标签:
最近一直在看卷积神经网络,想改进改进弄出点新东西来,看了好多论文,写了一篇综述,对深度学习中卷积神经网络有了一些新认识,和大家分享下。
其实卷积神经网络并不是一项新兴的算法,早在上世纪八十年代就已经被提出来,但当时硬件运算能力有限,所以当时只用来识别支票上的手写体数字,并且应用于实际。2006年深度学习的泰斗在《科学》上发表一篇文章,论证了深度结构在特征提取问题上的潜在实力,从而掀起了深度结构研究的浪潮,卷积神经网络作为一种已经存在的、有一定应用经验的深度结构,重新回到人们视线,此时硬件的运算能力也比之前有了质的飞跃,要芯片有芯片要GPU有GPU,还有开源的Caffe框架,于是CNN就起来了。
纵观目前已经发表的有关CNN方面的文献,多是侧重应用领域。国内期刊上有关CNN的期刊发表得并不多,一般都是从2012年之后开始出现,而且四大学报对CNN方面的文章发表力度还并没有想想中的大,不知道是大家不愿意投呢,还是期刊那对这个领域的东西持犹豫态度,不过CNN方面的学术论文可是非常多,可见很多学校,很多老师,很多学生都在搞这个。国外方面对于CNN的论文就相对多一些了,图像识别,语音识别等方面都有涉猎,与国内不同的是国外发表的文献在理论方面下的功夫要多一些,国内一般都是直接把CNN直接拿来用,老方法新问题,而且效果还不错,可见CNN作为深度学习的重要成员,确实很强。
之前一直想着怎样对传统CNN进行改进,看了看大家的工作,改进的方向无非是要么在结构上改,要么在训练算法上改,目前CNN的改进基本上都在遵循着这个框架。
一、在结构上的改进
传统的CNN本质上是一个映射的堆叠,图下图所示
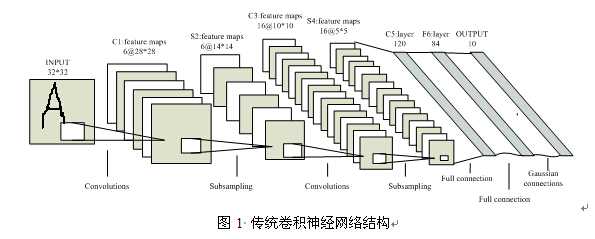
之所以说它是传统,主要是它对输入形式、卷积核、级联形式、初始化方法都没有严格要求,就使用最原始的卷积核,随机初始化。当然也正是因为他的传统、原始,才使得其有改进的空间。下面说说已有的比较成功的改进方法。
1、在网络输入上下功夫。传统的CNN呢,直接把图片作为数据输入进去了,从道理上讲刚好符合稀疏表示理论中“像素本身是图像语音最冗余的表示”的观点,但是大家还是希望对图像进行一些预处理,毕竟机器视觉比不上人眼,人的肉眼看东西时可能一下完成了好多种模式分类的工作,而我们在做研究时,一次一般也就研究一种或者几种特定的模式分类问题。既然问题是特定的,理论上必然会有对付这种问题的特效药,就好比我们要识别白纸上的毛笔字,没必要把整张纸都送进去操作,那样确实信息够全,但是速度太慢,反过来想想,要是条件理想,说不定直接阈值化一把就OK了,虽然信息损失了不少,但重要的信息还在,速度也快,正确率也可以接受,因此需要对图像预处理。可见,并不是所有的问题都是直接把图像直接以输入就OK了,做些预处理还是很有必要,比如颜色分层处理、构建尺度金字塔、提取点什么特征(Gabor、SIFT、PCA等等),都是可以的,因问题而已。有人在用CNN做显著性检测时就是把图像先进行了一把超像素分割,然后把分割后的超像素作为新的网络输入,而且是三个通道同时输入,如下图:
