标签:
 一、Windods下solr3.6的配置( 与Linux大同小异)
一、Windods下solr3.6的配置( 与Linux大同小异) 首先去官网下载solr,不多说。
解压打开找到dist文件夹,找到以.war结尾的文件,改成solr.war。Copy到Tomcat/webapps打开
将Solr配置文件/opt/program/solr3.6.2/example/multicore Copy至tomcat/conf/文件下
打开WEB-INF下面的web.xml 找到
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\apache-tomcat-solr-master\conf\multicore</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
将注释去掉。这里需要注意默认的配置这里是注释掉的。然后
<env-entry-value>D:\apache-tomcat-solr-master\conf\multicore </env-entry-value>这里需要配置你的solr的地方。
D:\apache-tomcat-solr-master\conf\localhost 新建Solr.xml
<Context docBase="${catalina.home}/webapps/solr.war" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="${catalina.home}/conf/multicore" override="true" />
</Context>
启动Tomcat访问http://localhost:7001/solr/这是出现 点击Solr Admin链接,进入到
这个时候solr就已经配置好了哦~下一步就可以使用了
二、关于Solr schmema.xml 和Solrfig.xml的属性解析 一、字段配置(schema) schema.xml位于solr/conf/目录下,类似于数据表配置文件,
定义了加入索引的数据的数据类型,主要包括type、fields和其他的一些缺省设置。
1.schema.xml文档注释中的信息:
1、为了改进性能,可以采取以下几种措施:
将所有只用于搜索的,而不需要作为结果的field(特别是一些比较大的field)的stored设置为false
将不需要被用于搜索的,而只是作为结果返回的field的indexed设置为false
删除所有不必要的copyField声明
为了索引字段的最小化和搜索的效率,将所有的 text fields的index都设置成field,然后使用copyField将他们都复制到一个总的 text field上,然后对他进行搜索。
为了最大化搜索效率,使用java编写的客户端与solr交互(使用流通信)
在服务器端运行JVM(省去网络通信),使用尽可能高的Log输出等级,减少日志量。
2、< schema name =" example " version =" 1.2 " >
name:标识这个schema的名字
version:现在版本是1.2
3、filedType
< fieldType name =" string " class =" solr.StrField " sortMissingLast =" true " omitNorms =" true " />
name:标识而已。
class和其他属性决定了这个fieldType的实际行为。(class以solr开始的,都是在org.appache.solr.analysis包下)
可选的属性:
sortMissingLast和sortMissingFirst两个属性是用在可以内在使用String排序的类型上(包括:string,boolean,sint,slong,sfloat,sdouble,pdate)。
sortMissingLast="true",没有该field的数据排在有该field的数据之后,而不管请求时的排序规则。
sortMissingFirst="true",跟上面倒过来呗。
2个值默认是设置成false
StrField类型不被分析,而是被逐字地索引/存储。
StrField和TextField都有一个可选的属性“compressThreshold”,保证压缩到不小于一个大小(单位:char)
< fieldType name =" text " class =" solr.TextField " positionIncrementGap =" 100 " >
solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误。
name: 字段类型名
class: java类名
indexed: 缺省true。 说明这个数据应被搜索和排序,如果数据没有indexed,则stored应是true。
stored: 缺省true。说明这个字段被包含在搜索结果中是合适的。如果数据没有stored,则indexed应是true。
sortMissingLast: 指没有该指定字段数据的document排在有该指定字段数据的document的后面
sortMissingFirst: 指没有该指定字段数据的document排在有该指定字段数据的document的前面
omitNorms: 字段的长度不影响得分和在索引时不做boost时,设置它为true。一般文本字段不设置为true。
termVectors: 如果字段被用来做more like this 和highlight的特性时应设置为true。
