标签:style blog class code tar ext
1、摘要
STL文件是快速成型设备中常用的文件格式,随着3D打印技术的发展,STL格式文件的应用日益广泛。Python语言具有丰富和强大的类库,其语言简洁而清晰,因而Python语言越来越受欢迎。PLY是具名的LEX、YACC的Python版本,本文介绍了利用PLY模块对STL文件进行基本信息统计。
KeyWord:PLY、语法分析、词法分析、STL
计算机语言是计算机软件的系统的基础,经过几十年的发展,实现了从低级语言到高级语言的转变。原始的机器语言,到低级的汇编语言,它们虽然可以运行,但是也存在很多问题,比如在程序移植的过程中,往往会出现不兼容的情况。高级语言的出现,使得计算机程序设计语言不再过度地依赖特定的机器或环境,从高级语言翻译成机器可执行的语言就显得相当重要。构造一个高级语言编译器,需要构造相应的此法及语法分析器,PLY模块可以帮助我们实现词法及语法的分析。
PLY是LEX与YACC的Python版,包含了LEX与YACC的大部分特性。PLY模块包含两个独立的模块:lex.py和yacc.py。lex.py模块用来将输入字符通过一系列的正则表达式分解成标记序列,yacc.py通过一些上下文无关的文法来识别编程语言语法。yacc.py使用LR解析法,并使用LALR(1)算法(默认)或者SLR算法生成分析表。
Lex.py用来将输入字符串标记化。首先,将字符串分割成独立的标记(token),这些token由不同的名称表示,然后将名称和值组合起来形成一个二元组。例如:
tokens = (
‘NAME‘,‘NUMBER‘,
)
literals = [‘=‘,‘+‘,‘-‘,‘*‘,‘/‘, ‘(‘,‘)‘]
# Tokens
t_NAME = r‘[a-zA-Z_][a-zA-Z0-9_]*‘ #词法描述规则1
def t_NUMBER(t): #词法描述规则2
r‘\d+‘
t.value = int(t.value)
return t
t_ignore = " \t"
def t_newline(t):
r‘\n+‘
t.lexer.lineno += t.value.count("\n")
def t_error(t): #出错处理
print("Illegal character ‘%s‘" % t.value[0])
t.lexer.skip(1)
# Build the lexer
import ply.lex as lex
lex.lex()
其中tokens是强制词法单元类型列表的名称,强制描述词法规则的变量名格式为t_[TOKENNAME],在此例中有两种类型:NUMBER和NAME。NUMBER定义为\d+,匹配整数,NAME定义为a-zA-Z_][a-zA-Z0-9_],匹配一般标识符。词法描述规则中,规则1不能自定义操作,规则2可以自定义操作,规则2中的参数列表必须为单个参数,并且只能返回t,若不返回则表示丢弃该token。最后调用lex()即可完成词法分析。
YACC用于对语言进行语法分析。语法通常用BNF范式表达,用的分析技术是LALR分析法,LALR分析法是LR分析法的一种改进分析法。LR(K)分析,是指从左至右扫描和自底向上的语法分析,且在分析的每一步,只须根据分析栈当前已移进和归约出的全部文法符号,并至多再向前查看K个输入符号,就能确定相对于某一产生式左部符号的句柄是否已在分析栈的顶部形成,从而也就可以确定当前所应采取的分析动作 (是移进还是按某一产生式进行归约等)。例如:
简单算术表达式文法:
E : E + T
| E - T
| T
T : T * F
| T / F
| F
F : N
| ( E )
每个文法规则被描述为一个函数,这个函数的文档字符串描述了对应的上下文无关文法的规则。函数体用来实现规则的语义动作。每个函数都会接受一个参数p,这个参数是一个序列(sequence),包含了组成这个规则的所有的语法符号,p[i]是规则中的第i个语法符号。比如:
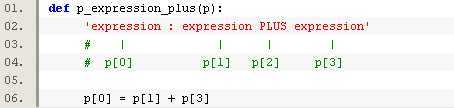
语法说明中的第一个为起始规则,也可以通过关键字参数传递给yacc以指定起始文法规则:
yacc.yacc(start = ‘rule_name‘)
STL文件是在计算机图形应用系统中,用于表示三角形网格的一种文件格式。STL文件凭借其简单的格式,在许多领域得到应用,特别是在快速成型系统中的应用。STL文件有两种:一种为ASCII格式,另一种为二进制格式。在这里只介绍ASCII格式的STL文件。
STL的文件结构如下:
solid filename //文件名
facet normal x y z //三角形法矢量
outer loop
vertex x y z //第一个点
vertex x y z //第二个点
vertex x y z //第三个点
endloop
endfacet
……..
