标签:
1.什么是全文检索
数据分类
结构化数据: 指具有固定格式或有限长度的数据, 如数据库, 元数据等
非结构化数据: 指没有固定格式或不定长的数据, 也叫全文数据
搜索分类
对结构化数据的搜索: 如对数据的数值、 时间等进行搜索, 对Windows的文件名、类型的搜索等
对非结构化数据的搜索: Linux下的grep命令等, 对非结构化的数据的搜索也叫对全文数据的搜索
全文数据的搜索分类
顺序扫描: 从头到尾的找, 如Like查找
索引扫描: 把非结构化数据中的内容提取出来一部分重新组织, 让它变的有结构化, 这部分提取出来的数据就叫做索引
2.Sphinx的步骤
1.索引创建
Sphinx即对记录进行分词, 并记录下词所在记录ID, 创建索引表
2.搜索索引
当请求来时, 会对请求的词进行分词, 查找索引表, 返回对应的记录ID
1.MySQL中创建文档(记录)
2.把文档传给分词组件(Tokenizer), 分词组件把文档分成一个个单独的单词(), 去除标点符号, 去除停词(stop word)(the, a, this等), 每种分词组件都会有一个停词集合, 分词组件处理完毕后我们便得到词元(Token)
3.把词元传给语言处理组件(Linguistic Processor), 将大写变为小写, 复数缩减为单数形式, 过去时等变为普通词根, 得到词(Term), 所以搜索 drove, 也会搜索到 drive
4.将词传给索引组件(Indexer), 利用得到的词创建一个字典, 对字典按字母顺序进行排序, 去除重复值
1).创建字典, 并排序, ID表示记录的ID
Term ID
allow 1
student 1
student 1
student 2
2).去除重复值
Term Document Frequency
allow 1 ->(指向一个链表, (Document ID 1, Frequency 1))
student 2 ->(指向一个链表, (Document ID 1, Frequency 2) -> (DocumentID 2, Frequency 1))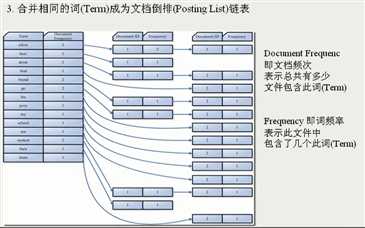
本例是在Windows下, 环境 Win32 + PHP5.3.8 + MySQL5.5.16
1.Sphinx简介
是一款基于SQL的高性能全文检索引擎, 主要优点有:
1).创建和重建索引迅速
2).大数据量时检索速度较快
3).为很多脚本语言设计了检索API(如PHP, Python, Perl, Ruby), 很方便地调用Sphinx的相关接口对数据库进行查询
4).为MySQL, PostgreSQL等设计了存储引擎插件, 可以很方便的使用
5).支持分布式搜索, 可以横向扩展系统性能
2.搜索方式的改变
旧有搜索方式
PHP -> MySQL
Sphinx搜索方式
PHP -> Sphinx <-> MySQL
3.到官网下载对应环境的安装包, 按照官方文档指定步骤进行安装
第一种方式是采用API调用, 我们可以使用PHP, Python, Perl, Ruby等编程语言的API函数进行查询, 这种方式不必重新编译MySQL, 模块间改动比较少, 相对灵活
第二种需要重新编译MySQL, 将Sphinx以插件的方式编译到MySQL中去, 这种方式对程序改动比较少, 仅仅需要改动SQL语句即可, 但前提是你的MySQL版本必须在5.1以上
1).下载对应安装包, 解压到指定目录, 以下以安装到D:\sphinx为例, 此时目录如下
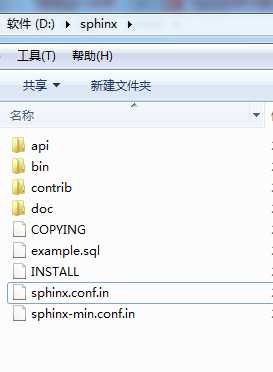
2).修改配置文件, 主要是配置数据库信息, sphinx.conf.in
3).安装Sphinx服务
D:\sphinx\bin>searchd --install --config D:\sphinx\sphinx.conf.in --servicename SphinxSearch
Linux下源码安装:
yum -y install make gcc g++ gcc-c++ libtool autoconf automake imake mysql-devel libxml2-devel expat-devel
./configure --prefix /usr/local/sphinx --with-mysql --enable-id64
make && make install
4.
indexer 用来生成索引数据
searchd 后台进程, 使用 indexer 生成的数据做查询
标签:
原文地址:http://www.cnblogs.com/JohnABC/p/4729724.html