标签:
我才知道爬虫还可以这样—火车采集器的使用
额。。。好吧,我这一个三毛钱的屌丝也开始步入实习阶段了,在北京其实也挺好的,虽说压力大,但是今后就业机会也相对而言大一些。好了,说回今天的主题,之前学习Python爬虫的时候一直以为今后工作的话进行爬虫需要自己写源代码然后再一直爬呀爬呀爬,但是不是这样滴(应该不是吧),前天公司扔给我一个抓取网页的工具,然后自己在一直琢磨琢磨,今天下午有了结果了,学习了简单的抓取网页数据。所以我在这里总结一下网站数据采集器—火车采集器的简单使用。
首先,下载火车采集器,这个网上的链接有很多。

这是安装完成之后的火车采集器文件夹。

使用步骤
1.账号登陆进入之后(好像这个账号申请是需要花钱的),我们先新建分组,注意选择所属分组的时候选择正确就OK。
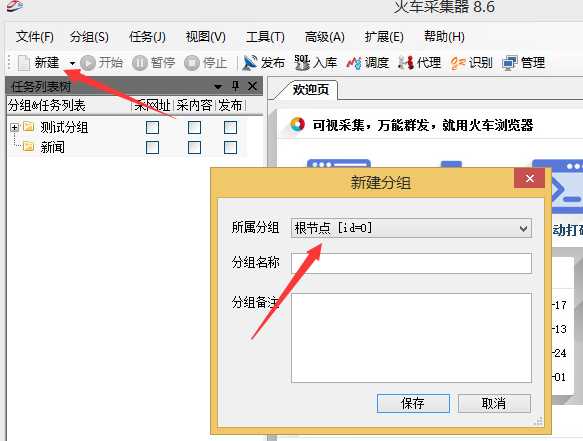
2.对你需要在其组进行任务的组右键选择新建任务
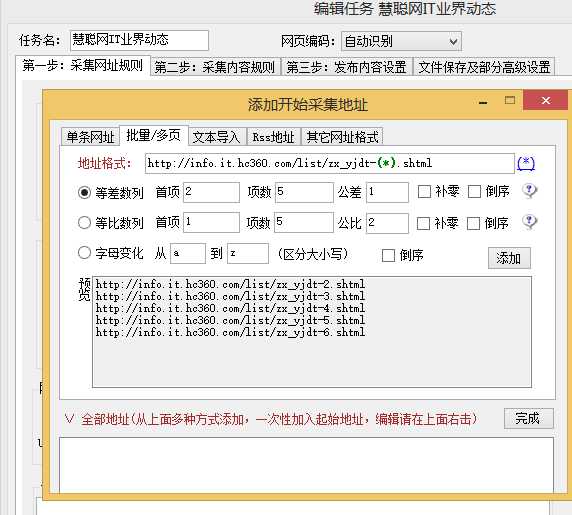
3.编辑此任务,以慧聪网IT业界动态为例。因为涉及到网页的链接,所以我们需要选择【批量/多页】一栏,然后把URL里面变动的数字
换成(*),还可以根据自己的需要对其链接网址采取等差等比数列的抓取。然后点击【添加】,点击【完成】。
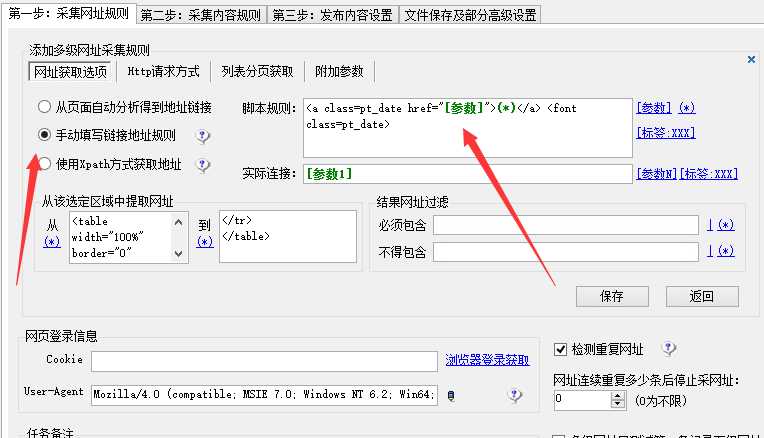
4.在多级网址获取一栏里面进行设置。我选择的是手动填写链接地址规则,这就要求对网页的源代码进行分析和截取。注意在【从该选定区域中提取网址】的两个空白框里填写的是我们抓取的网站首页源代码里我们需要那些链接的那一部分代码前后的title源码,也就是说这两个框里的源代码把我们需要的那些链接的源代码夹在了中间。最后点击保存。