endsolid filename
分析STL文件的文件结构,将词法单元类型分成5类:KEYWORD、RPARAM、LPARAM、NAME、NUMBER。词法采用正则表达式描述,详细定义分别如下:
KEYWORD:normal | outer | vertex
RPARAM:solid | facet | loop
LPARAM:endsolid | endfacet | endloop
NAME:[a-zA-Z_][a-zA-Z0-9_]*
NUMBER:(-?\d+)(\.\d+)?(e-?\d+)?
词法分析结果如下:
LexToken(RPARAM,‘solid‘,1,0)
LexToken(NAME,‘OBJECT‘,1,6)
LexToken(RPARAM,‘facet‘,2,15)
LexToken(KEYWORD,‘normal‘,2,21)
LexToken(NUMBER,-0.0,2,28)
LexToken(NUMBER,-1.0,2,31)
LexToken(NUMBER,0.0,2,34)
LexToken(KEYWORD,‘outer‘,3,40)
LexToken(RPARAM,‘loop‘,3,46)
LexToken(KEYWORD,‘vertex‘,4,57)
LexToken(NUMBER,-24.721731185913086,4,64)
LexToken(NUMBER,-6.938085079193115,4,84)
LexToken(NUMBER,0.0,4,104)
LexToken(KEYWORD,‘vertex‘,5,112)
LexToken(NUMBER,-21.674671173095703,5,119)
LexToken(NUMBER,-6.938085079193115,5,139)
……..
从词法分析结果中可以看出,扫描字符串的过程是从左至右依次进行。词法分析代码参见附录B
STL文件格式比较简单,其文法也相应比较简单。采用BNF范式描述STL文件的文件结构:
Rule 0 S‘ -> start
Rule 1 start -> RPARAM NAME facet LPARAM NAME
Rule 2 facet -> facet facet
Rule 3 facet -> RPARAM norm out LPARAM
Rule 4 norm -> KEYWORD NUMBER NUMBER NUMBER
Rule 5 out -> KEYWORD lp
Rule 6 lp -> RPARAM vertex LPARAM
Rule 7 vertex -> point point point
Rule 8 point -> KEYWORD NUMBER NUMBER NUMBER
在采用LALR分析法时,出现移近规约冲突:
(2) facet -> facet facet .
(2) facet -> facet . facet
(2) facet -> . facet facet
(3) facet -> . RPARAM norm out LPARAM
! shift/reduce conflict for RPARAM resolved as shift
LPARAM reduce using rule 2 (facet -> facet facet .)
RPARAM shift and go to state 4
! RPARAM [ reduce using rule 2 (facet -> facet facet .) ]
facet shift and go to state 9
默认采用移进解决这种移进规约冲突。
具体实现参见附录B
语法分析结果如下;
norm : KEYWORD NUMBER NUMBER NUMBER
point : KEYWORD NUMBER NUMBER NUMBER
point : KEYWORD NUMBER NUMBER NUMBER
point : KEYWORD NUMBER NUMBER NUMBER
vertex : point point point
lp : RPARAM vertex LPARAM
out : KEYWORD lp
facet : RPARAM norm out LPARAM
…….
facet : facet facet
facet : facet facet
facet : facet facet
…..
