标签:
欢迎转载,转载注明出处:
http://www.cnblogs.com/NeighborhoodGuo/p/4702932.html
Go Go Go
第十讲也顺利结束啦,不愧是Advanced Recursive NN讲得内容确实有些Advanced,不过如果认真听课再认真看课后的paper的话,我相信还是可以完全理解的。
开始总结喽。。。
首先,老师在课上开篇讲了RNN的一个综述吧,也是使用RNN进行NLP的三个大的要素:1.Train objective主要有两种,一种是cross-entropy或者max-margin 2.Composition Function,这一讲主要讲了这个内容 3.Tree structure这个在上一讲有详细讲,chain structure或者balance tree
这一讲讲了四个models,上图:

第二条Matrix-Vector RNNs在Relation Classification方面的应用在paper中没有见到,仅在课上一带而过。所以说这一讲也就主要讲了各个模型在Paraphrase detection及Sentiment Analysis方面的应用。
好吧从上往下撸(- -)
RNNs for Paraphrase Detection主要包含两个方面。第一方面是Recursive Autoencoder,第二方面是Neural Network for Variable-Sized Input
这个模型在第二篇paper里讲得很详细
首先我们已经有了一个parse tree,有一个可信的parse tree对于paraphrase detection很重要。
Recursive Autoencoder有两种Autoencoder的方法。

第一种是左边的这种,每次decoder只decoder出一层,然后求所有non-terminal nodes的error的和作为loss function。non-terminal nodes的error是其两个children的vectors先连接出来,然后再求欧式距离得到的。
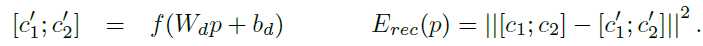
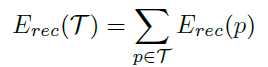
上面两式中,其中下面的式子中的T集合是所有non-terminal nodes,上面的式子中的c1, c2分别是p的两个children