5.采集内容规则。我们的标签名就是我们需要抓取网页的信息,双击标签名之后添加代码,原理和第4步骤一样的。在提取内容的时候,我们还可以对其进行数据处理,点击添加进行选择。
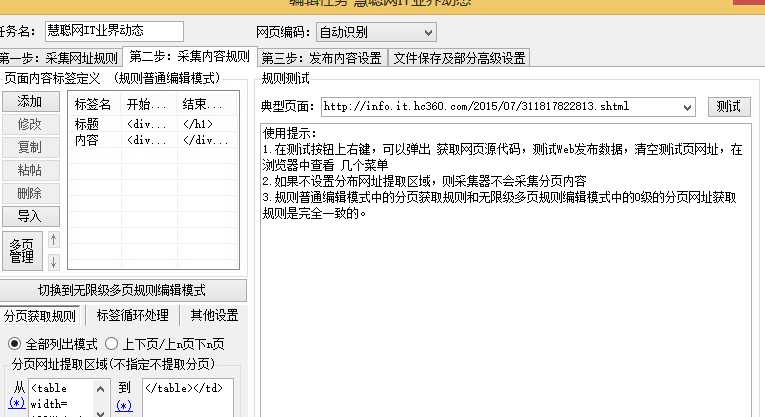
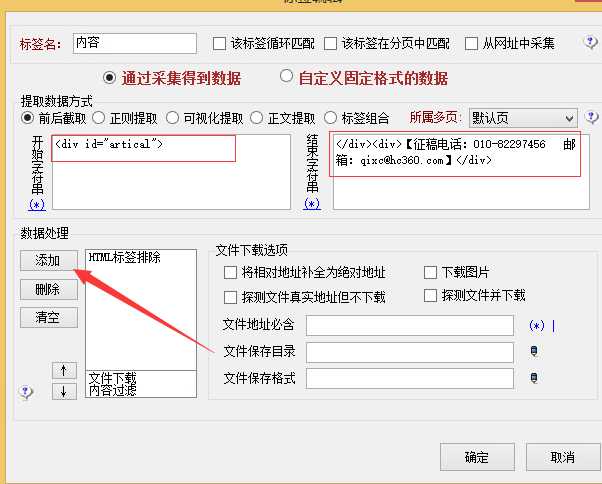
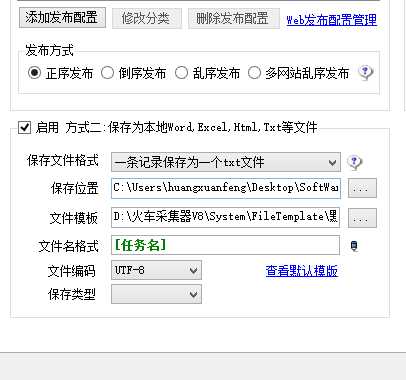
6.我们把抓取到的内容保存在本地计算机上,这个时候我们需要注意的是:火车采集器里有默认的模板,但是如果我们采集内容的标签名和默认模板里的不一致,就需要对其修改,使其和我们的标签名一致即可。点击保存。
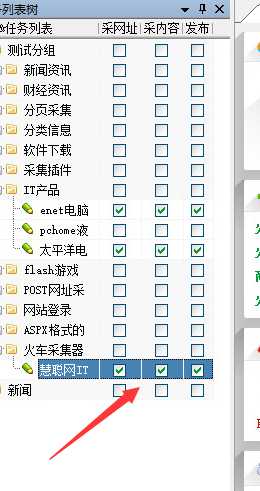
7.开始对网站数据进行抓取工作。首先勾选这三个选项。
然后右键,开始任务,等待数据的采集。
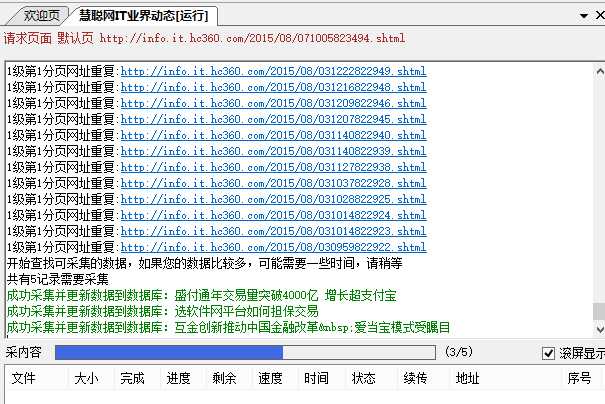
8.抓取完成,成功之后,打开本地的文件,却没有看到数据,而且标签名也乱码了。不知道怎么回事,是不是我的姿势不对啊,又找了好几个网站又试了几次,认认真真看了源代码好几次,实在是找不出哪里错了啊,各种捉急。后来才知道,妈的txt文件默认格式不是UTF-8的,需要我们改一下,所以另存为一下就OK了。然后再跑一次工具,查看文件,卧槽,果然有数据了,成功的抓取到网站数据了,而且把链接里的也抓取出来了。
这只是一个简单的开始,火车采集器还有很多操作需要我学习,比如把数据存入数据库,抓取图片啊什么的。
加油吧,继续努力!!!
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4711658.html