start : RPARAM NAME facet LPARAM NAME
从分析结果中可以看出语法分析中各规则归约顺序:首先是Rule 4,接着是3个Rule 8,然后Rule 7-> Rule 6-> Rule 5,跟着是Rule 3。如此分析完成一个三角形块。所有块分析完成后,应用Rule 2,最终应用Rule 1完成整个文件的分析。具体分析表参见附录C,分析过程参见附录D
在这里我们统计网格中的三角形个数和三角形的顶点数以及网格的表面积,虽然三角形顶点数可由三角形个数乘3得到,但是这里提供了语法分析时统计的手段。在每次对Rule 8进行规约时,顶点数加1,同时保存顶点用于表面积的计算;对Rule 3进行规约时,三角形个数加1,同时计算出三角形的面积,并对三角形面积进行累加。
由三角形的三个顶点A(x0,y0,z0),B(x1,y1,z1),C(x2,y2,z2)计算三角形的面积S。首先计算出三条边的长度:
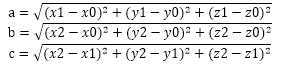
令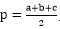 ,由海伦公式可得:
,由海伦公式可得: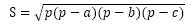
用计算机图形系统软件绘制一些三维文件,然后导出ASCII的STL格式文件作为测试用例。测试结果如下:
Cube.stl
---------------------------------------------------------------------------------------
object informatioin:
vertex: 84 facet: 28 surface area: 146.5441114077912
---------------------------------------------------------------------------------------
cy.stl
---------------------------------------------------------------------------------------
object informatioin:
vertex: 4740 facet: 1580 surface area: 1841.906043447056
---------------------------------------------------------------------------------------
shouji.stl
---------------------------------------------------------------------------------------
object informatioin:
vertex: 34542 facet: 11514 surface area: 1971.3863130454672
---------------------------------------------------------------------------------------
这三个测试用例都通过了测试。第一个、及第二个测试用例,内容较少,用于分析统计的时间可以忽略不计。第三个测试用例的容量较大,运行时有少许延时,若通过编译转换成C语言代码运行,可改善延时问题。
[1] 姚泽勤, 柏又青. 利用 LEX 及 YACC 实现嵌入式 SQL 分析器[J]. 航空计算技术, 2002, 32(1): 55-58.
[2] 肖任贤、张军舰、冯浩、潘海鹏, STL文件读取显示与操作, 陶瓷学报.2011(2)
[3] Lesk M E, Schmidt E. lex: A lexical analyzer generator[M]. Bell Laboratories, 1987.
[4] Johnson S C. Yacc: Yet another compiler-compiler[M]. Murray Hill, NJ: Bell Laboratories, 1975.
[5] Beazley D M. Ply, python lex-yacc (2001)[J]. UR L http://www. dabeaz. com/ply.
[6] Amiguet M. Teaching compilers with python[J]. 2010.

1 #------------------------------------------------------------- 2 #stlcount.py 3 # 4 # STL文件信息统计 5 #------------------------------------------------------------- 6 import math 7 8 #小三角片数 9 c_facet=0 10 11 #表面积 12 s_all=0 13 14 #点数 15 c_vertex=0 16 17 18 #保存三个点 19 v_points=[] 20 21 b_print_yacc=False 22 b_print_lex=False 23 24 #初始化 25 def init_countstl(): 26 global c_facet,s_all,c_vertex,v_points 27 c_facet=0 28 s_all=0 29 c_vertex=0 30 v_points=[] 31 32 def display(a,b,c): 33 print("--------------------------------------------------------------------------") 34 print("object informatioin:") 35 print("\tvertex: "+str(a)+"\tfacet: "+str(b)+"\tsurface area: "+str(c)) 36 print("--------------------------------------------------------------------------") 37 38 def cal_area(p0,p1,p2): 39 A=[0,0,0] 40 B=[0,0,0] 41 C=[0,0,0] 42 A[0]=p1[0]-p0[0] 43 B[0]=p2[0]-p0[0] 44 C[0]=p2[0]-p1[0] 45 A[1]=p1[1]-p0[1] 46 B[1]=p2[1]-p0[1] 47 C[1]=p2[1]-p1[1] 48 A[2]=p1[2]-p0[2] 49 B[2]=p2[2]-p0[2] 50 C[2]=p2[2]-p1[2] 51 a=math.sqrt(A[0]**2+A[1]**2+A[2]**2) 52 b=math.sqrt(B[0]**2+B[1]**2+B[2]**2) 53 c=math.sqrt(C[0]**2+C[1]**2+C[2]**2) 54 p=(a+b+c)/2.0 55 return math.sqrt(p*(p-a)*(p-b)*(p-c)) 56
