标签:
1. Lucence基本概念
Lucence是一个java编写的全文检索类库,使用它可以为一个应用或者站点增加检索功能。
它通过增加内容到一个全文索引来完成检索功能。然后允许你基于这个索引去查询,返回结果,结果要么根据查询的相关度来排序要么根据任意字段如文档最后修改日期来排序。
增加到Lucence的内容可以来自多种数据源,如SQL/NOSQL 数据库,文件系统,甚至从站点上。
1.1 检索与索引
Lucence能快速的完成查询结果,是因为它不是直接搜索的文本,而是搜索一个索引。这类似于通过查询书后的索引的关键字来返回一本书的页面,而不是在书中的每页来搜索这个单词。
这种类型的索引称之为 反向搜索,因为它反转了一个页核心数据结构(页—>单词)到关键字核心的数据结构(单词à页)。
1.2 文档
在lucence中,一个文件是一个搜索和索引的单元,一个索引包含一个或者多个文档。
构建索引包含增加文档到一个IndexWriter,搜索包含从通过IndexSearcher来从一个索引中检索文档。
一个Lucence文档不必一定是一个常用英语中的单词文档。例如,如果你创建一个数据库的用户表的lucence索引,那么在索引中每个用户代表一个lucence文档。
1.3 字段
一个文档包含一个或者多个字段。一个字段仅仅是一个键值对。例如,通常在应用中的title字段。在title字段中,字段名称为title,值是该title包含的内容。
在lucence中构建索引也包含创建包含一个或者多个字段的文档,并且增加这些文档到IndexWriter。
1.4 检索
检索需要在一个索引已经构建完成后。它包含创建一个查询(Query)和处理该查询到IndexSearcher中,然后返回一组Hit。
1.5 查询(Query)
Lucence拥有自己的查询语言。Lucence查询语言支持用户指定查询的字段,字段的权重,使用联合查询如AND/OR/NOT和其它功能。
2. lucence如何工作?
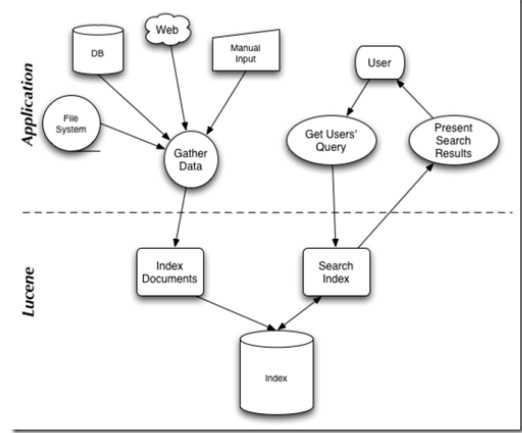
lucence工作原理
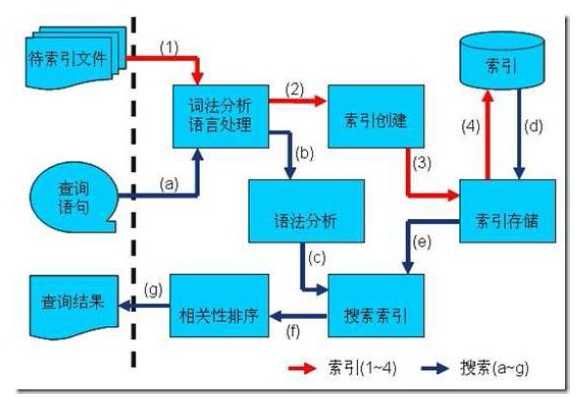
lucence架构如下:
2.1. 索引过程:
1) 有一系列被索引文件
2) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
3) 经过索引创建形成词典和反向索引表。
4) 通过索引存储将索引写入硬盘。
简单示例:
StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_40); Directory index = new RAMDirectory(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer); IndexWriter w = new IndexWriter(index, config); addDoc(w, "Lucene in Action", "193398817"); addDoc(w, "Lucene for Dummies", "55320055Z"); addDoc(w, "Managing Gigabytes", "55063554A"); addDoc(w, "The Art of Computer Science", "9900333X"); w.close();
其中,addDoc()方法是增加文档到索引中。
private static void addDoc(IndexWriter w, String title, String isbn) throws IOException { Document doc = new Document(); doc.add(new TextField("title", title, Field.Store.YES)); doc.add(new StringField("isbn", isbn, Field.Store.YES)); w.addDocument(doc); }
2.2 搜索过程:
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
搜索一般三步,如下:
2.2.1 构建查询语句
示例:
String querystr = args.length > 0 ? args[0] : "lucene"; Query q = new QueryParser(Version.LUCENE_40, "title", analyzer).parse(querystr);
2.2.2 搜索前10
int hitsPerPage = 10; IndexReader reader = IndexReader.open(index); IndexSearcher searcher = new IndexSearcher(reader); TopScoreDocCollector collector = TopScoreDocCollector.create(hitsPerPage, true); searcher.search(q, collector); ScoreDoc[] hits = collector.topDocs().scoreDocs;
2.2.3 展示结果
System.out.println("Found " + hits.length + " hits.");
for(int i=0;i<hits.length;++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("isbn") + "\t" + d.get("title"));
}
2.3 完整过程
import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.StringField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.queryparser.classic.ParseException; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopScoreDocCollector; import org.apache.lucene.store.Directory; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.Version; import java.io.IOException; public class HelloLucene { public static void main(String[] args) throws IOException, ParseException { // 0. Specify the analyzer for tokenizing text. // The same analyzer should be used for indexing and searching StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_40); // 1. create the index Directory index = new RAMDirectory(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer); IndexWriter w = new IndexWriter(index, config); addDoc(w, "Lucene in Action", "193398817"); addDoc(w, "Lucene for Dummies", "55320055Z"); addDoc(w, "Managing Gigabytes", "55063554A"); addDoc(w, "The Art of Computer Science", "9900333X"); w.close(); // 2. query String querystr = args.length > 0 ? args[0] : "lucene"; // the "title" arg specifies the default field to use // when no field is explicitly specified in the query. Query q = new QueryParser(Version.LUCENE_40, "title", analyzer).parse(querystr); // 3. search int hitsPerPage = 10; IndexReader reader = DirectoryReader.open(index); IndexSearcher searcher = new IndexSearcher(reader); TopScoreDocCollector collector = TopScoreDocCollector.create(hitsPerPage, true); searcher.search(q, collector); ScoreDoc[] hits = collector.topDocs().scoreDocs; // 4. display results System.out.println("Found " + hits.length + " hits."); for(int i=0;i<hits.length;++i) { int docId = hits[i].doc; Document d = searcher.doc(docId); System.out.println((i + 1) + ". " + d.get("isbn") + "\t" + d.get("title")); } // reader can only be closed when there // is no need to access the documents any more. reader.close(); } private static void addDoc(IndexWriter w, String title, String isbn) throws IOException { Document doc = new Document(); doc.add(new TextField("title", title, Field.Store.YES)); // use a string field for isbn because we don‘t want it tokenized doc.add(new StringField("isbn", isbn, Field.Store.YES)); w.addDocument(doc); } }
参考文献:
【1】http://www.lucenetutorial.com/
【2】 http://www.cnblogs.com/forfuture1978/archive/2010/06/13/1757479.html
标签:
原文地址:http://www.cnblogs.com/davidwang456/p/4730000.html