标签:
在今天的文章里我会讨论下可串行化(SERIALIZABLE)隔离级别里会有的锁升级(Lock Escalations),还有你如何避免。在上个月的7月14日,我已经介绍了SQL Server里锁升级(Lock Escalations)的基本概念还有为什么需要它们。因此请你回到这个文章来理解下这个非常重要的概念。
可串行化(SERIALIZABLE)隔离级别用来阻止所谓的幻影记录(Phantom Records)。为了阻止它们,SQL Server使用键范围锁定(Key-Range Locking)技术。我们来看下面的SELECT语句:
1 SELECT * FROM Person.Address 2 WHERE StateProvinceID BETWEEN 10 AND 12 3 GO
这个语句请求StateProvinceID在10到12之间的所有记录。如果你在可串行化(SERIALIZABLE)隔离级别运行这个语句,这些范围内的IDs会被锁定,保护它不会被数据修改:
这个范围之外的修改是允许的,因为SQL Server只锁定了那个特定范围。
键范围锁定(Key-Range Locking)技术最重要的是在你的查询谓语上需要支持的非聚集索引。在我们的例子里是StateProvinceID列。如果在它上面没有支持的索引定义,在执行计划里查询优化器会选择聚集索引扫描/表扫描(Clustered Index Scan/Table Scan)运算符。这意味着你必须扫描你的整个表(用残留谓语(residual predicate))来找匹配的记录。
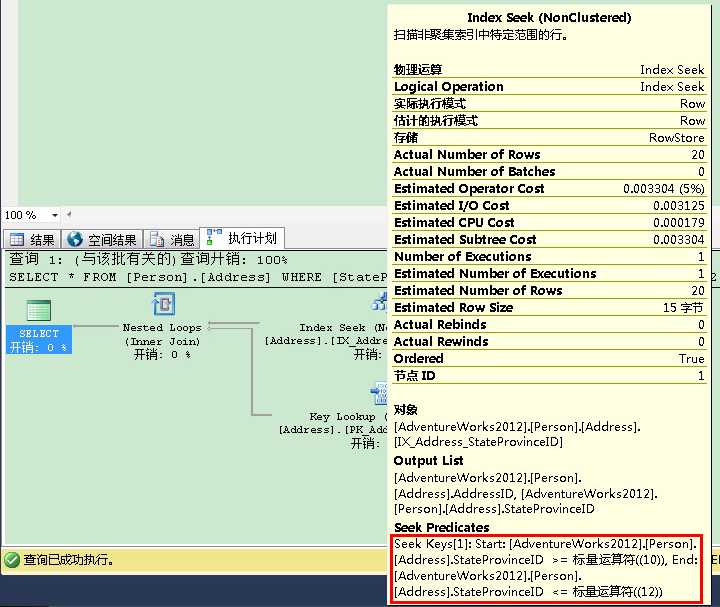
当你在可串行化(SERIALIZABLE)隔离级别里运行你的SELECT语句,在你扫描期间获得超过5000个锁时,你会触发锁升级(Lock Escalations)。下面代码演示了当没有支持的非聚集索引时,你如何触发锁升级(Lock Escalations)。
1 SET TRANSACTION ISOLATION LEVEL SERIALIZABLE 2 GO 3 4 BEGIN TRANSACTION 5 6 -- The following statement causes a Lock Escalation, because there is no 7 -- supporting Non-Clustered index on the column "StateProvinceID" 8 SELECT * FROM Person.Address 9 WHERE StateProvinceID BETWEEN 10 AND 12 10 11 -- There is only a S lock on the table itself! 12 SELECT * FROM sys.dm_tran_locks 13 WHERE request_session_id = @@SPID 14 15 ROLLBACK 16 GO
现在让我们创建支持的非聚集索引。
1 -- Create a supporting Non-Clustered Index 2 CREATE NONCLUSTERED INDEX idx_StateProvinceID ON Person.Address(StateProvinceID) 3 GO
现在当你查看执行计划时,你会看到查询优化器引用了这个新创建的索引并与书签查找(Bookmark Lookup)进行了组合。
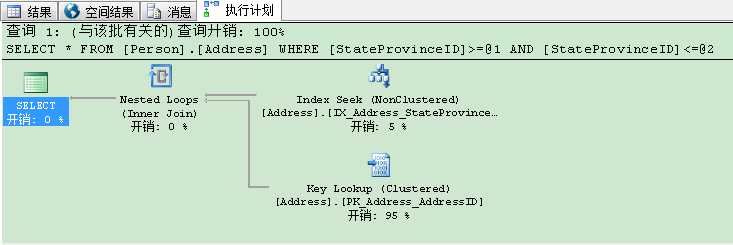
当你在可串行化(SERIALIZABLE)隔离级别里再次运行SELECT语句,你不会触发锁升级了,因为物理上你只读20条请求行。
可串行化(SERIALIZABLE)隔离级别是最有限制的一个,它会阻止幻影记录(Phantom Records)。SQL Server内部使用键范围锁定(Key-Range Locking)技术来保持请求范围行的稳定。这里你要记住最重要的是你在你搜索谓语(search predicate)上要有支持的非聚集索引。不然的话你需要扫描你的整个表,如果你读取超过5000行,你就会触发锁升级(Lock Escalations)。
感谢关注!
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4695897.html