1 # ----------------------------------------------------------------------------- 2 # stl.py 3 # 4 # A simple calculator with variables. This is from O‘Reilly‘s 5 # "Lex and Yacc", p. 63. 6 # ----------------------------------------------------------------------------- 7 8 import stlcount as cn 9 10 #------------------------------------------------------------------------------ 11 #词法分析 12 #------------------------------------------------------------------------------ 13 14 15 16 tokens = ( 17 ‘KEYWORD‘,‘RPARAM‘,‘LPARAM‘,‘NAME‘,‘NUMBER‘ 18 ) 19 20 #literals = [‘=‘,‘+‘,‘-‘,‘*‘,‘/‘, ‘(‘,‘)‘] 21 22 # Tokens 23 24 def t_KEYWORD(t): 25 r"normal | outer | vertex" 26 return t 27 28 def t_RPARAM(t): 29 r"solid | facet | loop" 30 return t 31 32 def t_LPARAM(t): 33 r"endsolid | endfacet | endloop" 34 return t 35 36 def t_NAME(t): 37 r‘[a-zA-Z_][a-zA-Z0-9_]*‘ 38 return t 39 40 def t_NUMBER(t): 41 r‘(-?\d+)(\.\d+)?(e-?\d+)?‘ 42 t.value = float(t.value) 43 return t 44 45 t_ignore = " \t" 46 47 def t_newline(t): 48 r‘\n+‘ 49 t.lexer.lineno += t.value.count("\n") 50 51 def t_error(t): 52 print("Illegal character ‘%s‘" % t.value[0]) 53 t.lexer.skip(1) 54 55 # Build the lexer 56 import ply.lex as lex 57 lexer=lex.lex() 58 59 #====================================================================== 60 61 def p_start(p): 62 r‘start : RPARAM NAME facet LPARAM NAME‘ 63 if cn.b_print_yacc: 64 print("start : RPARAM NAME facet LPARAM NAME") 65 cn.display(cn.c_vertex,cn.c_facet,cn.s_all) 66 67 def p_facet(p): 68 r‘facet : facet facet‘ 69 if cn.b_print_yacc: 70 print(‘facet : facet facet‘) 71 72 def p_facet1(p): 73 r‘facet : RPARAM norm out LPARAM‘ 74 if cn.b_print_yacc: 75 print(‘facet : RPARAM norm out LPARAM‘) 76 cn.c_facet=cn.c_facet+1 77 s_single=cn.cal_area(cn.v_points[0],cn.v_points[1],cn.v_points[2]) 78 if s_single<0: 79 print("****************************ERROR*******************************") 80 cn.s_all=cn.s_all+s_single 81 if cn.b_print_yacc: 82 print("area:",end=‘\t‘) 83 print(cn.s_all) 84 cn.v_points=[] 85 86 87 def p_norm(p): 88 r‘norm : KEYWORD NUMBER NUMBER NUMBER‘ 89 if cn.b_print_yacc: 90 print("norm : KEYWORD NUMBER NUMBER NUMBER") 91 92 def p_out(p): 93 r‘out : KEYWORD lp‘ 94 if cn.b_print_yacc: 95 print("out : KEYWORD lp") 96 97 def p_lp(p): 98 r‘lp : RPARAM vertex LPARAM‘ 99 if cn.b_print_yacc: 100 print(‘lp : RPARAM vertex LPARAM‘) 101 102 def p_vertex(p): 103 r‘vertex : point point point‘ 104 if cn.b_print_yacc: 105 print(‘vertex : point point point‘) 106 107 def p_point(p): 108 r‘point : KEYWORD NUMBER NUMBER NUMBER‘ 109 if