标签:
转帖:http://stark-summer.iteye.com/blog/2214776
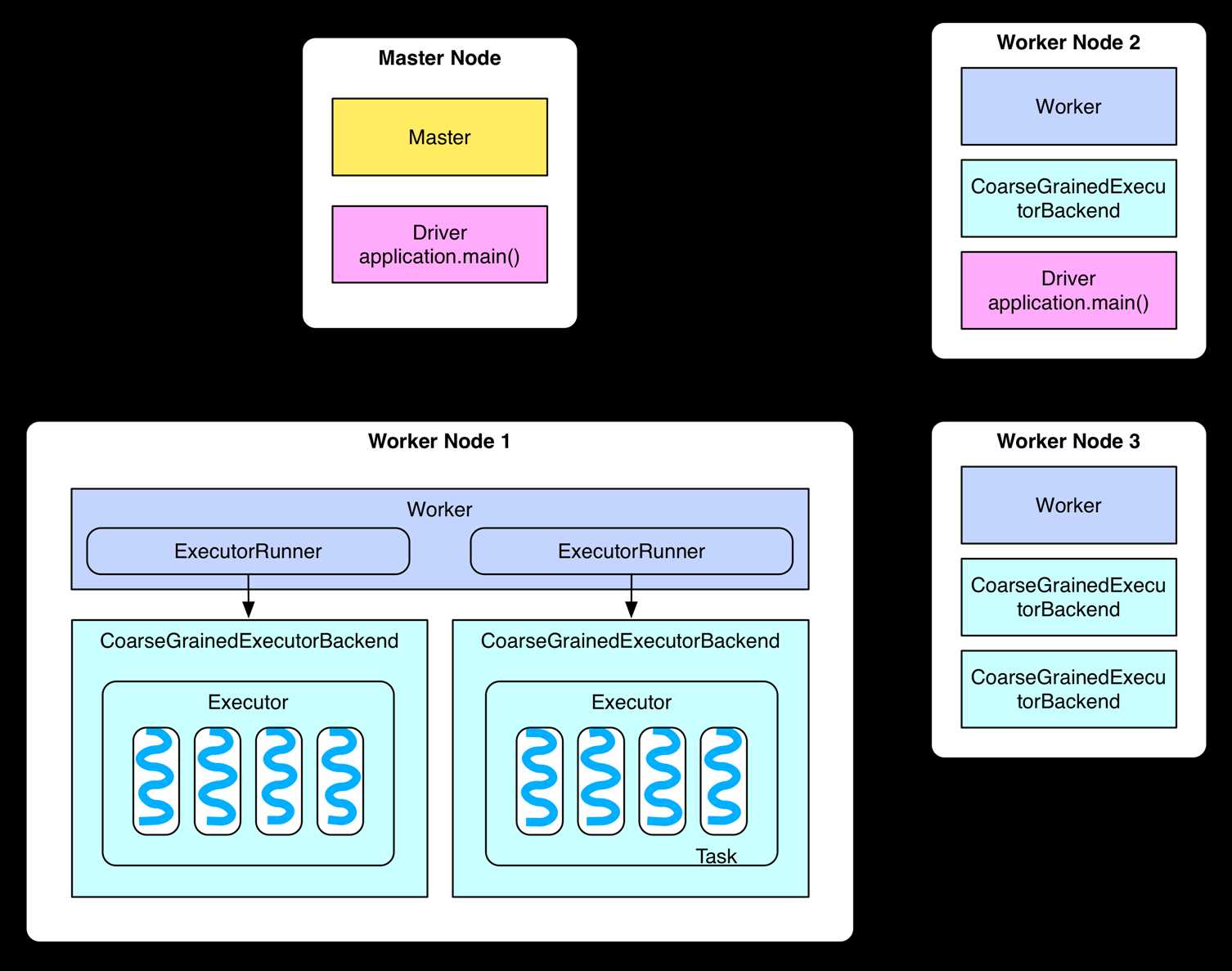
但是要注意,当我们配置完多master后,启动在提交任务或者启动spark-shell时,需要增加MASTER=spark://master001:7077,master002:7077
最简单的wordcount:
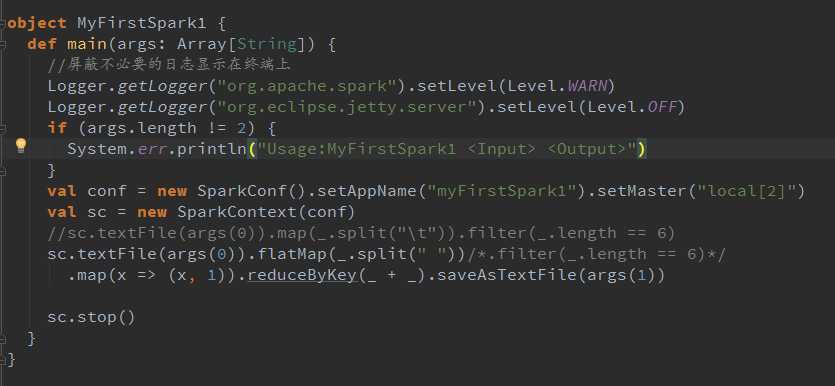
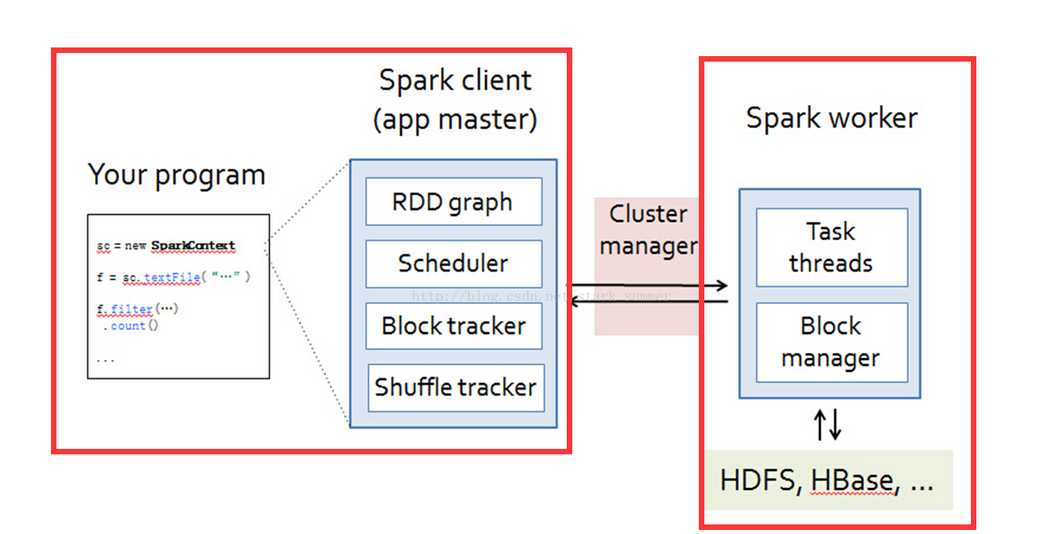
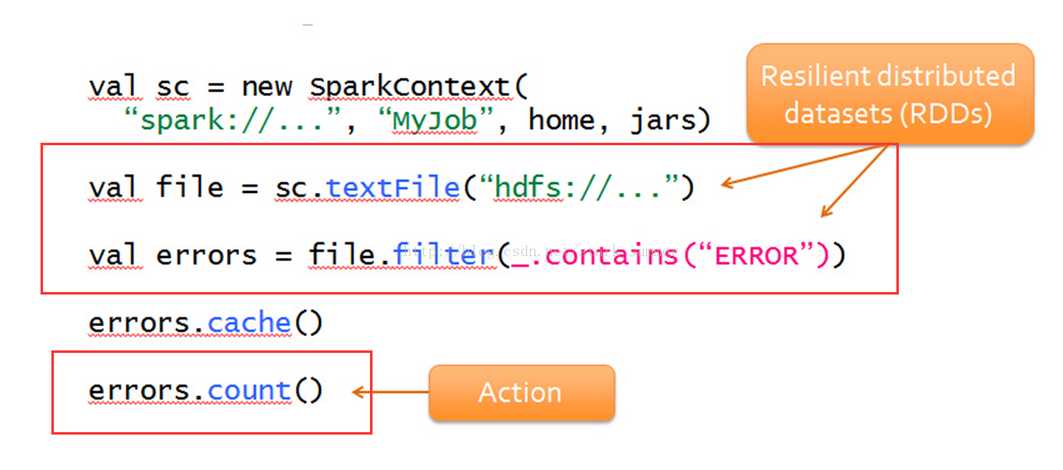


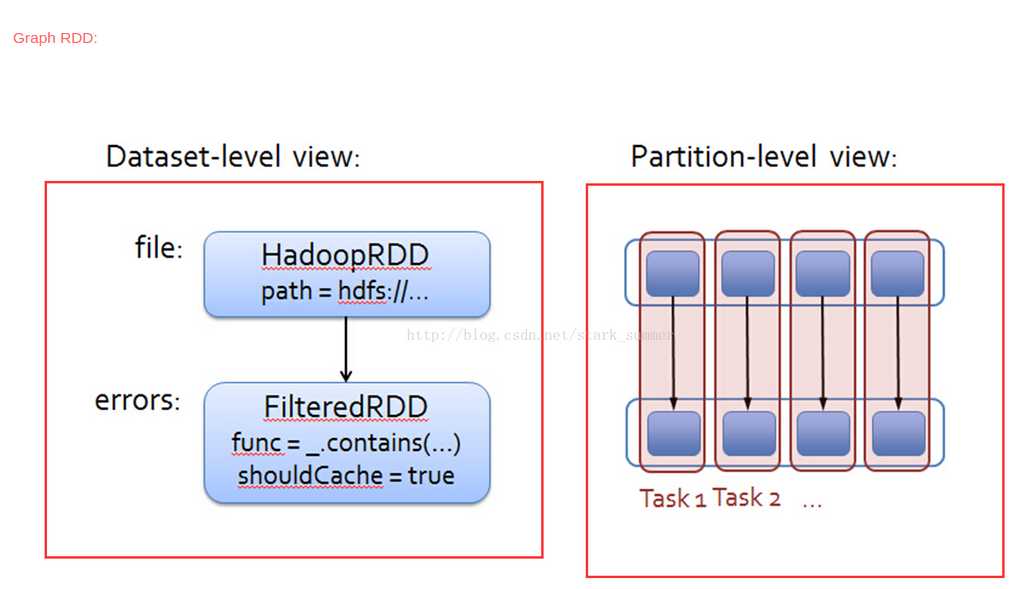
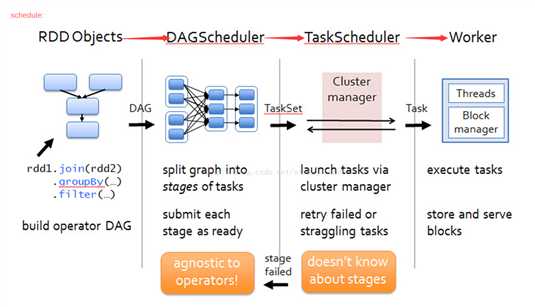

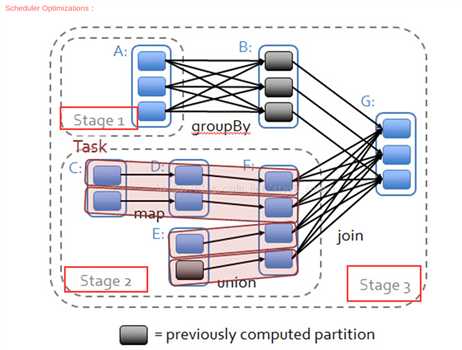
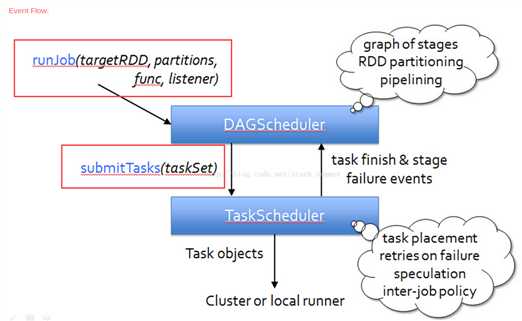
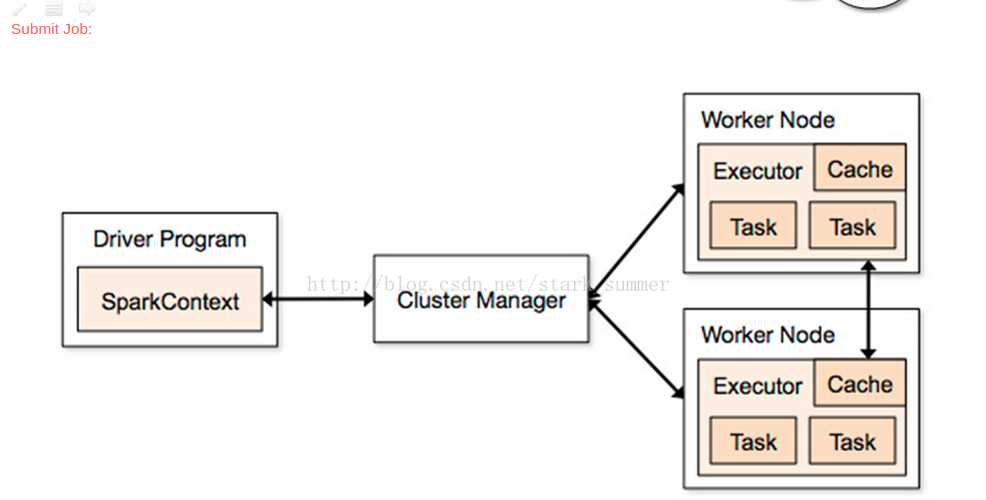
下面简单分析下 job 的生成和提交代码:
1. rdd.action() 会调用 DAGScheduler.runJob(rdd, processPartition, resultHandler) 来生成 job。
2. runJob() 会首先通过rdd.getPartitions()来得到 finalRDD 中应该存在的 partition 的个数和类型:Array[Partition]。然后根据 partition 个数 new 出来将来要持有 result 的数组 ArrayResult。
