HDFS和Mapreduce是Hadoop的两大核心。整个Hadoop的体系结构主要是通过HDFS来实现分布式存储的底层支持,MapReduce来实现分布式并行任务处理的程序支持。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中 NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存储在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开,关闭,重命名文件或目录等。它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在 NameNode的统一调度下进行数据块的创建、删除和复制工作。
NameNode是所有HDFS元数据的管理者,用户需要保存的数据不会经过NameNode,而是直接流向存储数据的DataNode。
NameNode是整个HDFS的核心,它通过维护一些数据结构来记录每个文件被切割成多少个Block,这些Block可以从哪些DataNode中获取,以及各个DataNode的状态等重要信息。
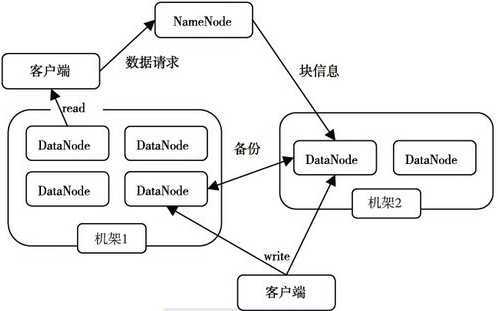
图 4 HDFS结构图
MapReduce是一个并行编程模式,利用这种模式软件开发者可以轻松的编写出分布式并行程序。在Hadoop的体系结构 中,MapReduce是一种简单易用的软件框架,基于它可以将任务分发到由千台商用机器组成的集群上,并以一种可靠容错的方式并行处理大量的数据集,实 现Hadoop的并行任务处理功能。MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的 TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务;从节点仅负责由主节点指派的任务。当一个job被提交 时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
总体来说HDFS负责文件的存取,MapReduce负责任务的执行。
原文地址:http://www.cnblogs.com/shihuai355/p/3835070.html