标签:
这节课的题目是Deep learning,个人以为说的跟Deep learning比较浅,跟autoencoder和PCA这块内容比较紧密。
林介绍了deep learning近年来受到了很大的关注:deep NNet概念很早就有,只是受限于硬件的计算能力和参数学习方法。
近年来深度学习长足进步的原因有两个:
1)pre-training技术获得了发展
2)regularization的技术获得了发展
接下来,林开始介绍autoencoder的motivation。
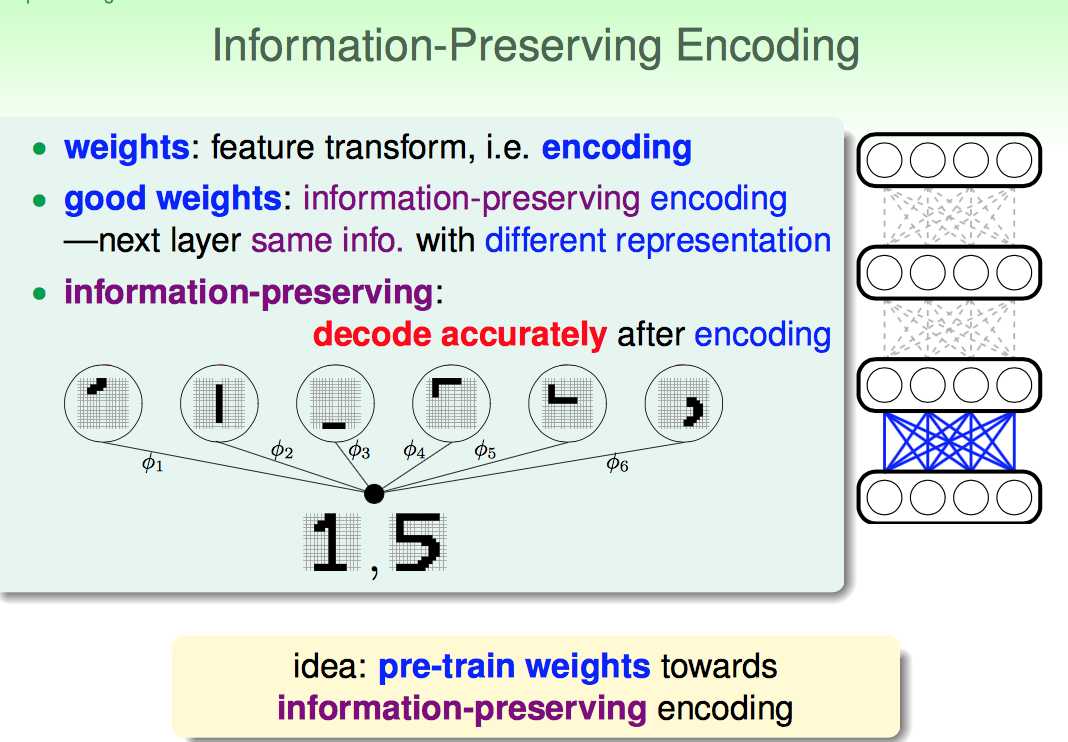
每过一个隐层,可以看做是做了一次对原始输入信息的转换。
什么是一个好的转换呢?就是因为这种转换而丢失较多的信息:即encoding之后,甚至可以用decoding的过程复原。
因此,在考虑deep NNet的参数学习的时候,如果在pre-training阶段采用类似autoencoding的方式,似乎是一个不错的选择。
如下,就是autoencoder的一个示例。简单来说,就是经过如下的单层神经网络结构后,输出跟输出十分接近。
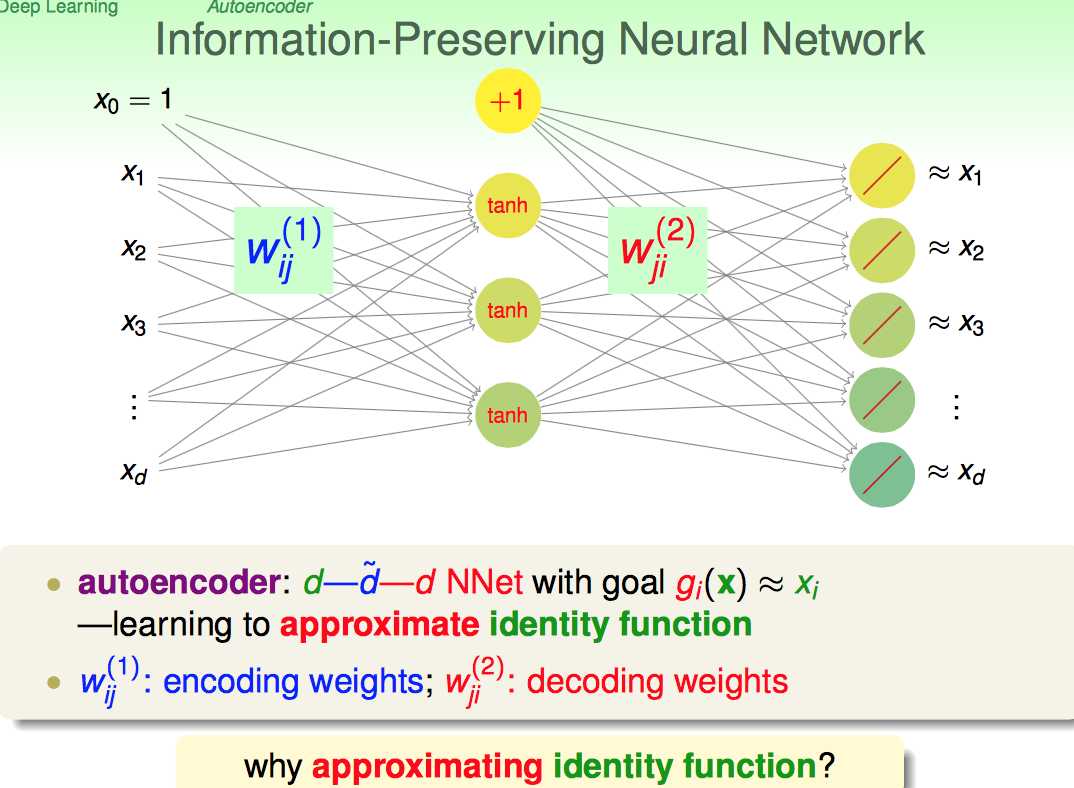
这种autoencoder对于机器学习来说有什么作用呢?

