标签:
1 ?argarg
? ?
muduo是由陈硕(http://www.cnblogs.com/Solstice)开发的一个Linux多线程网络库,采用了很多新的Linux特性(例如eventfd、timerfd)和GCC内置函数。其主要特点为:
调用了如下GCC提供的原子操作内建函数:
线程安全的队列,内部实现为std::deque<T>
与BlockingQueue类似,但是内部容器基于boost::circular_buffer<T>
pthread_cond的封装
CountDownLatch,类似发令枪,对condition的再包装,可以保证所有线程同时启动。
backtrace_symbols和backtrace的包装类
MutexLock:pthread_mutex_*的包装类
void*?Thread::startThread(void*?obj) { ??Thread*?thread?=?static_cast<Thread*>(obj); ??thread->runInThread();//对func_的包装,调用了func_ ??return?NULL; } ? ? void?Thread::runInThread() { ??tid_?=?CurrentThread::tid(); ??muduo::CurrentThread::t_threadName?=?name_.c_str(); ??try ??{ ????func_(); ????muduo::CurrentThread::t_threadName?=?"finished"; ??} ?… } ? ? typedef?boost::function<void?()>?ThreadFunc; Thread::Thread(const?ThreadFunc&?func,?const?string&?n):?started_(false),??pthreadId_(0),?tid_(0), ????//func_是实际上要在线程里执行的函数,以boost::function生成了一个函数对象??(functor) ????func_(func),?name_(n) { ??numCreated_.increment(); } |
依旧用pthread_get/setspecific(OP:为何不用__thread关键字?)。
线程单例模式,单例模板类的instance成员采用__thread关键字修饰,具有TLS属性。
void?ThreadPool::run(const?Task&?task) { ??//如果没有线程,直接执行task定义的函数 ??if?(threads_.empty()) ??{ ????task(); ??} ??else ??{ ????MutexLockGuard?lock(mutex_); ????//加入任务队列 ????queue_.push_back(task); ????cond_.notify(); ??} } ? ? ThreadPool::Task?ThreadPool::take() { ??MutexLockGuard?lock(mutex_); ??//?always?use?a?while-loop,?due?to?spurious?wakeup ??while?(queue_.empty()?&&?running_) ??{ ????//如果没有任务,则等待 ????cond_.wait(); ??} ??Task?task; ??if(!queue_.empty()) ??{ ????task?=?queue_.front(); ????queue_.pop_front(); ??} ??return?task; } ? ? //此函数就是线程函数 void?ThreadPool::runInThread() { ??try ??{ ????while?(running_) ????{ ??????????????//每个线程都从这里获取任务 ??????Task?task(take()); ??????if?(task) ??????{ ??????????????????//执行任务 ????????task(); ??????} ????} ??} ??… } |
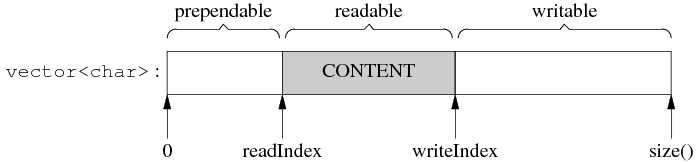
如果writable < datalen,但是prependable+writeable >= datalen,则将readIndex挪至最前,将prependable+writeable合并得到一个足够大的缓冲区(一般来说,这种情况是由于还有尚未读取的数据,readIndex向后移动位置造成的);如果prependable+writeable < datalen,说明全部可写区域之和也不足,则vertor::resize()扩展缓冲区。
void?makeSpace(size_t?len) { ????if?(writableBytes()?+?prependableBytes()?<?len?+?kCheapPrepend) ????{ ??????//?FIXME:?move?readable?data ??????buffer_.resize(writerIndex_+len); ????} ????else ????{ ??????//?move?readable?data?to?the?front,?make?space?inside?buffer ??????assert(kCheapPrepend?<?readerIndex_); ??????size_t?readable?=?readableBytes(); ??????std::copy(begin()+readerIndex_, ????????????????begin()+writerIndex_, ????????????????begin()+kCheapPrepend); ??????readerIndex_?=?kCheapPrepend; ??????writerIndex_?=?readerIndex_?+?readable; ??????assert(readable?==?readableBytes()); ????} } |
class Channel : boost::noncopyable { public: typedef boost::function<void()> EventCallback; typedef boost::function<void(Timestamp)> ReadEventCallback; private: EventLoop* loop_; //属于哪个reactor const int fd_; //关联的FD int events_; //关注事件 int revents_; //ready事件 bool eventHandling_; //当前正在处理事件 ReadEventCallback readCallback_; EventCallback writeCallback_; //如何写数据 EventCallback closeCallback_; //如何关闭链接 EventCallback errorCallback_; //如何处理错误 }; |
