标签:
在purecpp社区的github组织中有一个协程库:https://github.com/topcpporg/cpp_features
近日有用户找到我,想要了解一下coroutine库在网络方面的性能,于是选取已入选标准库的boost.asio网络库的异步模型做横向对比。
在小包和利用多核方面,coroutine库的网络性能完爆asio异步模型,8线程处理小包时差距可达十几倍。
在大包+单线程的情况,coroutine库的网络比asio异步模型高的不是很多,在一些性能比较差的PC机上,甚至出现性能。
PS:之前做过一次对比测试,有人指出测试中并未开启O3优化,对Asio极为不公平
那个公布测试结果的blog已经删除,特此开启O3优化重新测试一遍,以正视听。
1.TCP协议,C/S是同一台物理机的两个进程,建立1000条连接
2.服务的是echo服务器,收到数据原样发回,客户端无限次发送指定大小的数据包,测试取样包大小为:4字节、32字节、128字节、1024字节、4096字节
3.分不同线程数测试,测试取样线程数为:单线程,2线程,4线程,8线程
4.用于对比测试的服务端程序分别为:
A)用Coroutine编写
B) 用boost.asio异步模型编写
5.使用同样的客户端程序,以减少干扰
5.测试环境是一台拥有2颗6核12线程CPU的物理机服务器,共24个逻辑线程,Linux系统版本为:CentOS 6.2。
(核心较少的PC机无法发挥coroutine的优势,测试结果差距会缩小)
测试结果图:
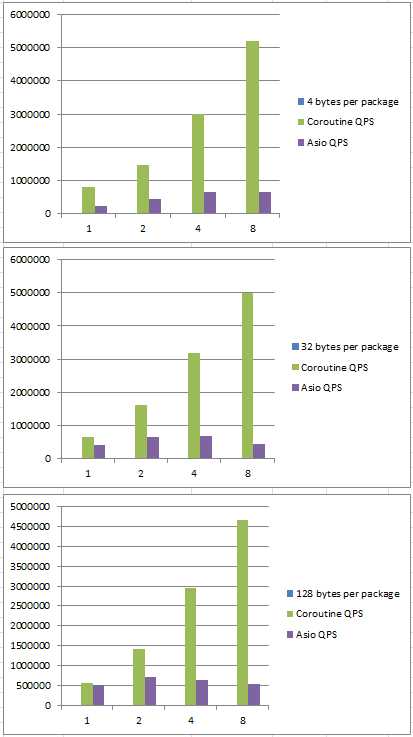
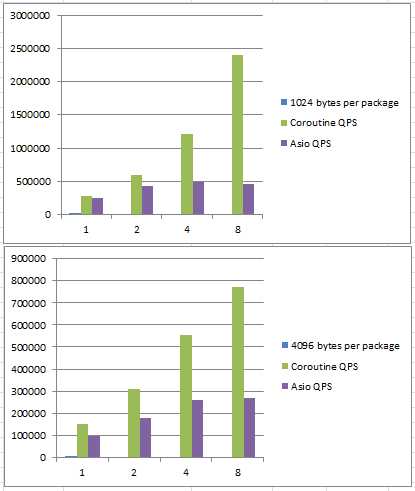
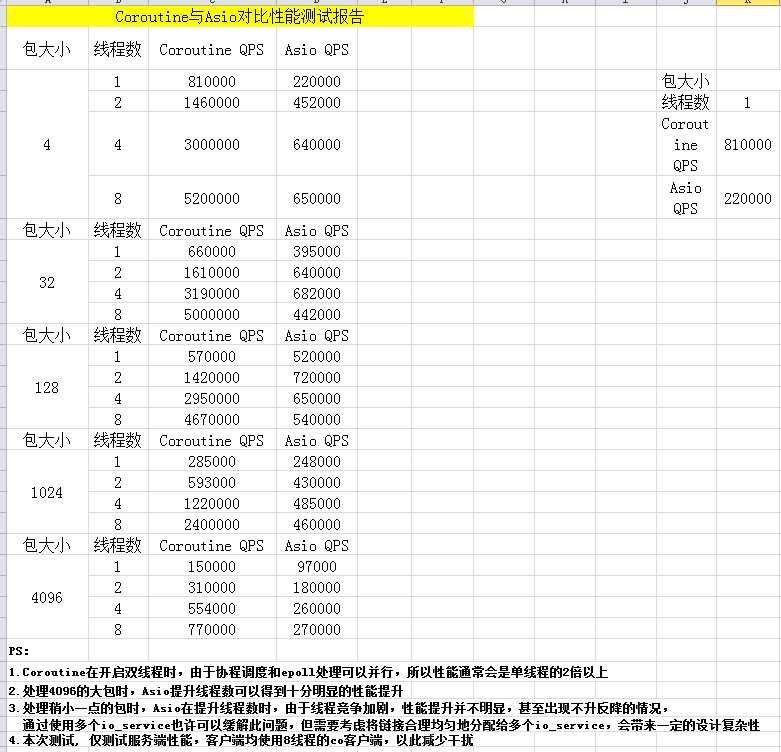
本次测试,并不能说明Asio的性能就一定比Coroutine库的网络性能更差,Asio是对系统调用的一层封装,很nice的设计,留给用户很大的优化余地;
花大力气去调优Asio,也是有希望达到甚至超越Coroutine库的网络性能的。
在实际使用Coroutine库时,我更加推荐的是Coroutine+Asio同步模型的使用方式,性能与开发效率二者可以兼得,而不是从系统调用写起!
本次测试所用服务端为git库中的benchmark/co_server.cpp和benchmark/asio/async_asio_server.cpp 客户端代码为: benchmark/co_client.cpp
Coroutine+Asio同步的使用示例在benchmark/asio_sync目录下
社区交流群:296561497
COROUTINE协程库:网络性能完爆ASIO异步模型(-O3测试)
标签:
原文地址:http://www.cnblogs.com/yyzybb/p/4726721.html