compressed: 字段是压缩的。这可能导致索引和搜索变慢,但会减少存储空间,只有StrField和TextField是可以压缩,这通常适合字段的长度超过200个字符。
multiValued: 字段多于一个值的时候,可设置为true。
positionIncrementGap: 和multiValued
一起使用,设置多个值之间的虚拟空白的数量
< tokenizer class =" solr.WhitespaceTokenizerFactory " />
空格分词,精确匹配。
< filter class =" solr.WordDelimiterFilterFactory " generateWordParts =" 1 " generateNumberParts =" 1 " catenateWords =" 1 " catenateNumbers =" 1 " catenateAll =" 0 " splitOnCaseChange =" 1 " />
在分词和匹配时,考虑 "-"连字符,字母数字的界限,非字母数字字符,这样 "wifi"或"wi fi"都能匹配"Wi-Fi"。
< filter class =" solr.SynonymFilterFactory " synonyms =" synonyms.txt " ignoreCase =" true " expand =" true " />
同义词
< filter class =" solr.StopFilterFactory " ignoreCase =" true " words =" stopwords.txt " enablePositionIncrements =" true " />
在禁用字(stopword)删除后,在短语间增加间隔
stopword:即在建立索引过程中(建立索引和搜索)被忽略的词,比如is this等常用词。在conf/stopwords.txt维护。
4、fields
< field name =" id " type =" string " indexed =" true " stored =" true " required =" true " />
name:标识而已。
type:先前定义的类型。
indexed:是否被用来建立索引(关系到搜索和排序)
stored:是否储存
compressed:[false],是否使用gzip压缩(只有TextField和StrField可以压缩)
mutiValued:是否包含多个值
omitNorms:是否忽略掉Norm,可以节省内存空间,只有全文本field和need an index-time boost的field需要norm。(具体没看懂,注释里有矛盾)
termVectors:[false],当设置true,会存储 term vector。当使用MoreLikeThis,用来作为相似词的field应该存储起来。
termPositions:存储 term vector中的地址信息,会消耗存储开销。
termOffsets:存储 term vector 的偏移量,会消耗存储开销。
default:如果没有属性需要修改,就可以用这个标识下。
< field name =" text " type =" text " indexed =" true " stored =" false " multiValued =" true " />
包罗万象(有点夸张)的field,包含所有可搜索的text fields,通过copyField实现。
< copyField source =" cat " dest =" text " />
< copyField source =" name " dest =" text " />
< copyField source =" manu " dest =" text " />
< copyField source =" features " dest =" text " />
< copyField source =" includes " dest =" text " />
在添加索引时,将所有被拷贝field(如cat)中的数据拷贝到text field中
作用:
将多个field的数据放在一起同时搜索,提供速度
将一个field的数据拷贝到另一个,可以用2种不同的方式来建立索引。
< dynamicField name =" *_i " type =" int " indexed =" true " stored =" true " />
如果一个field的名字没有匹配到,那么就会用动态field试图匹配定义的各种模式。
"*"只能出现在模式的最前和最后
较长的模式会被先去做匹配
如果2个模式同时匹配上,最先定义的优先
< dynamicField name =" * " type =" ignored " multiValued=" true " />
如果通过上面的匹配都没找到,可以定义这个,然后定义个type,当String处理。(一般不会发生)
但若不定义,找不到匹配会报错。
5、其他一些标签
< uniqueKey > id </ uniqueKey >
文档的唯一标识, 必须填写这个field(除非该field被标记required="false"),否则solr建立索引报错。
< defaultSearchField > text </ defaultSearchField >
如果搜索参数中没有指定具体的field,那么这是默认的域。
< solrQueryParser defaultOperator =" OR " />
配置搜索参数短语间的逻辑,可以是"AND|OR"。
二、solrconfig.xml
1、索引配置
mainIndex 标记段定义了控制Solr索引处理的一些因素.