1)对于supervised learning来说:这种information-preserving NN的隐层结构+权重是一种对原始输入合理的转换,相当于在结构中学习了data的表达方式
2)对于unsupervised learning来说:可以作为density estimation或outlier detection。这个地方没太理解清,可能还是缺少例子。
autoencoder可以看成是单层的NN,可以用backprop求解;这里需要多加入一个正则化条件,wij(1)=wji(2)

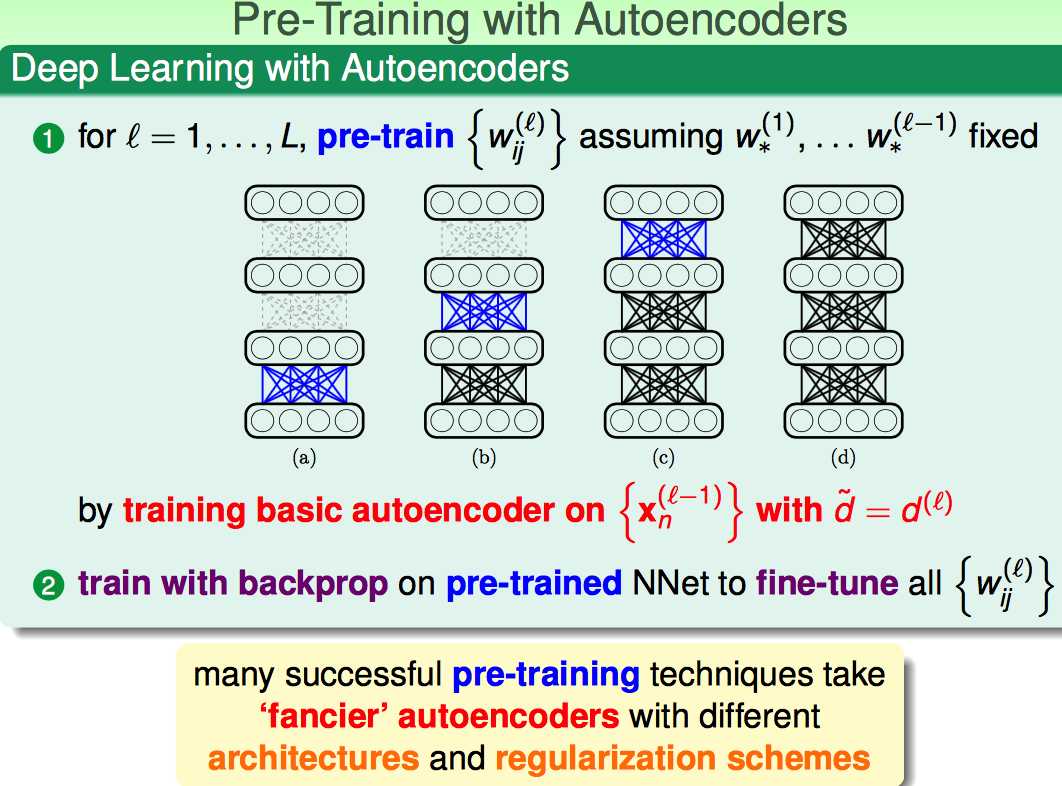
采用上述的basic autoencoder,可以作为Deep NNet的pre-training方式。
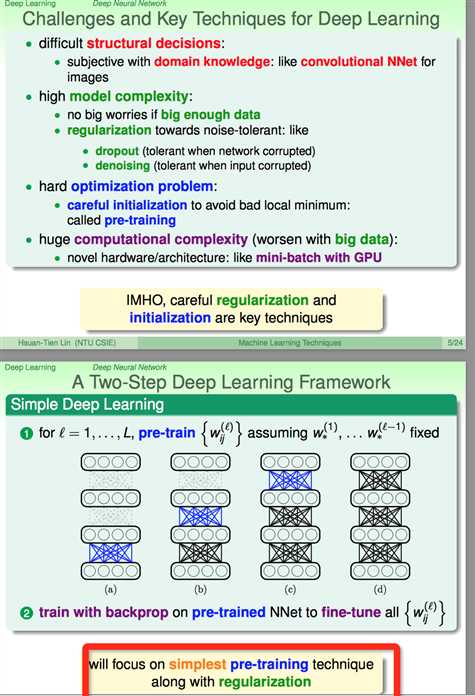
接下来,林开始关注Deep NNet的regularization的问题。
之前提到过的几种regularization方式都可以用(structural constraints、weight decay/elimination regularizers、early stopping),下面介绍一种新的regularization technique。

这种方式是:adding noise to data
简单来说,在训练autoencoder的时候加入高斯噪声,喂进去的输出端还是没有加入噪声的data;这样学出来的autoencoder就具备了抵抗noise的能力。
接下来,开始引入PCA相关的内容。
之前陈述的autoencoder可以归类到nonliner autoencoder(因为隐层输出需要经过tanh的操作,所以是nonlinear的)。
那么如果是linear autoencoder呢?(这里把隐层的bias单元去掉)

最后得到的linear autoencoder的表达式就是 :h(x)=WW‘x
由此,可以写出来error function

这是一个关于W的4阶的多项式,analytic solution不太好整。
于是林给出了下面的一种求解思路:

上述的核心在于:WW‘是实对称阵。
实对称阵有如下的性质:(http://wenku.baidu.com/view/1470f0e8856a561252d36f5d.html)

我们注意一下W这个矩阵:W是d×d‘维度的矩阵;WW‘是d×d维度的矩阵。
这里回顾一下矩阵的秩的性质:

因此,WW‘的秩最大就是d‘了(d代表数据的原始维度,d‘代表隐层神经元的个数,一般d‘<d)
WW‘的秩最大是d‘能得到这样的结论:WW‘至多有d‘个非零特征值→对角阵gamma对角线上最多有d‘个非零元素。
这里需要复习线性代数一个概念:
如果矩阵可以对角化,那么非零特征值的个数就等于矩阵的秩;如果矩阵不可以对角化,那么这个结论就不一定成立了。
这里我们说的WW‘是实对称阵,又因为实对称阵一定可以对角化,因此WW‘的非零特征值特殊就等于矩阵的秩。
通过上述的内容,WW‘x又可以看成是VgammaV‘x:
1)V‘x 可以看成是对原始输入rotate
2)gamma 可以看成是将0特征值的component的部分设成0,并且scale其余的部分
3)再转回来
因此,优化目标函数就出来了