如果loop有事件发生,将触发handleEvent回调:
void Channel::handleEventWithGuard(Timestamp receiveTime) { eventHandling_ = true; if ((revents_ & POLLHUP) && !(revents_ & POLLIN)) { if (logHup_) { LOG_WARN << "Channel::handle_event() POLLHUP"; } if (closeCallback_) closeCallback_(); } ? ? if (revents_ & POLLNVAL) { LOG_WARN << "Channel::handle_event() POLLNVAL"; } ? ? if (revents_ & (POLLERR | POLLNVAL)) { if (errorCallback_) errorCallback_(); } if (revents_ & (POLLIN | POLLPRI | POLLRDHUP)) { if (readCallback_) readCallback_(receiveTime); } if (revents_ & POLLOUT) { if (writeCallback_) writeCallback_(); } eventHandling_ = false; } |
class EventLoop : boost::noncopyable { public: void loop(); void quit(); ? ? /// Runs callback immediately in the loop thread. /// It wakes up the loop, and run the cb. /// If in the same loop thread, cb is run within the function. /// Safe to call from other threads. void runInLoop(const Functor& cb); ? ? /// Queues callback in the loop thread. /// Runs after finish pooling. /// Safe to call from other threads. void queueInLoop(const Functor& cb); ? ? /// Runs callback at ‘time‘. /// Safe to call from other threads. TimerId runAt(const Timestamp& time, const TimerCallback& cb); ? ? /// Runs callback after @c delay seconds. /// Safe to call from other threads. TimerId runAfter(double delay, const TimerCallback& cb); ? ? /// Runs callback every @c interval seconds. /// Safe to call from other threads. TimerId runEvery(double interval, const TimerCallback& cb); ? ? /// Cancels the timer. /// Safe to call from other threads. void cancel(TimerId timerId); ? ? // internal usage void wakeup(); void updateChannel(Channel* channel); void removeChannel(Channel* channel); bool isInLoopThread() const { return threadId_ == CurrentThread::tid(); } private: void handleRead(); // waked up void doPendingFunctors(); typedef std::vector<Channel*> ChannelList; ? ? bool looping_; /* atomic */ bool quit_; /* atomic */ bool eventHandling_; /* atomic */ bool callingPendingFunctors_; /* atomic */ const pid_t threadId_; Timestamp pollReturnTime_; boost::scoped_ptr<Poller> poller_; boost::scoped_ptr<TimerQueue> timerQueue_; int wakeupFd_; // unlike in TimerQueue, which is an internal class, // we don‘t expose Channel to client. boost::scoped_ptr<Channel> wakeupChannel_; ChannelList activeChannels_; Channel* currentActiveChannel_; MutexLock mutex_; std::vector<Functor> pendingFunctors_; // @BuardedBy mutex_ }; ? ? __thread EventLoop* t_loopInThisThread = 0; |
t_loopInThisThread被定义为per thread的全局变量,并在EventLoop的构造函数中初始化:
? ?
epoll默认工作方式是LT。
? ?
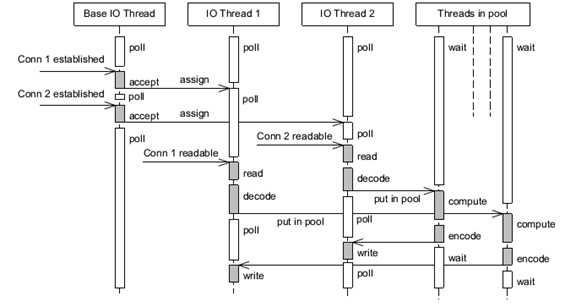
从这个muduo的工作模型来看,可以采用an IO thread per fd的形式处理各connection的读/写/encode/decode等工作,计算线程池中的线程在一个eventfd上监听,激活后就将connection作为参数与decoded packet一起传递到计算线程池中,并在计算完成后将结果直接写入IO thread的fd。并采用round-robin的方式选出下一个计算线程。
不同的解决方案:实际上这些线程是可以归并的,仅仅取决于任务的性质:IO密集型或是计算密集型。限制仅仅在于:出于避免过多thread context切换造成性能下降和资源对thread数量的约束,不能采用a thread per fd的模型,而是将fd分为若干组比较均衡的分配到IO线程中。
? ?
