以下图1是hadoop生态图,通俗的说,就是hadoop核心模块和衍生的子项目。
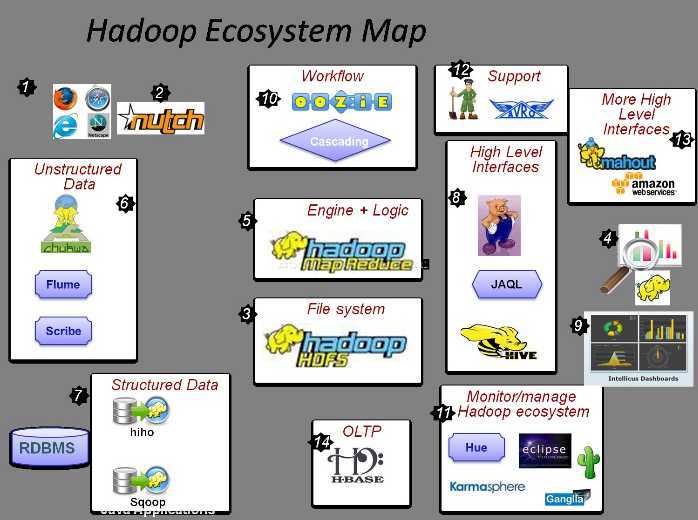
图 1 Hadoop生态系统图
由图可知,hadoop生态系统包括以下成员:
① 各种浏览器,产生海量的Web数据;
② Nutch项目,一个快速搜索海量网页的开源项目
③ HDFS,Hadoop分布式文件系统,大数据的存储系统;
④ 数据分析和可视化工具;
⑤ MapReduce,大数据处理系统;
⑥ 非结构化数据采集和处理工具(fuse,webdav,chukwa,flume,Scribe);
⑦ 结构化数据与HDFS之间的交互工具(Hiho,sqoop);
⑧ 多样化的MapReduce程序控制工具(Pig,Hive,Jaql);
⑨ 数据可视化工具(drilldown,Intellicus);
⑩ 工作流管理工具(oozie,Cascading);
? Hadoop生态系统的监管工具(Hue,karmasphere,eclipse plugin,cacti,ganglia);
? 数据序列化处理与任务调度工具(Avro,Zookeeper);
? 构建在Hadoop上层的服务( Mahout,Elastic map Reduce);
? 在线事务处理存储系统(HBase)。
整个Hadoop生态系统涉及到了大数据收集、大数据存储、大数据处理、大数据分析和大数据应用,从而真正达到寻找和应用大数据价值的目的。(3)和(5)是Hadoop的核心模块,破解了大数据存储和处理的难题。
原文地址:http://www.cnblogs.com/shihuai355/p/3835051.html