useCompoundFile:通过将很多 Lucene 内部文件整合到单一一个文件来减少使用中的文件的数量。这可有助于减少 Solr 使用的文件句柄数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则false 的默认值应该就已经足够。
useCompoundFile:通过将很多Lucene内部文件整合到一个文件,来减少使用中的文件的数量。这可有助于减少Solr使用的文件句柄的数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则false的默认值应该就已经足够了。
mergeFacor:决定Lucene段被合并的频率。较小的值(最小为2)使用的内存较少但导致的索引时间也更慢。较大的值可使索引时间变快但会牺牲较多的内存。(典型的时间与空间 的平衡配置)
maxBufferedDocs:在合并内存中文档和创建新段之前,定义所需索引的最小文档数。段是用来存储索引信息的Lucene文件。较大的值可使索引时间变快但会牺牲较多内存。
maxMergeDocs:控制可由Solr合并的 Document 的最大数。较小的值(<10,000)最适合于具有大量更新的应用程序。
maxFieldLength:对于给定的Document,控制可添加到Field的最大条目数,进而阶段该文档。如果文档可能会很大,就需要增加这个数值。然后,若将这个值设置得过高会导致内存不足错误。
unlockOnStartup:告知Solr忽略在多线程环境中用来保护索引的锁定机制。在某些情况下,索引可能会由于不正确的关机或其他错误而一直处于锁定,这就妨碍了添加和更新。将其设置为true可以禁用启动索引,进而允许进行添加和更新。(锁机制)
2、查询处理配置
query标记段中以下一些与缓存无关的特性:
maxBooleanClauses:定义可组合在一起形成以个查询的字句数量的上限。正常情况1024已经足够。如果应用程序大量使用了通配符或范围查询,增加这个限制将能避免当值超出时,抛出TooMangClausesException。
enableLazyFieldLoading: 如果应用程序只会检索Document上少数几个Field,那么可以将这个属性设置为 true。懒散加载的一个常见场景大都发生在应用程序返回一些列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的现实常 常只需要现实很短的一段信息。若是检索大型的Document,除非必需,否则就应该避免加载整个文档。
query部分负责定义与在Solr中发生的时间相关的几个选项:
概念:Solr(实际上是Lucene)使用称为Searcher的Java类来处理Query实例。Searcher将索引内容相关的数据加载到 内存中。根据索引、CPU已经可用内存的大小,这个过程可能需要较长的一段时间。要改进这一设计和显著提高性能,Solr引入了一张“温暖”策略,即把这 些新的Searcher联机以便为现场用户提供查询服务之前,先对它们进行“热身”。
newSearcher和firstSearcher事件,可以使用这些事件来制定实例化新Searcher或第一个Searcher 时,应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新Searcher或第一个Searcher时就应该反注释这些部分并执行适当的 查询。
3.query中的智能缓存:
filterCache:通过存储一个匹配给定查询的文档 id 的无序集,过滤器让 Solr 能够有效提高查询的性能。缓存这些过滤器意味着对Solr的重复调用可以导致结果集的快速查找。更常见的场景是缓存一个过滤器,然后再发起后续的精炼查 询,这种查询能使用过滤器来限制要搜索的文档数。
queryResultCache:为查询、排序条件和所请求文档的数量缓存文档 id 的有序集合。
documentCache:缓存Lucene Document,使用内部Lucene文档id(以便不与Solr唯一id相混淆)。由于Lucene的内部Document id 可以因索引操作而更改,这种缓存不能自热。
Named caches:命名缓存是用户定义的缓存,可被 Solr定制插件 所使用。
其中filterCache、queryResultCache、Named caches(如果实现了org.apache.solr.search.CacheRegenerator)可以自热。
每个缓存声明都接受最多四个属性:
class:是缓存实现的Java名
size:是最大的条目数
initialSize:是缓存的初始大小
autoWarmCount:是取自旧缓存以预热新缓存的条目数。如果条目很多,就意味着缓存的hit会更多,只不过需要花更长的预热时间。
对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、cpu和磁盘访问之间进行均衡。统计信息管理页(管理员界面的Statistics)对 于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在 缓存中这一额外步骤而受到影响。
三、Solr查询参数 一、Query参数
