标签:des Lucene style http color os
这是之前Lucene3.0生成的索引格式
a表

b表
 、
、
c.这是网上找的图片(因为上面的两张表的segment都是合并了的)
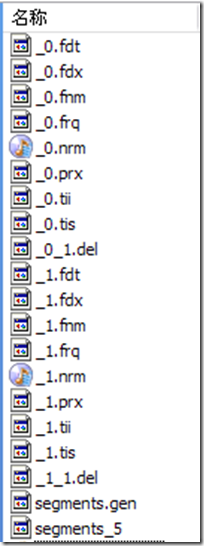
lucene4.9 建立的索引:

索引(Index):
在Lucene中一个索引是放在一个文件夹中的。
如上图,同一文件夹中的所有的文件构成一个Lucene索引。
段(Segment):
一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
如上图,具有相同前缀文件的属同一个段,图中共两个段 "_0" 和 "_1"。
segments.gen和segments_5是段的元数据文件,也即它们保存了段的属性信息。
文档(Document):
文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field):
一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里。
不同域的索引方式可以不同,在真正解析域的存储的时候,我们会详细解读。
词(Term):
词是索引的最小单位,是经过词法分析和语言处理后的字符串。
文件格式对应缩写
.fdt field data
.fdx field index
.fnm field name
.frq frequencies
.nrm norms
.prx ProxFile
.tii term info index
.tis term infos
segments.gen
segments_N
所谓正向信息:
所谓反向信息:
标签:des Lucene style http color os
原文地址:http://www.cnblogs.com/o-andy-o/p/3835502.html