3. 最后调用 DAGScheduler 的runJob(rdd, cleanedFunc, partitions, allowLocal, resultHandler)来提交 job。cleanedFunc 是 processParittion 经过闭包清理后的结果,这样可以被序列化后传递给不同节点的 task。
4. DAGScheduler 的 runJob 继续调用submitJob(rdd, func, partitions, allowLocal, resultHandler) 来提交 job。
submitJob() 首先得到一个 jobId,然后再次包装 func,向 DAGSchedulerEventProcessActor 发送
5. JobSubmitted 信息,该 actor 收到信息后进一步调用dagScheduler.handleJobSubmitted()来处理提交的 job。之所以这么麻烦,是为了符合事件驱动模型。
6. handleJobSubmmitted() 首先调用 finalStage = newStage() 来划分 stage,然后submitStage(finalStage)。由于 finalStage 可能有 parent stages,实际先提交 parent stages,等到他们执行完,finalStage 需要再次提交执行。再次提交由 handleJobSubmmitted() 最后的 submitWaitingStages() 负责。
分析一下 newStage() 如何划分 stage:
1. 该方法在 new Stage() 的时候会调用 finalRDD 的 getParentStages()。
2. getParentStages() 从 finalRDD 出发,反向 visit 逻辑执行图,遇到 NarrowDependency 就将依赖的 RDD 加入到 stage,遇到 ShuffleDependency 切开 stage,并递归到 ShuffleDepedency 依赖的 stage。
3. 一个 ShuffleMapStage(不是最后形成 result 的 stage)形成后,会将该 stage 最后一个 RDD 注册到MapOutputTrackerMaster.registerShuffle(shuffleDep.shuffleId, rdd.partitions.size),这一步很重要,因为 shuffle 过程需要 MapOutputTrackerMaster 来指示 ShuffleMapTask 输出数据的位置。
分析一下 submitStage(stage) 如何提交 stage 和 task:
1. 先确定该 stage 的 missingParentStages,使用getMissingParentStages(stage)。如果 parentStages 都可能已经执行过了,那么就为空了。
2. 如果 missingParentStages 不为空,那么先递归提交 missing 的 parent stages,并将自己加入到 waitingStages 里面,等到 parent stages 执行结束后,会触发提交 waitingStages 里面的 stage。