1、CoreQueryParam查询的参数
q: 查询字符串,必须的。
q.op: 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑),一般默认指定。
df: 默认的查询字段,一般默认指定。
qt: query type,指定查询使用的Query Handler,默认为“standard”。
wt: writer type。指定查询输出结构格式,默认为“xml”。在solrconfig.xml中定义了查询输出格式:xml、json、python、ruby、php、phps、custom。
echoHandler:是否在查询结果中显示使用的Query Handler名称。
echoParams:是否显示查询参数。none:不显示;explicit:只显示查询参数;all:所有,包括在solrconfig.xml定义的Query Handler参数。
indent - 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version - 查询语法的版本,建议不使用它,由服务器指定默认值。
2、CommonQueryParameters
sort:排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:(inStock desc, price asc)表示先 “inStock” 降序, 再 “price” 升序,默认是相关性降序。。
start:用于分页定义结果起始记录数,默认为0。
rows:用于分页定义结果每页返回记录数,默认为10。
fq:filter query。使用Filter Query可以充分利用Filter Query Cache,提高检索性能。作用:在q查询符合结果中同时是fq查询符合的,例如:q=mm&fq=date_time:[20081001 TO 20091031],找关键字mm,并且date_time是20081001到20091031之间的。
fl:field list。指定返回结果字段。以空格“ ”或逗号“,”分隔。
debugQuery:设置返回结果是否显示Debug信息。
explainOther:设置当debugQuery=true时,显示其他的查询说明。
defType:设置查询解析器名称。
timeAllowed:设置查询超时时间。
omitHeader:设置是否忽略查询结果返回头信息,默认为“false”。
二、查询语法
1、匹配所有文档:*:*
2、强制、阻止和可选查询:
Mandatory:查询结果中必须包括的(for example, only entry name containing the word make)
Solr/Lucene Statement:+make, +make +up ,+make +up +kiss
prohibited:(for example, all documents except those with word believe)
Solr/Lucene Statement:+make +up -kiss
optional:
Solr/Lucene Statement:+make +up kiss
3、布尔操作:AND、OR和NOT布尔操作(必须大写)与Mandatory、optional和prohibited相似。
make AND up = +make +up :AND左右两边的操作都是mandatory
make || up = make OR up=make up :OR左右两边的操作都是optional
+make +up NOT kiss = +make +up –kiss
make AND up OR french AND Kiss不可以达到期望的结果,因为AND两边的操作都是mandatory的。
4、子表达式查询(子查询):可以使用“()”构造子查询。
For ex:(make AND up) OR (french AND Kiss)
5、子表达式查询中阻止查询的限制:
For ex:make (-up):只能取得make的查询结果;要使用make (-up *:*)查询make或者不包括up的结果。
1. 多字段fields查询:通过字段名加上分号的方式(fieldName:query)来进行查询
For ex:entryNm:make AND entryId:3cdc86e8e0fb4da8ab17caed42f6760c
2. 通配符查询(wildCard Query):
通配符?和*:“*”表示匹配任意字符;“?”表示匹配出现的位置。
For ex:ma?*(ma后面的一个位置匹配),ma??*(ma后面两个位置都匹配)
查询字符必须要小写:+Ma +be**可以搜索到结果;+Ma +Be**没有搜索结果
查询速度较慢,尤其是通配符在首位:主要原因一是需要迭代查询字段中的每个term,判断是否匹配;二是匹配上的term被加到内部的查询,当terms数量达到1024的时候,查询会失败。
Solr中默认通配符不能出现在首位(可以修改QueryParser,设置
setAllowLeadingWildcard为true)
set setAllowLeadingWildcard to true.