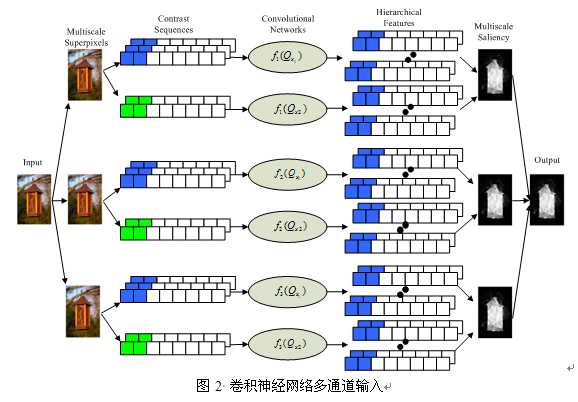
2、特征融合上下功夫。传统CNN就是把图像一层层映射,映射到最后就是特征提取的结果,通俗的讲就好比用筛子筛谷子,一边一边的筛,筛到最后就是精华,但那些中间筛出去的东西呢,肯定不是垃圾,也是包含一定信息,对图像由一定表现能力的,因此何不把这部分的映射结果也加以融合利用,这样得到的特征岂不是更有表现力?有人在做人脸识别的时候就想到了这一点,并努力实现了,如下图
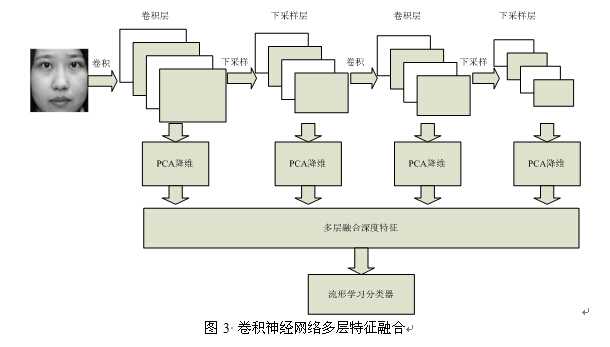
他是把各个层的映射结果PCA降维后融合到一起的,效果不错。
3、在卷积核上加限制。前面说过,传统CNN就是单纯的卷积核,于是我们想,能不能把那些卷积核改成Gabor核呢?小波核行不行?稀疏映射矩阵是不是也可以,不过那时候的神经网络就不能再叫卷积神经网络了,估计就应该叫深度Gabor卷积网络了吧,重要的是这点还没有人做,说不定以后可以下下功夫,不过已经有人把卷积核改进到加权PCA 矩阵,做出深度特征脸卷积神经网络了,结构如下图:
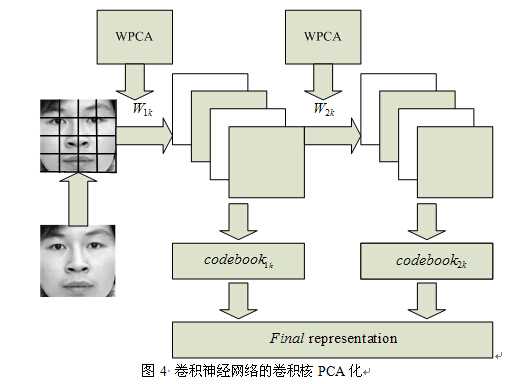
这个看上去有点复杂,其实就是先对图像进行分块,然后将每个小块都送入深度网络中进行映射,映射核即为加权PCA矩阵,然后将每层映射结果经过码本聚合,得到最终的特征表示形式。其实这种针对特定问题构建特定映射核的方法在理论上是有道理的,比如说之前的场景分类,用Gist特征有奇效,那就不妨将卷积核改为Gist核,其实也就类似于Gabor核,弄个深度Gist卷积神经网络来解决场景分类问题,说不定就会有更好的效果,科研重在实验嘛。其实这种卷积核的改进和以前的传统CNN已经有了很大区别,主要是抽象的借鉴了深度结构的概念,不过我认为这也正是深度学习的精髓所在。
4、与其他分类器结合。卷积神经网络可以看做是特征提取与分类器的结合体,单从它的各个层的映射来看,类似于一个特征提取的过程,提取了不同层次的特征。但如果映射来映射去,最后就映射到几个标签上,则它又有了分类的功能。但我更倾向于把CNN看成是一个特征提取的手段。那既然是特征提取,就必然要搭配一些好的分类器了,SVM、稀疏表示分了器,都不错,相信两者结合肯定能取得好的效果,不过这部分工作目前没有多少人做,不知道为什么。
二、在训练算法上的改进
一提到算法的改进,涉及到更多的是理论的部分,难度比较大,目前已有的改进主要体现在两个方面:一是对非线性映射函数的改动,二是网络训练的无监督化
1、非线性映射函数改进
在CNN每个映射层之后其结果都会经过一个非线性函数处理,主要是调整映射结果的范围。传统CNN一般采用sigmoid函数或双曲正切函数(tanh)。后来稀疏表示兴起了,人们发现稀疏的东西效果都比较好,因此我们希望卷积层的映射结果也能尽量稀疏一点,更接近人的视觉反应。对非线性函数的一个最成功的改进就是纠正线性单元(Rectified Linear Units,ReLU),其作用是如果卷积计算的值小于0,则让其等于0,否则即保持原来的值不变。这种做法所谓是简单粗暴,但结果却能得到很好的稀疏性,实验说明一切。
