标签:
前言:
都说现在是草根为尊的时代,近年来hadoop及spark技术在国内越来越流行。而且渐渐现成为企业的新宠。在DT时代全面来临之前,能提早接触大数据的技术必然能先人一步。本文作为Hadoop系列的第一篇,将HDFS和MapRed两个技术核心用2个实例简单实现一些,希望能供hadoop入门的朋友些许参考。
--HDFS
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.FileSystem; 5 import org.apache.hadoop.fs.Path; 6 7 public class HDFStest { 8 final static String P_IN="hdfs://hadoop0:9000/data"; 9 final static String P_F1="hdfs://hadoop0:9000/a.txt"; 10 11 12 public static void main(String[] args) throws IOException { 13 14 FileSystem fileSystem = FileSystem.get(new Configuration()); 15 System.out.println("make diretory:"); 16 fileSystem.mkdirs(new Path(P_IN)); 17 System.out.println("judgy if exist ‘File‘:"); 18 System.out.println(fileSystem.exists(new Path(P_F1))); 19 20 } 21 22 }
--MapReduce
实现文本单词出现次数的统计: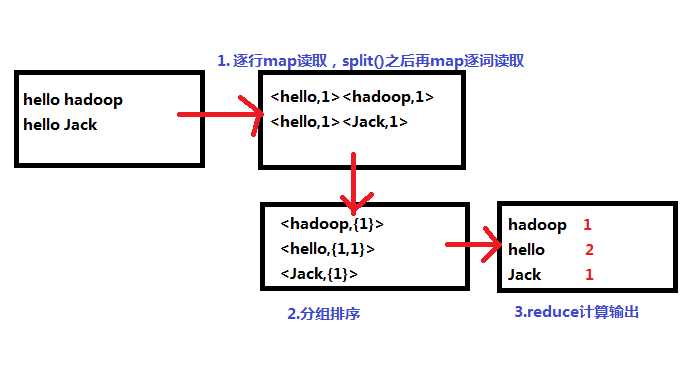
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.Mapper; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 12 13 public class WC { 14 15 static String INPUT="hdfs://hadoop0:9000/hello"; 16 static String OUTPUT="hdfs://hadoop0:9000/output"; 17 18 public static void main(String[] args) throws Exception{ 19 20 21 Job job = new Job(new Configuration(),WC.class.getSimpleName()); 22 job.setMapperClass(MyMapper.class); 23 job.setReducerClass(MyReducer.class); 24 job.setJarByClass(WC.class); 25 //输出结果格式 26 job.setMapOutputKeyClass(Text.class);; 27 job.setMapOutputValueClass(LongWritable.class); 28 job.setOutputKeyClass(Text.class); 29 job.setOutputValueClass(LongWritable.class); 30 //路径设置 31 FileInputFormat.setInputPaths(job, INPUT); 32 FileOutputFormat.setOutputPath(job, new Path(OUTPUT)); 33 //waitfor 34 job.waitForCompletion(true); 35 36 } 37 38 static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable >{ 39 40 @Override 41 protected void map(LongWritable key, Text value, 42 Mapper<LongWritable, Text, Text, LongWritable>.Context context) 43 throws IOException, InterruptedException { 44 45 String[] words = value.toString().split(" "); 46 for(String word:words){ 47 context.write(new Text(word), new LongWritable(1)); 48 } 49 } 50 } 51 static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ 52 53 @Override 54 protected void reduce(Text arg0, Iterable<LongWritable> arg1,Context context) 55 throws IOException, InterruptedException { 56 57 Long sum=0L; 58 for(LongWritable c:arg1){ 59 sum += c.get(); 60 } 61 context.write(arg0,new LongWritable(sum)); 62 } 63 } 64 }
以上代码相对简单,map读取到一行“Text”之后通过字符串切分函数split()得到各个单词,每个单词出现一次计数为1:

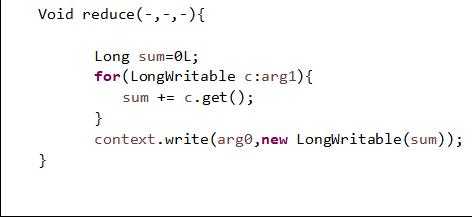
Reduce操作,实际就是一个集合元素累计的操作:
标签:
原文地址:http://www.cnblogs.com/SeaSky0606/p/4711785.html