3. 模糊查询、相似查询:不是精确的查询,通过对查询的字段进行重新插入、删除和转换来取得得分较高的查询解决(由Levenstein Distance Algorithm算法支持)。
1) 一般模糊查询:for ex:make-believ~
2) 门槛模糊查询:对模糊查询可以设置查询门槛,门槛是0~1之间的数值,门槛越高表面相似度越高。For ex:make-believ~0.5、make-believ~0.8、make-believ~0.9
6、范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询。结束的范围可以使用“*”通配符。
For ex:
日期范围(ISO-8601 时间GMT):sa_type:2 AND a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
数字:salary:[2000 TO *]
文本:entryNm:[a TO a]
7、日期匹配:YEAR, MONTH, DAY, DATE (synonymous with DAY) HOUR, MINUTE, SECOND, MILLISECOND, and MILLI (synonymous with MILLISECOND)可以被标志成日期。
For ex:
r_event_date:[* TO NOW-2YEAR]:2年前的现在这个时间
r_event_date:[* TO NOW/DAY-2YEAR]:2年前前一天的这个时间
三、函数查询(Function Query)
函数查询 可以利用 numeric域的值 或者 与域相关的的某个特定的值的函数,来对文档进行评分。
1、使用函数查询的方法
这里主要有三种方法可以使用函数查询,这三种s方法都是通过solr http接口的。
1) 使用FunctionQParserPlugin。ie: q={!func}log(foo)
2) 使用“_val_”内嵌方法
内嵌在正常的solr查询表达式中。即,将函数查询写在 q这个参数中,这时候,我们使用“_val_”将函数与其他的查询加以区别。
ie:entryNm:make && _val_:ord(entryNm)
3) 使用dismax中的bf参数
使用明确为函数查询的参数,比如说dismax中的bf(boost function)这个参数。 注意:bf这个参数是可以接受多个函数查询的,它们之间用空格隔开,它们还可以带上权重。所以,当我们使用bf这个参数的时候,我们必须保证单个函数中是没有空格出现的,不然程序有可能会以为是两个函数。
For ex:
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3
2、函数的格式(Function Query Syntax)
目前,function query 并不支持 a+b 这样的形式,我们得把它写成一个方法形式,这就是 sum(a,b).
使用函数查询注意事项
用于函数查询的field必须是被索引的;
字段不可以是多值的(multi-value)
3、可以利用的函数 (available function)
constant:支持有小数点的常量; 例如:1.5 ;SolrQuerySyntax:_val_:1.5
fieldvalue:这个函数将会返回numeric field的值,这个域必须是indexd的,非multiValued的。格式很简单,就是该域的名字。如果这个域中没有这样的值,那么将会返回0。
ord:对于一个域,它所有的值都将会按照字典顺序排列,这个函数返回你要查询的那个特定的值在这个顺序中的排名。这个域,必须是非multiValued的,当没有值存在的时候,将返回0。例如:某个特定的域只能去三个值,“apple”、“banana”、“pear”,那么ord(“apple”)=1,ord(“banana”)=2,ord(“pear”)=3.需要注意的是,ord()这个函数,依赖于值在索引中的位置,所以当有文档被删除、或者添加的时候,ord()的值就会发生变化。当你使用MultiSearcher的时候,这个值也就是不定的了。
rord:这个函数将会返回与ord相对应的倒排序的排名。
格式: rord(myIndexedField)。
sum:这个函数的意思就显而易见啦,它就是表示“和”啦。
格式:sum(x,1) 、sum(x,y)、 sum(sqrt(x),log(y),z,0.5)
product:product(x,y,...)将会返回多个函数的乘积。格式:product(x,2)、product(x,y)
div:div(x,y)表示x除以y的值,格式:div(1,x)、div(sum(x,100),max(y,1))
pow:pow表示幂值。pow(x,y) =x^y。例如:pow(x,0.5) 表示开方pow(x,log(y))
abs:abs(x)将返回表达式的绝对值。格式:abs(-5)、 abs(x)
log:log(x)将会返回基数为10,x的对数。格式: log(x)、 log(sum(x,100))
Sqrt:sqrt(x) 返回 一个数的平方根。格式:sqrt(2)、sqrt(sum(x,100))
Map:如果 x>=min,且x<=max,那么map(x,min,max,target)=target.如果 x不在[min,max]这个区间内,那么map(x,min,max,target)=x.