2、训练算法的无监督化
其实训练算法的无监督化改进是CNN非常重要的一项改进,原因非常简单,深度学习需要海量数据,对海量数据进行标注可不是一项简单的工作,更不用说想表情、美丽度等等这种抽象标注了。CNN的无监督改进目前比较成功的只有少数几个方案,其中最具代表性的应该算是2011年J Ngiam等人提出稀疏滤波(Sparse filtering)算法,通过构建特征分布矩阵(feature distributions),对矩阵按照特征方向求解一次稀疏优化问题,同时对每个样本的特征进行L2范数归一化,最终得到一个具有样本分布稀疏性((Population Sparsity)、激活时间稀疏性(Lifetime Sparsity)以及高离散性(High Dispersal)等特点的样本分布矩阵,并指出可以通过将这些样本分布矩阵进行多层级联扩展,形成无监督深度学习模型。其实这有点像稀疏表示的一点延伸,说白了就是把卷积核改成稀疏字典了,舍弃了原来的BP算法,既然不依赖BP了,自然也就可以实现无监督。稀疏滤波算法在这里一两句话也说不清楚,在这里推荐两篇文献,一个是作者的原始文献,另一个是它的应用,这两篇文献在谷歌都可以下载得到,要是登陆谷歌出现困难的话再这里给大家提供一种稳定的登陆方法,一个月10元也不贵。
(1)Ngiam, Jiquan,Koh Pang Wei,Chen Zheng hao,Bhaskar Sonia,Ng Andrew Y. Sparse filtering,[C]. Advances in Neural Information Processing Systems 24: 25th Annual Conference on Neural Information Processing Systems,2011:1125-1133.
(2) Zhen Dong,Ming tao Pei,Yang He,Ting Liu,Yan mei Dong,Yun de Jia. Vehicle Type Classification Using Unsupervised Convolutional Neural Network,[C]. Pattern Recognition (ICPR), 2014 22nd International Conference on,2014:172-177.
FQ地址:http://honx.in/_VV72a4kWGgZlShi3
CNN作为深度学习中应用最为广泛的网络模型,最有影响力之一的应用应该算是香港理工大学王晓刚教授团队提出的DeepID人脸识别算法,其三代算法已经达到了99%,确实厉害。以上就是我这一个月来对CNN的理解了,欠妥地方欢迎大家指正,一起讨论,另外由于博客,对很多算法提出并未给出原始参考文献,需要查阅相关参考文献的可以留言给我。
标签:
原文地址:http://www.cnblogs.com/junling/p/4711459.html