标签:
过路费
【问题描述】
在某个遥远的国家里,有 n 个城市。编号为 1,2,3,…,n。这个国家的政府修 建了 m 条双向道路,每条道路连接着两个城市。政府规定从城市 S 到城市 T 需 要收取的过路费为所经过城市之间道路长度的最大值。如:A 到 B 长度为 2,B 到 C 长度为 3,那么开车从 A 经过 B 到 C 需要上交的过路费为 3。 佳佳是个做生意的人,需要经常开车从任意一个城市到另外一个城市,因此 他需要频繁地上交过路费,由于忙于做生意,所以他无时间来寻找交过路费最低 的行驶路线。然而,当他交的过路费越多他的心情就变得越糟糕。作为秘书的你, 需要每次根据老板的起止城市,提供给他从开始城市到达目的城市,最少需要上 交多少过路费。
【输入文件】
第一行是两个整数 n 和 m,分别表示城市的个数以及道路的条数。 接下来 m 行,每行包含三个整数 a,b,w(1≤a,b≤n,0≤w≤10^9),表示 a 与 b 之间有一条长度为 w 的道路。 接着有一行为一个整数 q,表示佳佳发出的询问个数。 再接下来 q 行,每一行包含两个整数 S,T(1≤S,T≤n,S≠T), 表示开始城 市 S 和目的城市 T。
【输出文件】
输出文件共 q 行,每行一个整数,分别表示每个询问需要上交的最少过路费 用。输入数据保证所有的城市都是连通的。
【样例输入】
4 5
1 2 10
1 3 20
1 4 100
2 4 30
3 4 10
2
1 4
4 1
【样例输出】
20
20
【数据范围】
对于 30%的数据,满足 1≤ n≤1000,1≤m≤10000,1≤q≤100;
对于 50%的数据,满足 1≤ n≤10000,1≤m≤10000,1≤q≤10000;
对于 100%的数据,满足 1≤ n≤10000,1≤m≤100000,1≤q≤10000;
分析:
看到本题后,会先想到对于每对询问,二分两城市间道路路径最大值,将图中超过该最大值的边删去,求最短路径看两个城市是否是连通的,然后依据情况改变上下界。然而这样显然只能拿30分,我们需要想更高效的方法。
我们要先枚举询问,再对于每个询问用二分+最短路求解,这样很耗时间,如果能用较快的算法批量处理所有询问的答案,或者确定答案所在的范围就好了。于是我们想到最小生成树,你会发现在改图的最小生成树中,两点路径上的最大边是最小的,因为最小生成树要求两点间距离尽可能小,如果在a到b的两条路径的最大边分别为m,n,如果有m>n,则会选择n的那条而舍弃另外的路径。
由于最小生成树中两点间路径唯一,我们于是确定了两点间最大边最小的路径,然而问题来了,尽管知道这个最大边最小的路径,但我们怎么知道这条路径的最大边?将路径走一遍显然很慢,于是我们要进一步改进方法。我们发现已经求出最小生成树,本题就转化为求树上两点路径边的最大值,我们可以将边作为点,将其连接的两个点所在的子树作为新点的左右孩子,构成如下的图:
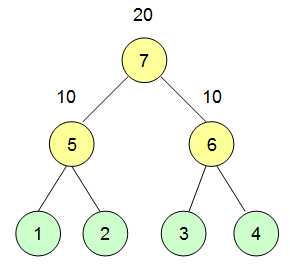
样例所给图的最小生成树构成的新图
建图要用并查集,按边权值的大小从小到大建边。由于从小到大建边,则其深度越大,点所代表的边权值越大,在此树中两点间路径只有一条,而它们的最近公共祖先必然在这个路径上且它深度在子树中最小,则一定是路径上所有边的最大值。于是本题被巧妙地转化为了LCA问题,然后用rmq解决即可。
LCA转rmq:先对树DFS,得到一个序列,并记录每个点的深度,用rmq求区间各点深度最小值,对于每个询问中的两点,我们可以知道它们在序列中的最先出现的位置,输出这两个位置形成区间的深度最小值即可,注意rmq时要记录深度最小点的编号。
代码:

program cost; var a,b,c:array[0..200000,1..2]of longint; v,w,p,q,r,d:array[0..200000]of longint; h:array[0..50,0..200000]of longint; f:array[0..20000]of longint; pl:array[0..200]of longint; n,i,m,x,y,tot,s,j,u,k,x1,y1,t:longint; function find(x:longint):longint; var i,j,k:longint; begin i:=x; j:=x; while f[i]<>i do i:=f[i]; while i<>j do begin k:=f[j]; f[j]:=i; j:=k; end; end; function max(x,y:longint):longint; begin if x>y then max:=x else max:=y; end; procedure qsort(l,r:longint); var i,j,mid,t:longint; begin i:=l; j:=r; mid:=v[(i+j) div 2]; repeat while v[i]<mid do inc(i); while mid<v[j] do dec(j); if i<=j then begin t:=v[i]; v[i]:=v[j]; v[j]:=t; t:=a[i,1]; a[i,1]:=a[j,1]; a[j,1]:=t; t:=a[i,2]; a[i,2]:=a[j,2]; a[j,2]:=t; inc(i);dec(j); end; until i>j; if i<r then qsort(i,r); if l<j then qsort(l,j); end; procedure dfs(x,y:longint); var i:longint; begin tot:=tot+1; q[tot]:=x; d[x]:=y; if c[x,1]>0 then begin dfs(c[x,1],y+1); tot:=tot+1; q[tot]:=x; end; if c[x,2]>0 then begin dfs(c[x,2],y+1); tot:=tot+1; q[tot]:=x; end; end; begin assign(input,‘cost.in‘); reset(input); assign(output,‘cost.out‘); rewrite(output); readln(n,m); for i:=1 to m do readln(a[i,1],a[i,2],v[i]); qsort(1,m); for i:=1 to n do f[i]:=i; for i:=1 to m do begin x:=find(a[i,1]); y:=find(a[i,2]); if x<>y then begin s:=s+1; b[s,1]:=a[i,1]; b[s,2]:=a[i,2]; w[s]:=v[i]; f[y]:=x; end; if s=n-1 then break; end; for i:=1 to n+s do f[i]:=i; for i:=1 to s do begin x:=find(b[i,1]); y:=find(b[i,2]); f[x]:=n+i; f[y]:=n+i; c[n+i,1]:=x; c[n+i,2]:=y; p[n+i]:=w[i]; end; dfs(n+s,1); k:=tot; for i:=1 to k do h[0,i]:=q[i]; pl[0]:=1; for i:=1 to trunc(ln(k)/ln(2)) do pl[i]:=pl[i-1]*2; for i:=1 to trunc(ln(k)/ln(2)) do for j:=1 to k+1-2*i do begin x:=h[i-1,j]; y:=h[i-1,j+pl[i-1]]; if d[x]<d[y] then h[i,j]:=x else h[i,j]:=y; end; for i:=1 to k do if r[q[i]]=0 then r[q[i]]:=i; readln(u); for i:=1 to u do begin readln(x,y); x:=r[x]; y:=r[y]; if x>y then begin t:=x; x:=y; y:=t; end; j:=trunc(ln(y-x+1)/ln(2)); x1:=h[j,x]; y1:=h[j,y-pl[j]+1]; if d[x1]<d[y1] then writeln(p[x1]) else writeln(p[y1]); end; close(input); close(output); end.
标签:
原文地址:http://www.cnblogs.com/qtyytq/p/4719258.html
