标签:
| Time Limit: 8000MS | Memory Limit: 65536K | |
| Total Submissions: 7598 | Accepted: 2191 | |
| Case Time Limit: 2000MS | Special Judge |
Description
John is a Chief Executive Officer at a privately owned medium size company. The owner of the company has decided to make his son Scott a manager in the company. John fears that the owner will ultimately give CEO position to Scott if he does well on his new manager position, so he decided to make Scott’s life as hard as possible by carefully selecting the team he is going to manage in the company.
John knows which pairs of his people work poorly in the same team. John introduced a hardness factor of a team — it is a number of pairs of people from this team who work poorly in the same team divided by the total number of people in the team. The larger is the hardness factor, the harder is this team to manage. John wants to find a group of people in the company that are hardest to manage and make it Scott’s team. Please, help him.
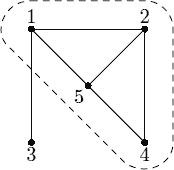
In the example on the picture the hardest team consists of people 1, 2, 4, and 5. Among 4 of them 5 pairs work poorly in the same team, thus hardness factor is equal to 5⁄4. If we add person number 3 to the team then hardness factor decreases to 6⁄5.
Input
The first line of the input file contains two integer numbers n and m (1 ≤ n ≤ 100, 0 ≤ m ≤ 1000). Here n is a total number of people in the company (people are numbered from 1 to n), and m is the number of pairs of people who work poorly in the same team. Next m lines describe those pairs with two integer numbers ai and bi (1 ≤ ai, bi ≤ n, ai ≠ bi) on a line. The order of people in a pair is arbitrary and no pair is listed twice.
Output
Write to the output file an integer number k (1 ≤ k ≤ n) — the number of people in the hardest team, followed by k lines listing people from this team in ascending order. If there are multiple teams with the same hardness factor then write any one.
Sample Input
sample input #1 5 6 1 5 5 4 4 2 2 5 1 2 3 1 sample input #2 4 0
Sample Output
sample output #1 4 1 2 4 5 sample output #2 1 1
Hint
Note, that in the last example any team has hardness factor of zero, and any non-empty list of people is a valid answer.
题意:
最大密度子图裸题。给出N和M表示有N个点和M条边。求出最大密度子图,并输出子图的节点。
参考 胡伯涛的论文 《最小割模型在信息学竞赛中的应用》
定义无向图G=(V,E)的密度D为该图的边数|E|与该图的点数|V|的比值。给出一个无向图,
具有最大密度的子图成为最大密度子图。
首先这是一个0-1分数规划问题,可以通过二分来解决。
要求的就是 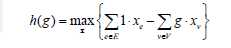
建图方法:
在原图点集V的基础上增加源s和汇t;将每条原无向边(u, v)替换为两条容量为1的有向边<u,v>和<v,u>;
增加连接源s到原图每个点v的有向边<s,v>,容量为U(U是一个足够大的数,保证非负);
增加连接原图每个点v到汇t的有向边<v,t>,容量为(U+2*g-dv)。(dv表示每个点的度数)
然后求最小割。
事实上度数dv不会超过总边数M,并且猜测g是非负的,所以令U = m,可以保证所有的容量都是非负的。
对应关系:h(g) = (U*n - c[s,t])/2 ,其中[s,t]为最小割。
最小割[S,T]对应的子图就是一个最优解。
这题要注意一下精度问题。
要注意的是:在无向图G中,任意两个具有不同密度的子图G1,G2,它们的密度差不小于1/n^2.