3. 如果 missingParentStages 为空,说明该 stage 可以立即执行,那么就调用submitMissingTasks(stage, jobId)来生成和提交具体的 task。如果 stage 是 ShuffleMapStage,那么 new 出来与该 stage 最后一个 RDD 的 partition 数相同的 ShuffleMapTasks。如果 stage 是 ResultStage,那么 new 出来与 stage 最后一个 RDD 的 partition 个数相同的 ResultTasks。一个 stage 里面的 task 组成一个 TaskSet,最后调用taskScheduler.submitTasks(taskSet)来提交一整个 taskSet。
4. 这个 taskScheduler 类型是 TaskSchedulerImpl,在 submitTasks() 里面,每一个 taskSet 被包装成 manager: TaskSetMananger,然后交给schedulableBuilder.addTaskSetManager(manager)。schedulableBuilder 可以是 FIFOSchedulableBuilder 或者 FairSchedulableBuilder 调度器。submitTasks() 最后一步是通知backend.reviveOffers()去执行 task,backend 的类型是 SchedulerBackend。如果在集群上运行,那么这个 backend 类型是 SparkDeploySchedulerBackend。
5. SparkDeploySchedulerBackend 是 CoarseGrainedSchedulerBackend 的子类,backend.reviveOffers()其实是向 DriverActor 发送 ReviveOffers 信息。