EventLoop的跨线程激活:
EventLoop::EventLoop() |
跨线程激活的函数是wakeUp:
void EventLoop::wakeup() |
一旦wakeup完成之后那么wakeUpFd_就是可读的,这样EventLoop就会被通知到并且立刻跳出epoll_wait开始处理。当然我们需要将这个wakeupFd_ 上面数据读出来,不然的话下一次又会被通知到,读取函数就是handleRead:
void EventLoop::handleRead() |
runInLoop和queueInLoop就是跨线程任务。
void EventLoop::runInLoop(const Functor& cb){ //如果这个函数在自己的线程调用,那么就可以立即执行 if (isInLoopThread()){ //如果是其他线程调用,那么加入到pendingFunctors里面去 queueInLoop(cb); //并且通知这个线程,有任务到来 wakeup();
/*被排上队之后如果是在自己线程并且正在执行pendingFunctors的话,那么就可以激活 if (isInLoopThread() && callingPendingFunctors_){ |
? ?
调用栈:
addTimer(const TimerCallback& cb,Timestamp when, double interval) => addTimerInLoop(Timer* timer) =>insert(timer)中:
typedef std::pair<Timestamp, Timer*> Entry; typedef std::set<Entry> TimerList; bool earliestChanged = false; Timestamp when = timer->expiration(); TimerList::iterator it = timers_.begin(); if (it == timers_.end() || when < it->first) { earliestChanged = true; } |
这里的微妙之处在于:如果是第一个定时器,begin()=end(),那么earliestChanged = true;会触发resetTimerfd:
void TimerQueue::addTimerInLoop(Timer* timer) { loop_->assertInLoopThread(); bool earliestChanged = insert(timer); ? ? if (earliestChanged) { //调用::timerfd_settime(timerfd, 0, &newValue, &oldValue)启动定时器 resetTimerfd(timerfd_, timer->expiration()); } } |
当定时器触发后:
void TimerQueue::handleRead() //我们可以知道有哪些计时器超时 std::vector<Entry> expired = getExpired(now); //对于这些超时的Timer,执行run()函数,对应也就是我们一开始注册的回调函数 it->second->run(); |
TcpConnection完成的工作就是当TCP连接建立之后处理socket的读写以及关闭。同样我们看看TcpConnection的结构
class TcpConnection : boost::noncopyable, public boost::enable_shared_from_this<TcpConnection> |
首先TcpConnection在初始化的时候会建立好channel。然后一旦TcpClient或者是TcpServer建立连接之后的话,那么调用TcpConnection::connectEstablished。这个函数内部的话就会将channel设置成为可读。一旦可读的话那么TcpConnection内部就会调用handleRead这个动作,内部托管了读取数据这个操作。 读取完毕之后然后交给MessageBack这个回调进行操作。如果需要写的话调用sendInLoop,那么会将message放在outputBuffer里面,并且设置可写。当可写的话TcpConnection内部就托管写,然后写完之后的话会发生writeCompleteCallback这个回调。托管的读写操作都是非阻塞的。如果希望断开的话调用 shutdown。解除这个连接的话那么可以调用TcpConnection::connectDestroyed,内部大致操作就是从reactor移除这个channel。
在TcpConnection这层并不知道一次需要读取多少个字节,这个是在上层进行消息拆分的。TcpConnection一次最多读取64K字节的内容,然后交给Upper App。后者决定这些内容是否足够,如果不够的话那么直接返回让Reactor继续等待读。 同样写的话内部也是会分多次写。这样就要求reactor内部必须使用水平触发而不是边缘触发。
这个类主要包装了TcpConnector的功能。
TcpClient::TcpClient(EventLoop* loop, } |
TcpServer::TcpServer(EventLoop* loop, |
同样是建立好acceptor这个对象然后设置好回调为TcpServer::newConnection,同时在外部设置好TcpConnection的各个回调。然后调用start来启动服务器,start 会调用acceptor::listen这个方法,一旦有连接建立的话那么会调用newConnection。下面是newConnection代码:
void TcpServer::newConnection(int sockfd, const InetAddress& peerAddr) |
对于服务端来说连接都被唯一化了然后映射为字符串放在connections_这个容器内部。threadPool_->getNextLoop()可以轮询地将取出每一个线程然后将 TcpConnection::connectEstablished轮询地丢到每个线程里面去完成。存放在connections_是有原因了,每个TcpConnection有唯一一个名字,这样Server 就可以根据TcpConnection来从自己内部移除链接了。在析构函数里面可以遍历connections_内容得到所有建立的连接并且逐一释放。
标签:
原文地址:http://www.cnblogs.com/CodeComposer/p/4716853.html