由于non-terminal nodes的值可以通过无限shrinking the norms of the hidden layers来实现,所以必须对non-terminal nodes的值p进行normalization
第二种是上面图片里右边的那种reconstruct the entire spanned subtree underneath each nodes
就是把所有的leaf nodes全部decode出来,然后把所有leaf nodes连接起来,求欧式距离作为loss function
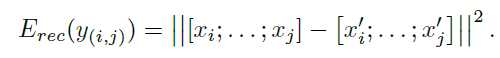
上面的model tune好了,然后进行下一个阶段。
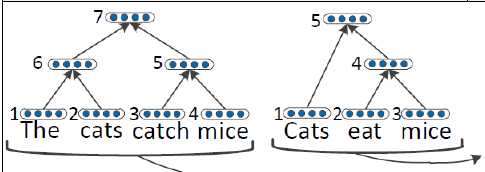
以上是tune好的tree
首先先建立一个similarity matrix,其中column和row分别按照单词的从左到右的顺序以及上面的hidden nodes从下到上从右到左的顺序排列
第二步是pooling,其中pooling layer的是一个square matrix先对#col及#row取一个fixed值,设为n_p。论文里是使用的非over-lapping的方法,就是不重叠行或者列。
如果#col > n_p, #row > n_p,每#col/n_p及#row/n_p作为一个pool最后会剩下一个比较小的pool行或者列都小于n_p。
如果#col < n_p,#row < n_p,先duplicating pixels小于n_p的那一边,然后直到那一边的pixels大于n_p为止。
在每个pool里取其最小值,然后在pool之后normalize每个entry使其mean = 0及variance = 1
paper里提到了一个对于数字的改进方法:第一如果两个句子里的数字完全一样或没有数字,设为1,反之设为0;第二如果两个句子里包含一样的数字,设为1;第三一个句子里的数字严格的是另一个句子里数字的子集,设为1
这种方法有两个缺点:第一是仅仅比较单词或者phrase的相似性遗失了语法结构;第二是计算similarity matrix也遗漏了部分信息。
最后把得到的similarity matrix输入到一个NN里或者softmax classifier里再建立loss function就能进行优化计算了。
