标签:
特性:
1、目前支持天涯社区(论坛)、新浪论坛、等等。程序提供扩充框架,可以增加对新论坛的支持。
2、提供了自动排版的功能。
3、提供了简单的统计功能。
下载地址,用法见本文后一部分:
http://pan.baidu.com/s/1ntwkwOD
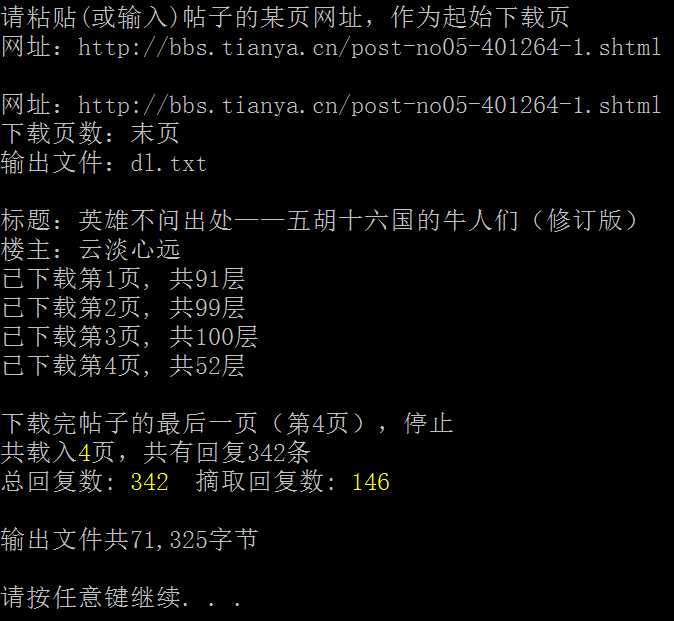
截图,下载帖子:
截图,自动处理:

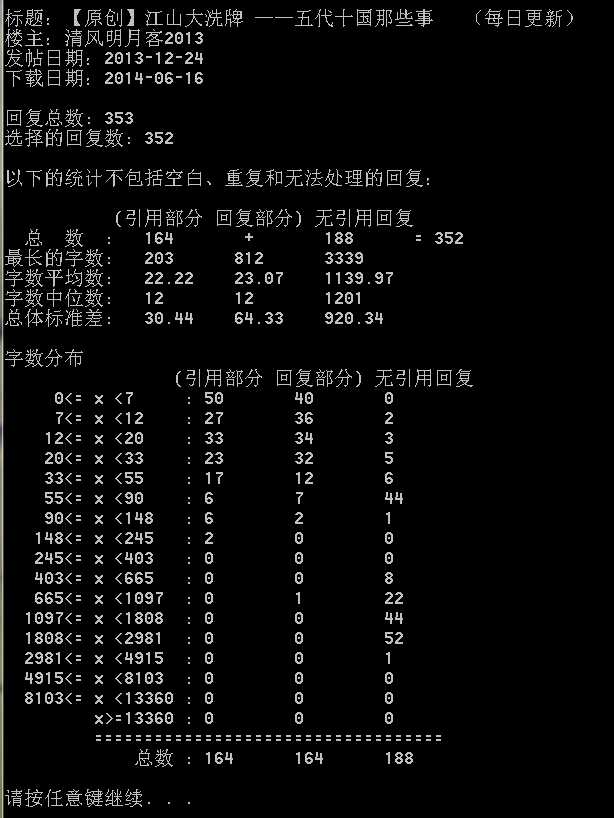
截图,统计:
以下为用法说明。新手留意褐色文字即可:
tz2txt,此工具用于帮助您把<帖子里的楼主发言>转为<纯txt文件>。
本工具(包括源码)已经上传至GitHub,要获取最新版本可访问:
https://github.com/animalize/tz2txt
【安装Python】
本工具用Python编写,必须安装Python运行环境(版本在3.4以上)。到Python官网下载:
https://www.python.org/downloads/
也可以用下面的链接直接下载。如果不清楚是32位还是64位,下载32位即可:
windows 32位版本的Python安装包:
https://www.python.org/ftp/python/3.4.3/python-3.4.3.msi
windows 64位版本的Python安装包:
https://www.python.org/ftp/python/3.4.3/python-3.4.3.amd64.msi
在安装Python后,执行命令pip install colorama,部分信息将以彩色显示;不执行此命令的话也可以正常运行,但不会显示色彩。
【整体工作流程】
一、下载。
下载帖子的一部分或全部页面,生成只包括楼主发言的<编排文本>。
二、编辑排版。
这一步,可以自动处理、也可以手动处理。
在<编排文本>里,每条回复后面有个保留标记,如:
<mark>══════保留标记:█
如果想丢弃这个回复,删掉最后那个黑方块即可。
以<time>和<mark>开头的行之间是一条回复。只要保证<time>行和<mark>行配对,可以任意编辑回复内容。
三、编译。
把未处理的或处理过的<编排文本>编译成<纯文本>。
【操作方法】
一、简单的用法是:
双击“_a全自动.bat”可以全自动生成auto.txt,但不保存下载文件、不保存自动处理后的编排文件。
二、比较全面的用法是:
依次双击“_1下载帖子.bat”、“_2处理编排.bat”、“_3编译最终.bat”。
这个过程中,会把下载的帖子保存为dl.txt,自动处理后的编排文本保存为bp.txt。
final.txt就是编译后的纯文本,~discard.txt就是自动处理时标记丢弃的内容。
(注意:自动处理有其局限性,用户也可以手动处理)
三、想查看编排文件bp.txt的统计信息,可以双击“_b统计编排.bat”。
【小经验】
☆不推荐用记事本编辑<编排文本>,可以用免费开源的文本编辑器Notepad++(http://notepad-plus-plus.org/)。