因此在无向图G中,有一个密度为D的子图G‘,且在无向图G中不存在一个密度超过D+1/n^2的子图,则G’为最大密度子图。
所以二分查找跳出的条件可以根据这个来设置。
1 #include <iostream> 2 #include <cstring> 3 #include <string> 4 #include <cstdio> 5 #include <algorithm> 6 #include <vector> 7 #include <cmath> 8 #include <queue> 9 using namespace std; 10 #define maxn 1505 11 const double inf = 0x3f3f3f3f; 12 const double eps = 1e-6; 13 struct Edge 14 { 15 int from, to; 16 double cap, flow; 17 Edge(int f, int t, double c, double fl) 18 { 19 from = f; to = t; cap = c; flow = fl; 20 } 21 }; 22 vector <Edge> edges; 23 vector <int> G[maxn]; 24 int vis[maxn], d[maxn], cur[maxn]; 25 int n, m, s, t; 26 double min(double a, double b) 27 { 28 return a<b?a:b; 29 } 30 void AddEdge(int from, int to, double cap) 31 { 32 edges.push_back(Edge(from, to, cap, 0)); 33 edges.push_back(Edge(to, from, 0, 0)); 34 m = edges.size(); 35 G[from].push_back(m-2); 36 G[to].push_back(m-1); 37 } 38 bool bfs() 39 { 40 memset(vis, 0, sizeof(vis)); 41 vis[s] = 1; 42 d[s] = 0; 43 queue <int> q; 44 q.push(s); 45 while(!q.empty()) 46 { 47 int u = q.front(); q.pop(); 48 for(int i = 0; i < G[u].size(); i++) 49 { 50 Edge &e = edges[G[u][i]]; 51 if(!vis[e.to] && e.cap > e.flow+eps) 52 { 53 vis[e.to] = 1; 54 d[e.to] = d[u] + 1; 55 q.push(e.to); 56 } 57 } 58 } 59 return vis[t]; 60 } 61 double dfs(int x, double a) 62 { 63 if(x == t || a == 0){ 64 return a; 65 } 66 double flow = 0, f; 67 for(int &i = cur[x]; i < G[x].size(); i++) 68 { 69 Edge &e = edges[G[x][i]]; 70 if(d[x] + 1 == d[e.to] && (f = dfs(e.to, min(a, e.cap - e.flow))) > 0) 71 { 72 e.flow += f; 73 edges[G[x][i]^1].flow -= f; 74 flow += f; 75 a -= f; 76 if(a == 0) break; 77 } 78 } 79 return flow; 80 } 81 double Maxflow() 82 { 83 double flow = 0; 84 while(bfs()) 85 { 86 memset(cur, 0, sizeof(cur)); 87 flow += dfs(s, inf); 88 } 89 return flow; 90 } 91 int N, M; 92 int u[1010], v[1010], du[1010]; 93 int main(){ 94 while(~scanf("%d%d", &N, &M)) 95 { 96 if(M == 0) {printf("1 \n1\n"); continue;} 97 s = 0; t = N+1; 98 memset(du, 0, sizeof(du)); 99 for(int i = 1; i <= M; i++) 100 { 101 scanf("%d%d", &u[i], &v[i]); 102 du[u[i]]++; du[v[i]]++; 103 } 104 double l = 1.0/N, r = double(M)/1.0, mid, h = 0; 105 double teps = 1.0/double(N)/double(N); 106 while(r-l >= teps) 107 { 108 mid = (l+r)/2.0; 109 edges.clear(); 110 for(int i = 0; i <= N+1; i++) G[i].clear(); 111 for(int i = 1; i <= N; i++) 112 { 113 AddEdge(s, i, M); 114 AddEdge(i, t, M+2*mid-du[i]); 115 } 116 for(int i = 1; i <= M; i++) 117 { 118 AddEdge(u[i], v[i], 1.0); 119 AddEdge(v[i], u[i], 1.0); 120 } 121 h = (M*N-Maxflow())*0.5; 122 int cnt = 0; 123 for(int i = 1; i <= N; i++) 124 { 125 if(vis[i]) cnt++; 126 } 127 if(h >= eps) l = mid; 128 else r = mid; 129 } 130 edges.clear(); 131 for(int i = 0; i <= N+1; i++) G[i].clear(); 132 for(int i = 1; i <= N; i++) 133 { 134 AddEdge(s, i, M); AddEdge(i, t, M+2*l-du[i]); 135 } 136 for(int i = 1; i <= M; i++) 137 { 138 AddEdge(u[i], v[i], 1.0); 139 AddEdge(v[i], u[i], 1.0); 140 } 141 Maxflow(); 142 int cnt = 0; 143 for(int i = 1; i <= N; i++) 144 { 145 if(vis[i]) cnt++; 146 } 147 printf("%d\n", cnt); 148 for(int i = 1; i <= N; i++) 149 { 150 if(vis[i]) printf("%d\n", i); 151 } 152 } 153 return 0; 154 }
标签:
原文地址:http://www.cnblogs.com/titicia/p/4700666.html