SparkDeploySchedulerBackend 在 start() 的时候,会启动 DriverActor。DriverActor 收到 ReviveOffers 消息后,会调用launchTasks(scheduler.resourceOffers(Seq(new WorkerOffer(executorId, executorHost(executorId), freeCores(executorId))))) 来 launch tasks。scheduler 就是 TaskSchedulerImpl。scheduler.resourceOffers()从 FIFO 或者 Fair 调度器那里获得排序后的 TaskSetManager,并经过TaskSchedulerImpl.resourceOffer(),考虑 locality 等因素来确定 task 的全部信息 TaskDescription。调度细节这里暂不讨论。
6. DriverActor 中的 launchTasks() 将每个 task 序列化,如果序列化大小不超过 Akka 的 akkaFrameSize,那么直接将 task 送到 executor 那里执行executorActor(task.executorId) ! LaunchTask(new SerializableBuffer(serializedTask))。
在 Spark 中,没有这样功能明确的阶段。Spark将用户定义的计算过程转化为一个被称作Job逻辑执行图的有向无环图(DAG),图中的顶点代表RDD,边代表RDD之间的依赖关系。再将这个逻辑执行图转化为物理执行图,具体方法是:从逻辑图后往前推算,遇到 ShuffleDependency 就断开,最后根据断开的次数n,将其化分为(n+1)个stage。每个 stage 里面 task 的数目由该 stage 最后一个 RDD 中的 partition 个数决定。因此,Spark的Job的shuffle数是不固定的。