☆如果帖子太长,可以分段下载(例如每次下载50页)。
☆编译后,可以把下载的原<编排文本>和处理过的<编排文本>保留一段时间。
☆如果网速慢,可在fetcher.py文件里更改单次下载动作的超时秒数,默认是open_timeout = 60。
☆保存的文件都是GB18030编码(兼容GB2312/GBK)。
☆程序预留扩展空间,可以增加支持新的论坛,详见sites文件夹的说明。
【附录:程序参数】
1、d功能,下载帖子(只包含楼主的发言),并保存为<编排文本>,参数为:
tz2txt.py d [-u 网址] [-t 页数] [-o 文件名]
-u 网址:帖子的某一页的网址,可以不是首页
-t 页数:打算下载的总页数,-1表示到最终页(如果帖子很长,慎用-1)
-o 文件名:是输出的<编排文本>文件名
例: tz2txt.py d -u http://bbs.sample.com/thread-12345.html -t 10 -o download.txt
从当前页开始,一共下载10页,保存<编排文本>到download.txt
2、p功能,自动处理<编排文本>,比如去掉重复回复、处理引用格式:
tz2txt p [-i 文件名] [-o 文件名]
-i 文件名:输入的<编排文本>
-o 文件名:输出的<编排文本>
例: tz2txt.py p -i download.txt -o bp.txt
自动处理download.txt并保存为bp.txt
3、s功能,统计<编排文本>的信息:
tz2txt.py s [-i 文件名]
-i 文件名:输入的<编排文本>
例: tz2txt.py s -i bp.txt
统计bp.txt文件的信息并显示
4、c功能,编译<编排文本>到<纯文本>:
tz2txt c [-i 文件名] [-o 文件名] [-d 文件名]
-i 文件名:输入的<编排文本>
-o 文件名:输出的<纯文本>
-d 文件名:保存编译过程中丢弃的回复到这个文件
例: tz2txt.py c -i bp.txt -o final.txt -d ~discard.txt
把<编排文本>bp.txt编译为<纯文本>final.txt,
并把编译过程中丢弃的回复保存到~discard.txt
5、a功能,全自动生成<纯文本>:
tz2txt.py a [-u 网址] [-t 页数] [-o 文件名] [-d 文件名]
-u 网址:帖子的某一页的网址,可以不是首页
-t 页数:打算下载的总页数,-1表示到最终页(如果帖子很长,慎用-1)
-o 文件名:是输出的<纯文本>文件名
-d 文件名:保存编译过程中丢弃的回复到这个文件
例: tz2txt.py a -u http://bbs.sample.com/thread-12345.html -t 10 -o auto.txt -d ~discard.txt
从当前页开始,一共下载10页,生成<纯文本>到auto.txt,
并把编译过程中丢弃的回复保存到~discard.txt
标签:
原文地址:http://www.cnblogs.com/animalize/p/4704418.html