cn.b_print_yacc: 110 print(‘point : KEYWORD NUMBER NUMBER NUMBER‘) 111 cn.c_vertex=cn.c_vertex+1 112 cn.v_points.append([p[2],p[3],p[4]]) 113 114 115 def p_error(p): 116 if p: 117 print("Syntax error at ‘%s‘" % p.value) 118 else: 119 print("Syntax error at EOF") 120 121 import ply.yacc as yacc 122 yacc.yacc() 123 124 125 def stl_exec(s,blex=False,byacc=False): 126 cn.b_print_lex=blex 127 cn.b_print_yacc=byacc 128 cn.init_countstl() 129 if cn.b_print_lex: 130 print("----------------------------------------------------------------------") 131 print("\t\tlex") 132 print("----------------------------------------------------------------------") 133 lexer.input(s) 134 for st in lexer: 135 print(st) 136 if cn.b_print_yacc: 137 print("----------------------------------------------------------------------") 138 print("\t\tyacc") 139 print("----------------------------------------------------------------------") 140 yacc.parse(s)
1 # parsetab.py 2 # This file is automatically generated. Do not edit. 3 _tabversion = ‘3.2‘ 4 5 _lr_method = ‘LALR‘ 6 7 _lr_signature = b‘|:{\xf5@\x08\xce\xd8d\x055eAN\xff\x13‘ 8 9 _lr_action_items = {‘NAME‘:([1,8,],[3,13,]),‘KEYWORD‘:([4,7,15,18,21,24,27,],[6,11,19,-4,19,19,-8,]),‘NUMBER‘:([6,10,14,19,22,25,],[10,14,18,22,25,27,]),‘LPARAM‘:([5,9,12,16,17,20,23,26,27,],[8,-2,17,-5,-3,23,-6,-7,-8,]),‘$end‘:([2,13,],[0,-1,]),‘RPARAM‘:([0,3,5,9,11,17,],[1,4,4,4,15,-3,]),} 10 11 _lr_action = { } 12 for _k, _v in _lr_action_items.items(): 13 for _x,_y in zip(_v[0],_v[1]): 14 if not _x in _lr_action: _lr_action[_x] = { } 15 _lr_action[_x][_k] = _y 16 del _lr_action_items 17 18 _lr_goto_items = {‘norm‘:([4,],[7,]),‘start‘:([0,],[2,]),‘vertex‘:([15,],[20,]),‘point‘:([15,21,24,],[21,24,26,]),‘facet‘:([3,5,9,],[5,9,9,]),‘lp‘:([11,],[16,]),‘out‘:([7,],[12,]),} 19 20 _lr_goto = { } 21 for _k, _v in _lr_goto_items.items(): 22 for _x,_y in zip(_v[0],_v[1]): 23 if not _x in _lr_goto: _lr_goto[_x] = { } 24 _lr_goto[_x][_k] = _y 25 del _lr_goto_items 26 _lr_productions = [ 27 ("S‘ -> start","S‘",1,None,None,None), 28 (‘start -> RPARAM NAME facet LPARAM NAME‘,‘start‘,5,‘p_start‘,‘E:\\PY\\stl.py‘,65), 29 (‘facet -> facet facet‘,‘facet‘,2,‘p_facet‘,‘E:\\PY\\stl.py‘,71), 30 (‘facet -> RPARAM norm out LPARAM‘,‘facet‘,4,‘p_facet1‘,‘E:\\PY\\stl.py‘,76), 31 (‘norm -> KEYWORD NUMBER NUMBER NUMBER‘,‘norm‘,4,‘p_norm‘,‘E:\\PY\\stl.py‘,91), 32 (‘out -> KEYWORD lp‘,‘out‘,2,‘p_out‘,‘E:\\PY\\stl.py‘,96), 33 (‘lp -> RPARAM vertex LPARAM‘,‘lp‘,3,‘p_lp‘,‘E:\\PY\\stl.py‘,101), 34 (‘vertex -> point point point‘,‘vertex‘,3,‘p_vertex‘,‘E:\\PY\\stl.py‘,106), 35 (‘point -> KEYWORD NUMBER NUMBER NUMBER‘,‘point‘,4,‘p_point‘,‘E:\\PY\\stl.py‘,111), 36 ]