这里可以不用管前面的V(这是正交变换的一个性质,正交变换不改变两个向量的内积,详情见https://zh.wikipedia.org/wiki/正交)
这样一来,问题就简化了:令I-gamma生出很多0,利用gamma对角线元素的自由度,往gamma里面塞1,最多塞d‘个1。剩下的事情交给V来搞定。

1)先把最小化转化为等价的最大化问题
2)用只有一个非零特征值的情况来考虑,Σv‘xx‘v s.t. v‘v=1
3)在上述最优化问题中,最好的v要满足error function和constraints在最优解的时候,他们的微分要平行。
4)再仔细观察下形式 Σxx‘v = lambdav 这里的v不就是XX‘的特征向量么
因此,最优化的v就是特征值最大的XX‘的特征向量。需要降到多少维的,就取前多少个特征向量。
林最后提了一句PCA,其实就是在进行上述步骤之前先对各个维度的向量均值化:

下面说一下PCA。
http://blog.codinglabs.org/articles/pca-tutorial.html
上面这篇日志非常好,基本完全解释了PCA的来龙去脉。
1)PCA的目的是对数据降维之后,还能尽量保持数据原有的信息(分得开。。。方差大。。。)
2)如果对原始数据各个维度做均值化的操作之后,方差&协方差,只用一个矩阵就表示出来了。

