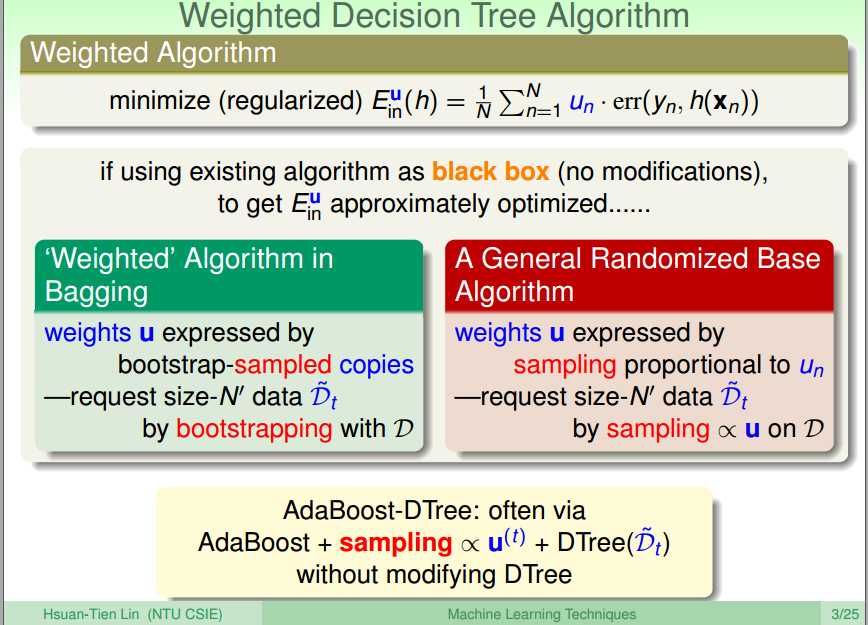
一棵完全的树的权值会无限大,可能出现过拟合。因此需要得到一棵弱分类的树,方法如下:

接下来比较深入的分析adaboost。经过代换,出现了如下惊人的结果: 某个资料的权重正比于投票分数

联系到之前学习的SVM,发现了一个秘密:投票的分数就是某个点到分隔线的距离(margin)。分数越高越好,就意味着u越小越好。在Adaboost过
程中,如果u的和越来越小,意味着margin越来越大,证明adaboost效果越好。

接下来这段没有听懂:大概是通过errADA作为上界,将zero-one做的更好。

下面是证明通过adaboost确实能做的更好。中间是一系列推导就不说了,直接上下图。这个推导是从另一方面解释Adaboost:为g赋权重的过程,实
际上就是优化的过程。

从上面可以看出,adaboost的过程,实际上就是选择最优的h,选择最优的步长n,不断对其进行优化的过程。将其推广到任意的err function,
任意的h,就得出了一种类似adaboost的方法:GradientBoost。

接下来将其用于regression,非常的理论。最后找到得到h的方法:对x,y-s做regression。

那么如何得到步长呢?最后得出如下形式:对余数和g做regression

最后是这个算法的过程:

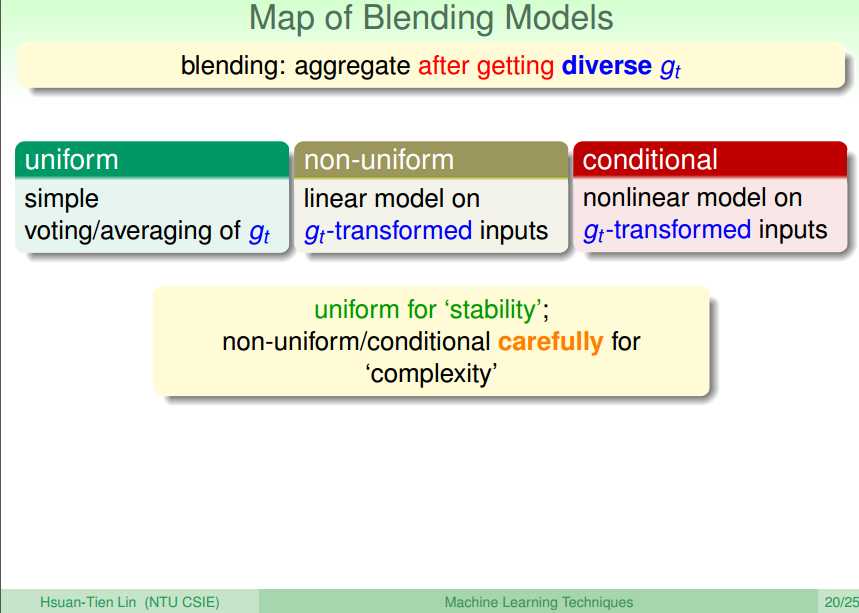
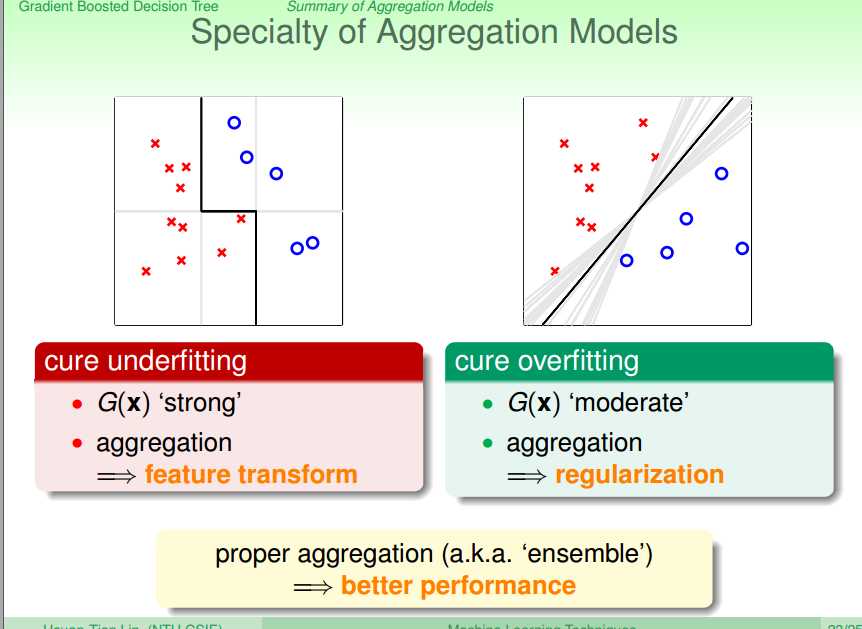
下面是对aggregate的一个总结。对于blending(已经得到各种g)
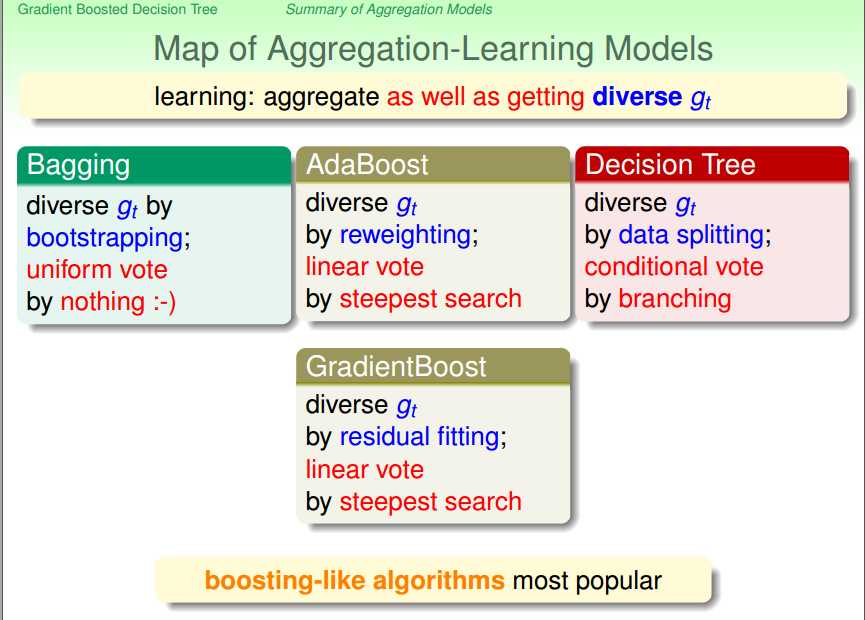
对于learning(需要学习得到g并将其进行组合):
将这些模型进行糅合:
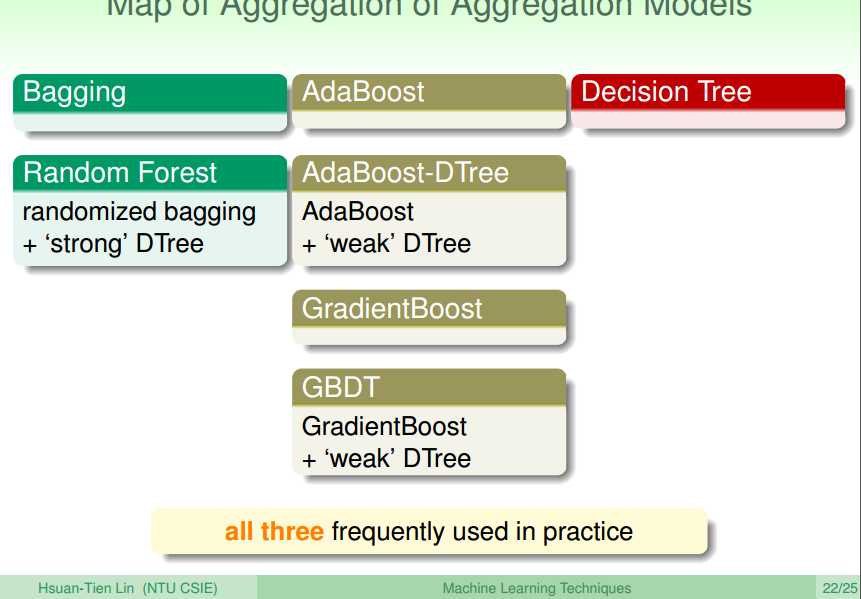
选择合适的aggregation模型:
Coursera台大机器学习技法课程笔记11-Gradient Boosted Decision Tree
标签:
原文地址:http://www.cnblogs.com/573177885qq/p/4699693.html