格式:map(x,0,0,1)
Scale:scale(x,minTarget,maxTarget) 这个函数将会把x的值限制在[minTarget,maxTarget]范围内。
query :query(subquery,default)将会返回给定subquery的分数,如果subquery与文档不匹配,那么将会返回默认值。任何的查询类型都是受支持的。可以通过引用的方式,也可以直接指定查询串。
例子:q=product(popularity, query({!dismax v=‘solr rocks‘}) 将会返回popularity和通过dismax 查询得到的分数的乘积。
q=product(popularity, query($qq)&qq={!dismax}solr rocks 跟上一个例子的效果是一样的。不过这里使用的是引用的方式
q=product(popularity, query($qq,0.1)&qq={!dismax}solr rocks 在前一个例子的基础上又加了一个默认值。
linear: inear(x,m,c)表示 m*x+c ,其中m和c都是常量,x是一个变量也可以是一个函数。例如: linear(x,2,4)=2*x+4.
Recip:recip(x,m,a,b)=a/(m*x+b)其中,m、a、b是常量,x是变量或者一个函数。当a=b,并且x>=0的时候,这个函数的最大值是1,值的大小随着x的增大而减小。例如:recip(rord(creationDate),1,1000,1000)
Max: max(x,c)将会返回一个函数和一个常量之间的最大值。
例如:max(myfield,0)
private SolrServer server;
Public void createIndex(){
String url = "http://localhost:8080/solr";
try {
server = new CommonsHttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "1");
doc.addField("customerCName", "solrJ创建索引");
server.add(doc);
server.commit();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
server = null;
System.runFinalization();
System.gc();
}
}
六、solr下配置IKAnalyzer分词器 1:将IKAnalyzer_home文件夹下的stopword.dic和IKAnalyzer.cfg.xml复制到tomcat /webapps/solr/WEB-INF/classes下,并修改
IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">/mydict.dic; /mypack/mydict2.dic ; /com/mycompany/dic/mydict3.dic ;</entry>
-->
<entry key="ext_dict">mydict.dic;extension.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>
2:修改stopword.dic,加入您需要的词库信息,例如:在最后加入如下三行:
国
中华
中华人民
七、垂直搜索服务架构
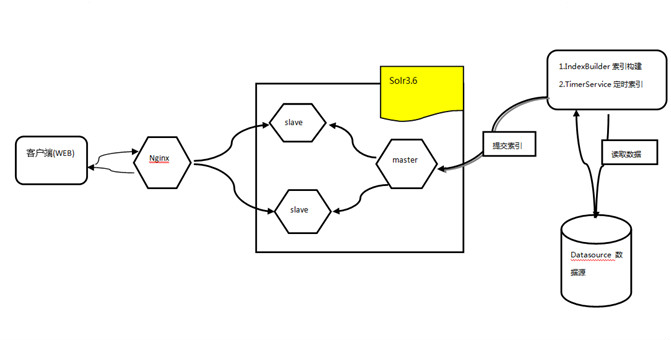
solr的索引replication模式:将索引从主服务器上复制到多个服务器上.
索引复制原因:当有很多个客户并发访问某Solr服务器,这可能会导致Solr服务器崩溃(Solr服务器性能达不到这些客户并发访问的需求),这时就需要通过solr索引复制来减少对服务器的性能要求。
下面介绍一下主从服务器的最简单配置(如下配置在项目中已经通过验证):
Linux环境:solr master(127.0.0.1:8080), solr slave1(127.0.0.2:8081), solr slave2(127.0.0.3:8082), jdk 1.7.0_65, master(apache-tomcat-7), slave(apache-tomcat-7), apache-solr-3.6.2
先将solr与tomcat进行整合,可以参考solr3.6与tomcat的整合
配置主服务器solr Master(127.0.0.1:8080), 在solrconfig.xml中增加以下内容
<!-- solr分布式配置之索引复制 -->
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<!--在 ‘optimize(合并索引)‘后进行同步,其他可选的值还有‘commit‘, ‘startup‘,该值可以填多个-->
<str name="replicateAfter">commit</str>
<str name="replicateAfter">startup</str>
<!--在 ‘optimize(合并索引)‘后备份索引,其他可选的值还有‘commit‘, ‘startup‘,该值可以填多个-->
<!-- <str name="backupAfter">optimize</str> -->
<!--指定备份多少份文件,默认值为 MAX_VALUE-->
<int name="numberToKeep">1</int>
