标签:
一 什么是HBASE
Hbase 是建立在Hadoop HDFS上的一个 分布式的 面向列存储的 开源数据库。来源于google的一篇论文《bigtable;一个结构化数据的分布式存储系统》利用MapReduce来处理HBase中的海量数据,利用Zookeeper
作为协同服务。
HBase 以表的形式存储数据。表中由行和列组成。
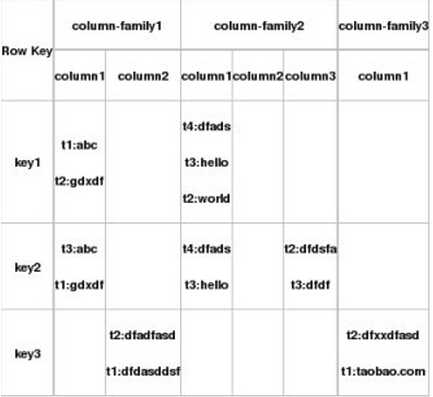
key1,key2,key3是三条记录的ROWKEY,相当于主键。图中有三个列簇,colum-family1,2,3。每个family下有多个列,column+rowkey形成了cell 。cell中可以有多条数据,用时间戳来区分。数据按照时间戳的倒序排序,即最新的数据在最前面。cell中的数据没有类型全部按照字节码形式存储。
二 物理存储
1 table中的所有行都按照Row key的字典排列
2 table在行的方向上分割为多个Hregion
3 region然后按大小分割,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当大到一个阈值的时候,Hregion分割为两个新的Hregiion。当行不断增多的时候,就会有更多的Hregion。
4 Hregion是Hbase中分布式存储和负载平衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的Hregion server上。但一个Hregion是不会拆分到多个server上的。
5 Hregion 虽然是分布式存储的最小单元但不是存储的最小单元。事实上,Hregion由一个或多个Store组成,每个store保存一个columns family。 每个store由一个memStore和0到多个StoreFile组成。StoreFile以Hfile格式保存在HDFS上。
Hmaster的作用:
1 为region serve分配region
2 负责regionserver上的负载均衡
3 发现失效的region server并从新分配其上的region
4 负责GFS上的垃圾回收
5 处理schema更新请求
Region server的作用
1 负责管理region 处理系统的IO请求
2 负责切分系统在运行过程中生成过大的region
三 region定位
系统如何找到某个Rowkey所在的region
bigtable使用三层类似B+树的结构来保存region位置
第一层是保存zookeeper里面的文件,他持有root region的位置。
第二层是root region 是 .META.表的第一个region其中保存了 .META.表的其他region位置。通过root region 可以访问到 .Meta.表的数据
第三层 是.META.表 他是一个特殊的表,保存了hbase中所有数据表的region位置信息。
四 读写过程
存储的最小单元是store 每个store由一个memStore和0到多个StoreFile组成
1 数据更新时首先写入Log 和内存MemStore memstore中对数据排了序
2 当MemStore累计到一定的阈值后,就会创建一个新的MemStore.然后将旧的Memstore加入flush队列。flush到磁盘上形成一个StoreFile,以Hfile格式存储。同时系统会在zookeeper上形成一个redo point,表示这个时刻之前的变更已经持久化了。方便同步
当系统出现意外时,可能导致内存中数据丢失,此时使用log来恢复checkpoint之后的数据
由于storeFile是只读的,一旦创建后就不可以在修改。因此Hbase的更新其实是对StoreFile的不断追加。当StoreFIle达到一定阈值后,就会进行一次合并,将对同一key的修改合并到一起,此时才相当于删除。然后形成一个大的stroreFile,当其在达到一定的阈值后,就会对其splite拆分成两个storeFile。
由于对表的更新时不断追加的,处理读的请求时,需要访问memstore和StoreFile将他们按照可以进行合并。由于其都是经过排序,且StoreFile带有内存中索引所以合并查找很快。
标签:
原文地址:http://www.cnblogs.com/lotorless/p/4709476.html