Matrix-Vector RNNs这个模型比较简单就是在表示一个word的时候不仅仅只用vector的形式表示,用matrix加vector结合起来的方式表示一个word
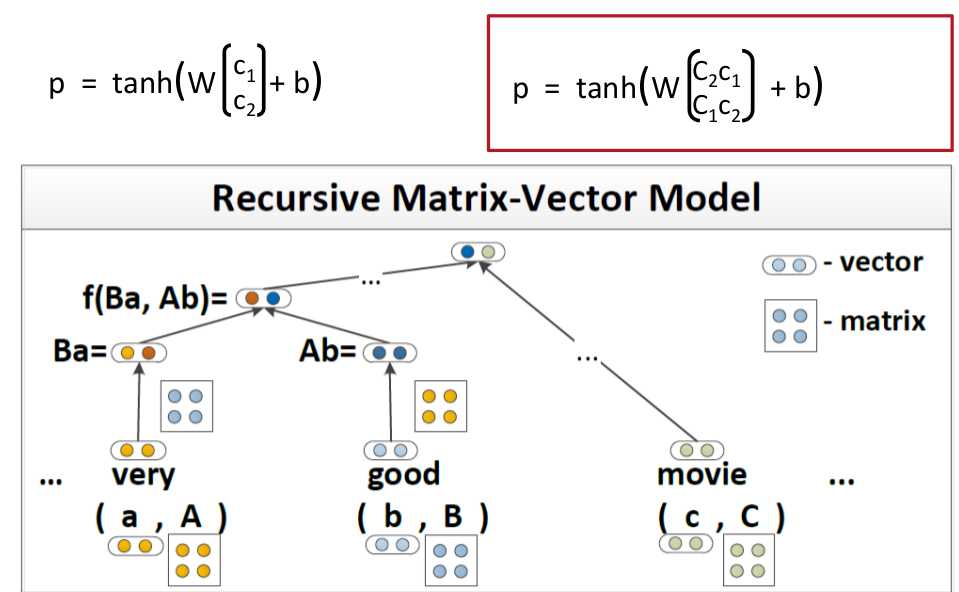
以上就是Matrix-Vector的表示方法,和stardard的差异比较小。
课上说这个模型对Relationship Classification的效果比较好。
Relationship Classification简单的说就像以前中学从一句话里提取出关键词。
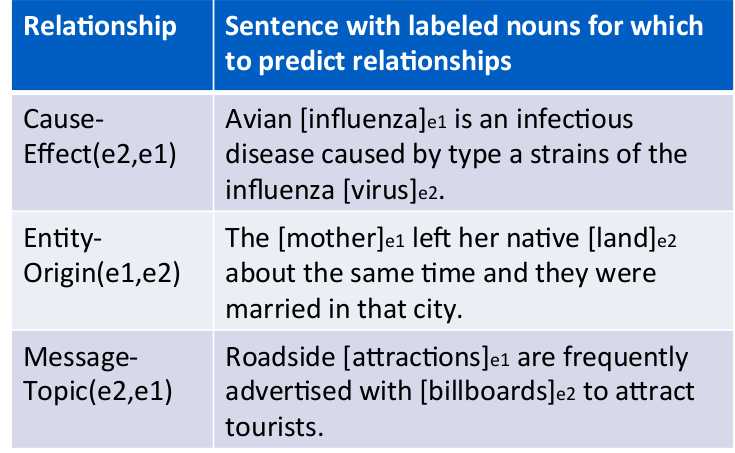
Bag-of-words的方式进行sentiment detection比较不靠谱,因为bag-of-words不能capture一个句子的parse tree还有linguistic features
使用好的corpus也会提高精确度,很诱人哦!
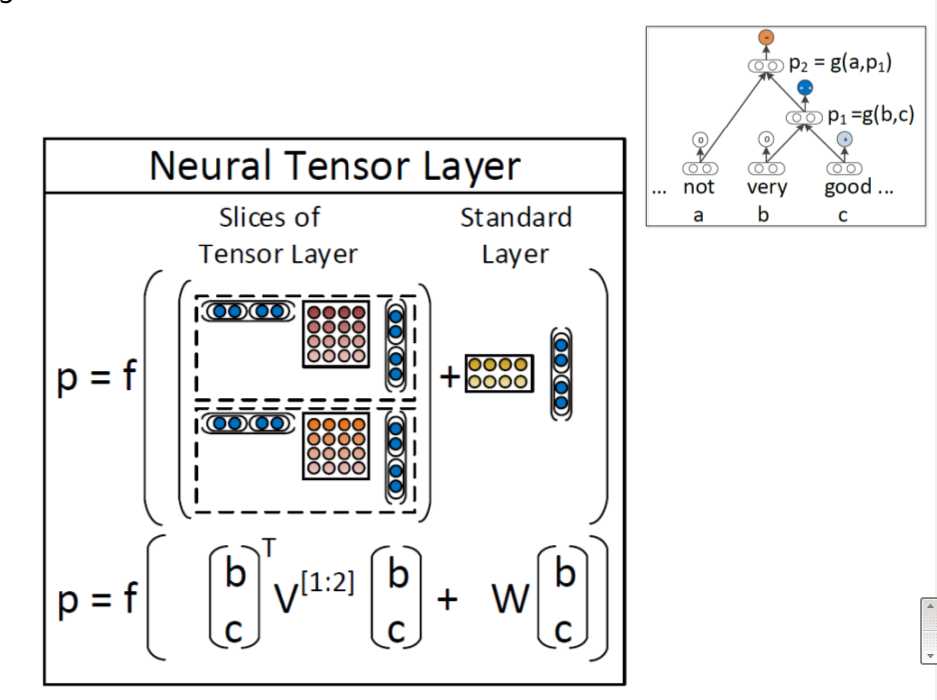
其实整体模型改动也不太大,也很好理解,这样就能很好的捕捉到句子的sentiment
这个模型的优化和之前的略有不同:

这个模型据说是现今唯一能够capture negation及其scope的模型。
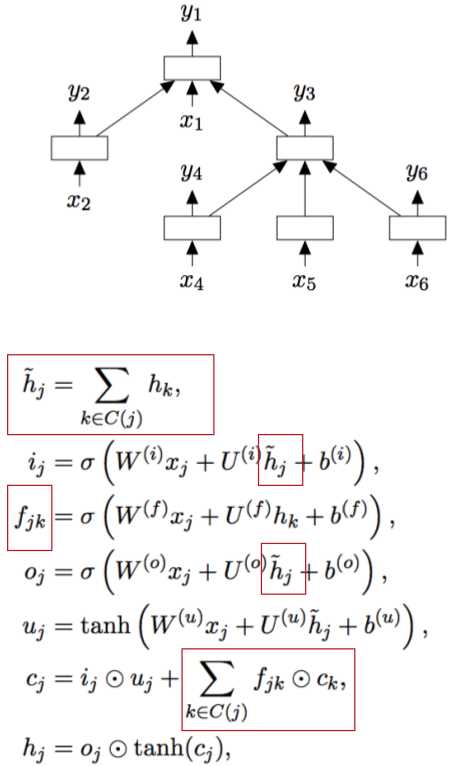
Tree LSTMs和普通的LSTMs的不同之处在于Tree LSTMs是从tree的结构中进行LSTMs的建模。
普通的LSTMs也可以看作是Tree LSTMs的一种特殊情况。
Tree LSTMs里leaf node的hidden计算和之前的普通的hidden计算方法一样,只是其parents的计算略有不同。具体公式见上图。
parent的hidden是其children的hiddens的和,每一个forget unit是根据具体的某个node来计算的,计算最终cell时要把所有forget units和对应的cells相乘并求和,其他都是和普通LSTMs一样的计算方法了。
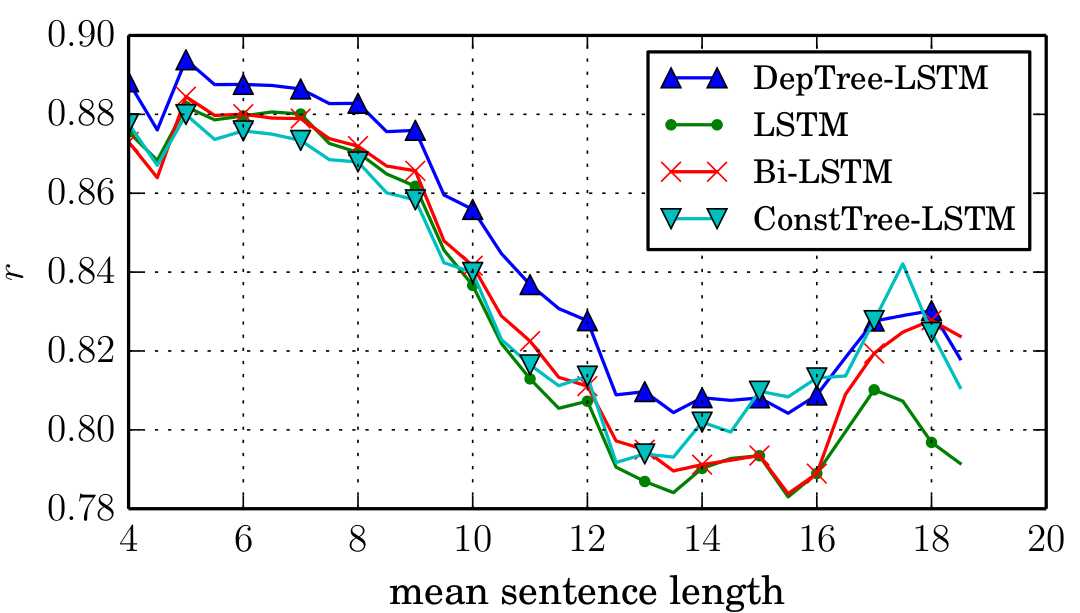
这个模型对于semantic similarity目前还是最适用的。如图:
标签:
原文地址:http://www.cnblogs.com/NeighborhoodGuo/p/4702932.html