<!--指定需要同步的配置文件,多份文件以逗号分隔 -->
<str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str>
<!--The default value of reservation is 10 secs. Normally , you should not need to specify this -->
<str name="commitReserveDuration">00:00:30</str>
<str name="httpBasicAuthUser">xxoo</str>
<str name="httpBasicAuthPassword">xxoo</str>
</lst>
</requestHandler>
replicateAfter : SOLR会自行在以下操作行为发生后执行复制: ‘commit‘, ‘startup‘, ‘optimize‘,该值可以填多个
backupAfter:SOLR会自行在以下操作行为发生后执行备份索引: ‘commit‘, ‘startup‘, ‘optimize‘,该值可以填多个
numberToKeep:指定备份多少份文件,默认值为 MAX_VALUE
confFiles : 待分发的配置文件,solr 也会将主服务器上的字段配置文件:schema.xml和stopwords.txt,固排文件: elevate.xml同步到辅服务器上。
commitReserveDuration: 每次commit之后,保留增量索引的周期时间,这里设置为30秒
optimize:有点像硬盘上整理磁盘碎片的操作。为了提高搜索速度,它会将索引重组在一起,然后移除需要被删除或是更新的文档,请注意,solr是没有 update的这种操作的,只有增加与删除。solr在优化时,将需要删除或是被替换的索引标记为deleted,然后再创建新的文档替换掉需要被替换 的。optimize就是执行此操作。所以在优化的时候,你的索引会增大,然后再减小。optimize操作会创建一个全新的的索引结构,所以,你需要预 备出2倍于你commit时索引大小的空间。
配置从服务器solr slave(127.0.0.2), 在solrconfig.xml中增加以下内容:
<!-- solr分布式配置之索引复制 -->
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="slave">
<!--主索引的url,该从索引将从这个主索引地址同步索引-->
<str name="masterUrl">http://127.0.0.1:8080/solr/product/replication</str>
<!--拉取间隔,达到这个时间,从索引将从主索引同步索引.格式为 is HH:mm:ss .
如果该设置为空从索引将不会主动从主索引同步索引.
另外拉取索引的请求也可以通过 admin 页面或者 http api 来触发 -->
<str name="pollInterval">00:00:30</str>
<!-- 以下参数不常用,非必填参数-->
<!--在索引传输过程中使用压缩,可选的值有两个 internal 和 external 如果值是 ‘external‘ 请确保主索引的solr已经设置了accept-encoding header。如果值是 ‘internal‘ 索引数据将被自动压缩?,这个主要在低带宽情况下使用,局域网中请不要使用,局域网中使用会降低复制效率-->
<str name="compression">internal</str>
<!--以下是配置连接和读取超时时间,这个跟 http 中的概念一样,单位为毫秒-->
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<!-- 如果主服务中的 http base 的鉴权可用的话,从服务就需要配置这个用户名和密码
<str name="httpBasicAuthUser">xxoo</str>
<str name="httpBasicAuthPassword">xxoo</str>
-->
</lst>
</requestHandler>
masterUrl : 主索引的url,该从索引将从这个主索引地址同步索引
pollInterval:从服务器同步间隔,即每隔多长时间同步一次主服务器,格式为HH:mm:ss . 如果该设置为空从索引将不会主动从主索引同步索引.另外拉取索引的请求也可以通过 admin 页面或者 http api 来触发
compression:在索引传输过程中使用压缩,可选的值有两个 internal 和 external
如果值是 ‘external‘ 请确保主索引的solr已经设置了accept-encoding header
如果值是 ‘internal‘ 索引数据将被自动压缩,这个主要在低带宽情况下使用,局域网中请不要使用,局域网中使用会降低复制效率
httpConnTimeout:设置连接超时(单位:毫秒)
httpReadTimeout:设置读取超时,如果设置同步索引文件过大,则应适当提高此值。(单位:毫秒)
httpBasicAuthUser:验证用户名,需要和主服务器一致
httpBasicAuthPassword:验证密码,需和主服务器一致
注:从服务器可以有多个,多个从服务器的配置相同
标签:
原文地址:http://my.oschina.net/nuotang/blog/489030