1 Created by PLY version 3.4 (http://www.dabeaz.com/ply) 2 3 Grammar 4 5 Rule 0 S‘ -> start 6 Rule 1 start -> RPARAM NAME facet LPARAM NAME 7 Rule 2 facet -> facet facet 8 Rule 3 facet -> RPARAM norm out LPARAM 9 Rule 4 norm -> KEYWORD NUMBER NUMBER NUMBER 10 Rule 5 out -> KEYWORD lp 11 Rule 6 lp -> RPARAM vertex LPARAM 12 Rule 7 vertex -> point point point 13 Rule 8 point -> KEYWORD NUMBER NUMBER NUMBER 14 15 Terminals, with rules where they appear 16 17 KEYWORD : 4 5 8 18 LPARAM : 1 3 6 19 NAME : 1 1 20 NUMBER : 4 4 4 8 8 8 21 RPARAM : 1 3 6 22 error : 23 24 Nonterminals, with rules where they appear 25 26 facet : 1 2 2 27 lp : 5 28 norm : 3 29 out : 3 30 point : 7 7 7 31 start : 0 32 vertex : 6 33 34 Parsing method: LALR 35 36 state 0 37 38 (0) S‘ -> . start 39 (1) start -> . RPARAM NAME facet LPARAM NAME 40 41 RPARAM shift and go to state 1 42 43 start shift and go to state 2 44 45 state 1 46 47 (1) start -> RPARAM . NAME facet LPARAM NAME 48 49 NAME shift and go to state 3 50 51 52 state 2 53 54 (0) S‘ -> start . 55 56 57 58 state 3 59 60 (1) start -> RPARAM NAME . facet LPARAM NAME 61 (2) facet -> . facet facet 62 (3) facet -> . RPARAM norm out LPARAM 63 64 RPARAM shift and go to state 4 65 66 facet shift and go to state 5 67 68 state 4 69 70 (3) facet -> RPARAM . norm out LPARAM 71 (4) norm -> . KEYWORD NUMBER NUMBER NUMBER 72 73 KEYWORD shift and go to state 7 74 75 norm shift and go to state 6 76 77 state 5 78 79 (1) start -> RPARAM NAME facet . LPARAM NAME 80 (2) facet -> facet . facet 81 (2) facet -> . facet facet 82 (3) facet -> . RPARAM norm out LPARAM 83 84 LPARAM shift and go to state 8 85 RPARAM shift and go to state 4 86 87 facet shift and go to state 9 88 89 state 6 90 91 (3) facet -> RPARAM norm . out LPARAM 92 (5) out -> . KEYWORD lp 93 94 KEYWORD shift and go to state 11 95 96 out shift and go to state 10 97 98 state 7 99 100 (4) norm -> KEYWORD . NUMBER NUMBER NUMBER 101 102 NUMBER shift and go to state 12 103 104 105 state 8 106 107 (1) start -> RPARAM NAME facet LPARAM . NAME 108 109 NAME shift and go to state 13 110 111 112 state 9 113 114 (2) facet -> facet facet . 115 (2) facet -> facet . facet 116 (2) facet -> . facet facet 117 (3) facet -> . RPARAM norm out LPARAM 118 119 ! shift/reduce conflict for RPARAM resolved as shift 120 LPARAM reduce using rule 2 (facet -> facet facet .) 121 RPARAM shift and go to state 4 122 123 ! RPARAM [ reduce using rule 2 (facet -> facet facet .) ] 124 125 facet shift and go to state 9 126 127 state 10 128 129 (3) facet -> RPARAM norm out . LPARAM 130 131 LPARAM shift and go to state 14 132 133 134 state 11 135 136 (5) out -> KEYWORD . lp 137 (6) lp -> . RPARAM vertex LPARAM 138 139 RPARAM shift and go to state 16 140 141 lp shift and go to state 15 142 143 state 12 144 145 (4) norm -> KEYWORD NUMBER . NUMBER NUMBER 146 147 NUMBER shift and go to state 17 148 149 150 state 13 151 152 (1) start -> RPARAM NAME facet LPARAM NAME . 153 154 $end reduce using rule 1 (start -> RPARAM NAME facet LPARAM NAME .) 