上述这段话看明白了,PCA的核心就有了:巧妙地把原始输入数据各个维度均值化之后,方差和协方差都放到一个矩阵里了。
优化的目标是:方差要大,协方差要小;这样的优化目标就等价于把协方差矩阵对角化。
实对称阵对角化是线性代数的基础知识:http://wenku.baidu.com/view/1470f0e8856a561252d36f5d.html
OK,PCA就大体上搞定了。
中途还看了stanford的http://ufldl.stanford.edu/wiki/index.php/PCA
脑子里冒出来一个想法:如果协方差矩阵是满秩的,并且不对数据降维,原来是多少维,还是多少维,那么变换前和变换后有啥区别呢?
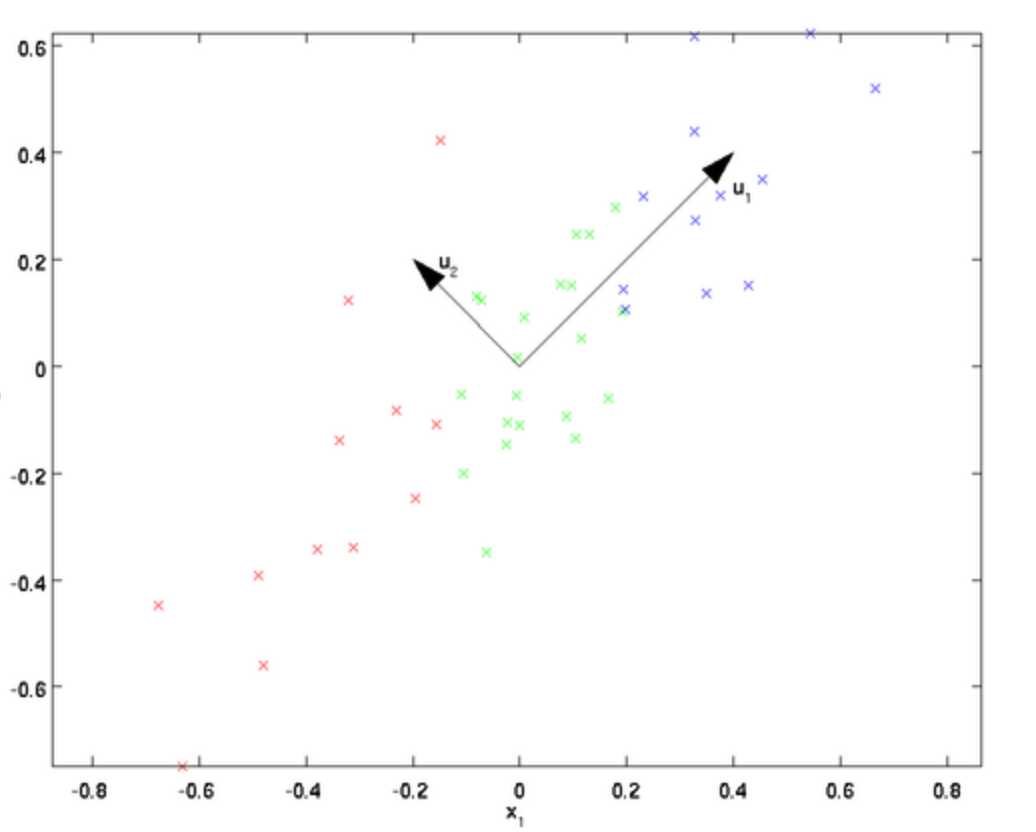
从式子上看,这种变化相当于把变换后的协方差矩阵搞成对角阵了。如果从几何上来看,比较下面两个图:
变换前:
变换后:
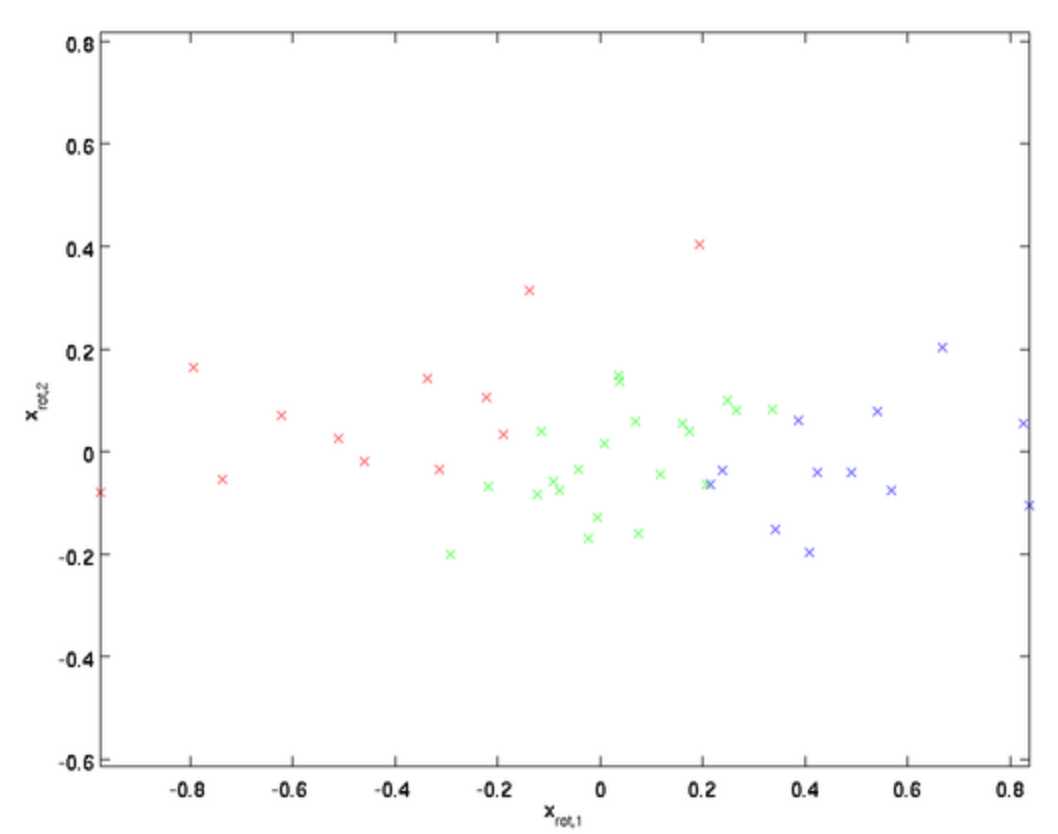
直观上看就是整体给“放平”了。
变化前:x1越大 x2也越大,反之亦然
变换后:由于给放平了,x1的大小与x2的大小没关系了
因此,变换后这种放平就消除了x1和x2的相关性了,也就是协方差矩阵的非对角元素给搞成0的效果。
标签:
原文地址:http://www.cnblogs.com/xbf9xbf/p/4727835.html