标签:
比如,在处理巨大的访问日志文件时,由于文件太大,我们可能希望按每天的日期将访问日志记录输出为每天日期下的文件。在处理专利数据集时,我们希望根据不同国家,将每个国家的专利数据记录输出到不同国家的文件目录中。Hadoop提供了MultipleOutputFormat类来帮助完成这一处理功能。
需求,输出结果:中国一组,美国一组,中国人一组
中国 我们
美国 他们
中国 123
中国人 善良
美国 USA
美国 在北美洲
注意:对于本程序,使用了KeyValueTextInputFormat作为输入类型。

package country; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class Multiples { public static void main(String[] args) throws Exception { System.setProperty("hadoop.home.dir", "F:\\JAVA\\hadoop-2.2.0"); Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(Multiples.class); job.setMapperClass(SBCMapper.class); /** * 使用KeyValueTextInputFormat作为输入类型 */ job.setInputFormatClass(KeyValueTextInputFormat.class); /** * 指定key和Value的分隔符【默认也是\t】 */ //conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t"); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setNumReduceTasks(0); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); /** * 注意在初始化时需要设置输出文件的名 * 另外名称,不支持中文名,仅支持英文字符 */ // 1.job 2.namedOutput 3.OutputFormat 4.keyClass 5.valueClass MultipleOutputs.addNamedOutput(job,"china",TextOutputFormat.class,Text.class,Text.class); MultipleOutputs.addNamedOutput(job,"USA",TextOutputFormat.class,Text.class,Text.class); MultipleOutputs.addNamedOutput(job,"CPerson",TextOutputFormat.class,Text.class,Text.class); KeyValueTextInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } //Map阶段 public static class SBCMapper extends Mapper<Text, Text, Text, Text>{ //声明多集合输出类型MultipleOutputs MultipleOutputs<Text, Text> mos=null; @Override //此方法在map任务执行前【只会执行一次】 protected void setup(Context context) throws IOException, InterruptedException { //初始化,只会执行一次 mos=new MultipleOutputs<Text, Text>(context); } @Override protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { String line=new String(key.getBytes(),0,key.getLength(),"utf-8"); if(line.equalsIgnoreCase("中国")){ mos.write("china", key, value); }else if (line.equalsIgnoreCase("美国")) { mos.write("USA", key, value); }else if (line.equalsIgnoreCase("中国人")) { mos.write("CPerson", key, value); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { //关闭输出流 mos.close(); } } }
运行结束,生成文件如下:
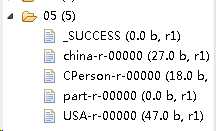
其中,USA-r-00000文件中内容:
美国 在北美洲
美国 USA
美国 他们
标签:
原文地址:http://www.cnblogs.com/skyl/p/4732300.html