155 156 157 state 14 158 159 (3) facet -> RPARAM norm out LPARAM . 160 161 RPARAM reduce using rule 3 (facet -> RPARAM norm out LPARAM .) 162 LPARAM reduce using rule 3 (facet -> RPARAM norm out LPARAM .) 163 164 165 state 15 166 167 (5) out -> KEYWORD lp . 168 169 LPARAM reduce using rule 5 (out -> KEYWORD lp .) 170 171 172 state 16 173 174 (6) lp -> RPARAM . vertex LPARAM 175 (7) vertex -> . point point point 176 (8) point -> . KEYWORD NUMBER NUMBER NUMBER 177 178 KEYWORD shift and go to state 19 179 180 vertex shift and go to state 18 181 point shift and go to state 20 182 183 state 17 184 185 (4) norm -> KEYWORD NUMBER NUMBER . NUMBER 186 187 NUMBER shift and go to state 21 188 189 190 state 18 191 192 (6) lp -> RPARAM vertex . LPARAM 193 194 LPARAM shift and go to state 22 195 196 197 state 19 198 199 (8) point -> KEYWORD . NUMBER NUMBER NUMBER 200 201 NUMBER shift and go to state 23 202 203 204 state 20 205 206 (7) vertex -> point . point point 207 (8) point -> . KEYWORD NUMBER NUMBER NUMBER 208 209 KEYWORD shift and go to state 19 210 211 point shift and go to state 24 212 213 state 21 214 215 (4) norm -> KEYWORD NUMBER NUMBER NUMBER . 216 217 KEYWORD reduce using rule 4 (norm -> KEYWORD NUMBER NUMBER NUMBER .) 218 219 220 state 22 221 222 (6) lp -> RPARAM vertex LPARAM . 223 224 LPARAM reduce using rule 6 (lp -> RPARAM vertex LPARAM .) 225 226 227 state 23 228 229 (8) point -> KEYWORD NUMBER . NUMBER NUMBER 230 231 NUMBER shift and go to state 25 232 233 234 state 24 235 236 (7) vertex -> point point . point 237 (8) point -> . KEYWORD NUMBER NUMBER NUMBER 238 239 KEYWORD shift and go to state 19 240 241 point shift and go to state 26 242 243 state 25 244 245 (8) point -> KEYWORD NUMBER NUMBER . NUMBER 246 247 NUMBER shift and go to state 27 248 249 250 state 26 251 252 (7) vertex -> point point point . 253 254 LPARAM reduce using rule 7 (vertex -> point point point .) 255 256 257 state 27 258 259 (8) point -> KEYWORD NUMBER NUMBER NUMBER . 260 261 KEYWORD reduce using rule 8 (point -> KEYWORD NUMBER NUMBER NUMBER .) 262 LPARAM reduce using rule 8 (point -> KEYWORD NUMBER NUMBER NUMBER .) 263 264 WARNING: 265 WARNING: Conflicts: 266 WARNING: 267 WARNING: shift/re
1 import sys 2 largv=len(sys.argv) 3 bLex=False 4 bYacc=False 5 if largv==1: 6 filename=input(‘please input the name of file\n>>>‘) 7 else: 8 if largv>1: 9 filename=sys.argv[1] 10 if largv>2: 11 if sys.argv[2]==‘L‘: 12 bLex=True 13 bYacc=False 14 else: 15 if sys.argv[2]==‘Y‘: 16 bLex=False 17 bYacc=True 18 else: 19 if sys.argv[2]==‘YL‘ or sys.argv[2]==‘LY‘: 20 bLex=True 21 bYacc=True 22 def run(): 23 try: 24 file=open(filename).read() 25 import stl 26 stl.stl_exec(file,bLex,bYacc) 27 except: 28 print(‘OPENFILE ERROR!‘) 29 exit() 30 31 run()
基于PLY的STL文件基本信息统计方法,布布扣,bubuko.com
标签:style blog class code tar ext
原文地址:http://www.cnblogs.com/bacazy/p/3706240.html