在Spark早期的版本中,Spark使用的是hash-based的shuffle,通常使用 HashMap 来对 shuffle 来的数据进行聚合,不会对数据进行提前排序。而Hadoop MapReduce 一直使用的就是 sort-based shuffle,进入 combine和 reduce的数据都会先经过排序(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。不过在Spark1.1已经支持sorted-basedshuffle,在这一点上做到了扬长避短。这次排序比赛中所使用的是Spark 1.2,采用的就是sorted-based shuffle。
此外,Databricks还创建了一个外部shuffle服务,该服务和Spark执行器(executor)本身是分离的。这个服务使得即使是Spark 执行器在因GC导致的暂停时仍然可以正常进行shuffle。
Shuffle write
由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle write 的任务很简单,那么实现也很简单:将 shuffle write 的处理逻辑加入到 ShuffleMapStage(ShuffleMapTask 所在的 stage) 的最后,该 stage 的 final RDD 每输出一个 record 就将其 partition 并持久化。图示如下:
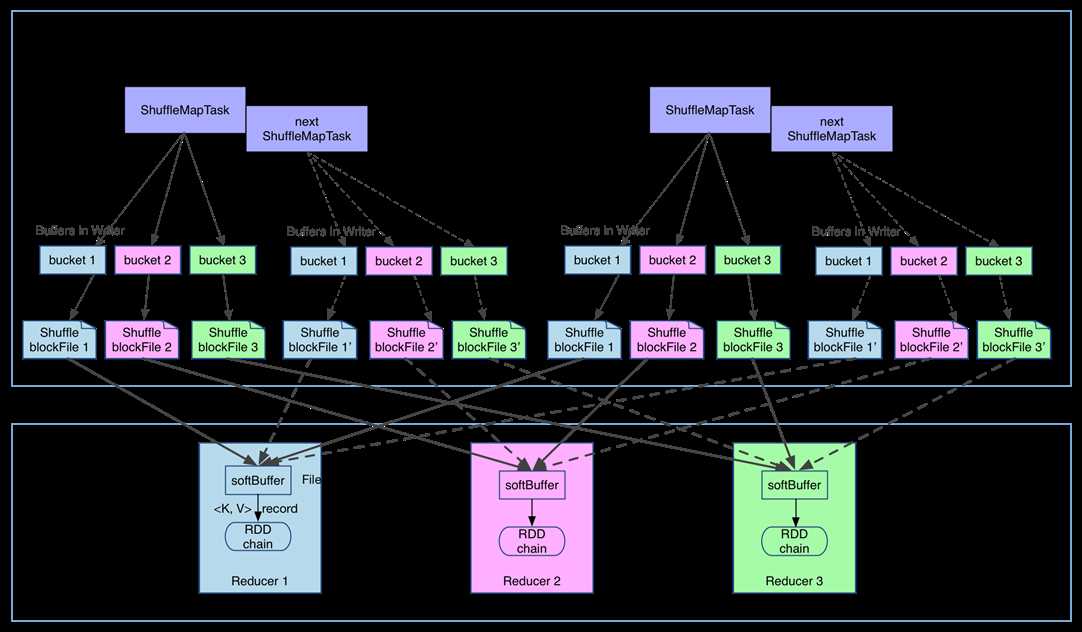
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
其实 bucket 是一个广义的概念,代表 ShuffleMapTask 输出结果经过 partition 后要存放的地方,这里为了细化数据存放位置和数据名称,仅仅用 bucket 表示缓冲区。
ShuffleMapTask 的执行过程很简单:先利用 pipeline 计算得到 finalRDD 中对应 partition 的 records。每得到一个 record 就将其送到对应的 bucket 里,具体是哪个 bucket 由partitioner.partition(record.getKey()))决定。每个 bucket 里面的数据会不断被写到本地磁盘上,形成一个 ShuffleBlockFile,或者简称 FileSegment。之后的 reducer 会去 fetch 属于自己的 FileSegment,进入 shuffle read 阶段。
这样的实现很简单,但有几个问题:
1. 产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
2. 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores * R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
目前来看,第二个问题还没有好的方法解决,因为写磁盘终究是要开缓冲区的,缓冲区太小会影响 IO 速度。但第一个问题有一些方法去解决,下面介绍已经在 Spark 里面实现的 FileConsolidation 方法。先上图:
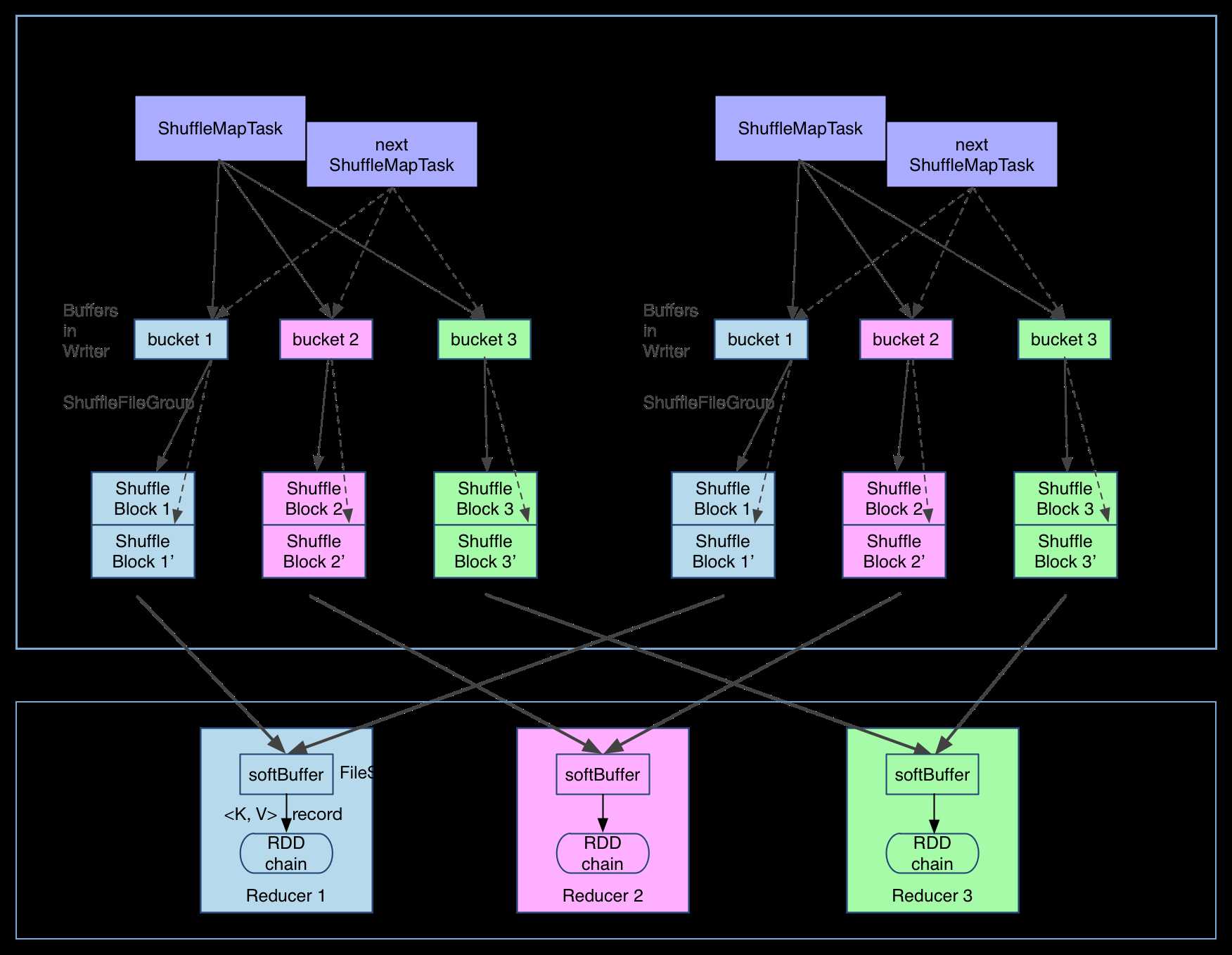
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i’,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
Shuffle read
先看一张包含 ShuffleDependency 的物理执行图,来自 reduceByKey:
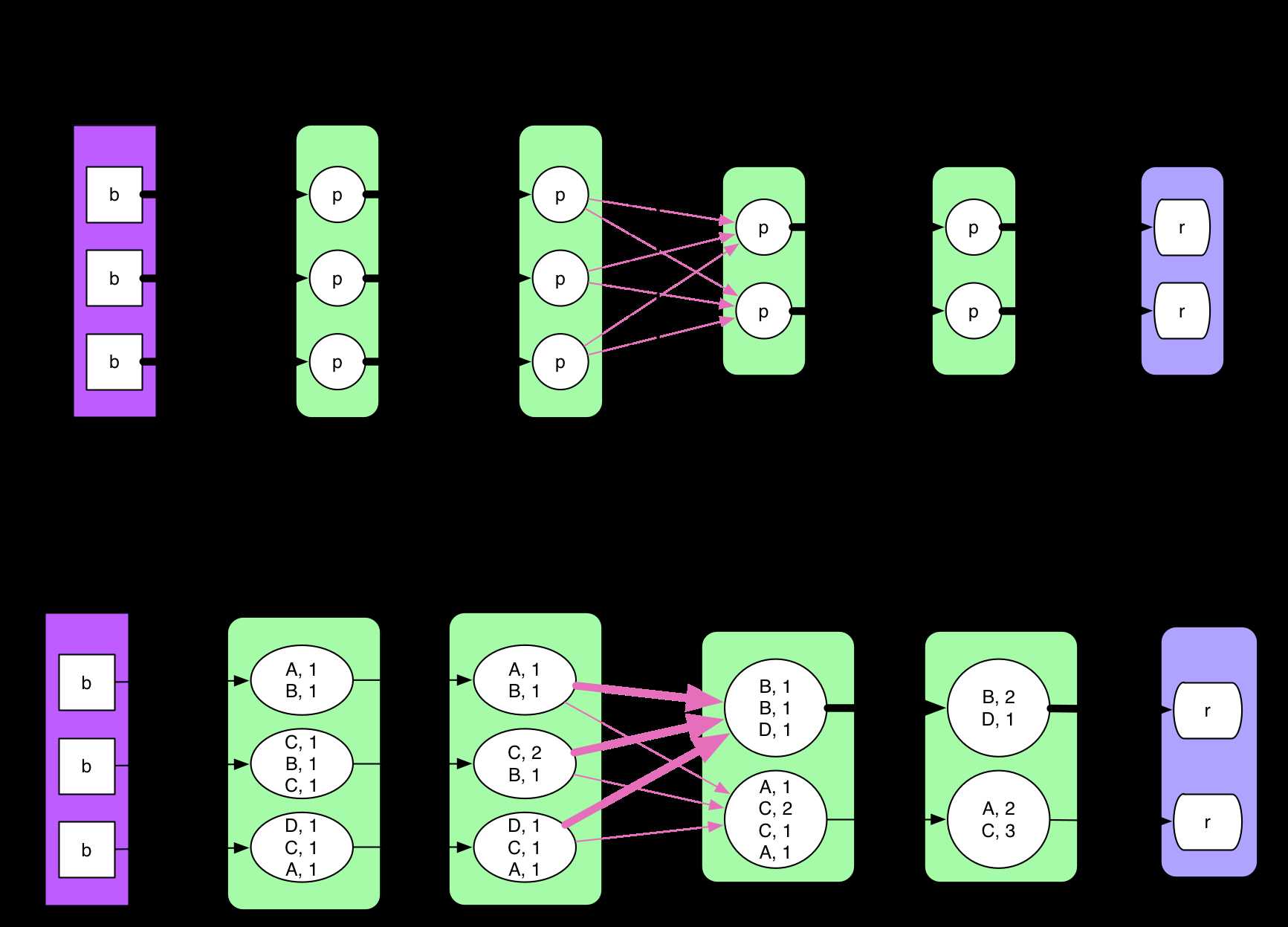
很自然地,要计算 ShuffleRDD 中的数据,必须先把 MapPartitionsRDD 中的数据 fetch 过来。那么问题就来了:
在什么时候 fetch,parent stage 中的一个 ShuffleMapTask 执行完还是等全部 ShuffleMapTasks 执行完?
解决问题:
消息队列系统
在spark中 作为消息系统为master,worker,driver等通信
sender ! RegisteredWorker(masterUrl, masterWebUiUrl)
// Master to Worker
case class RegisteredWorker(masterUrl: String, masterWebUiUrl: String) extends DeployMessage
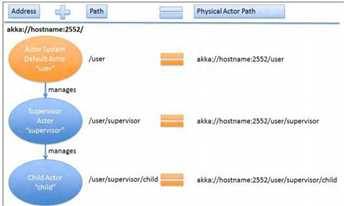
http://hongbinzuo.github.io/2014/12/16/Akka-Tutorial-with-Code-Conncurrency-and-Fault-Tolerance/
分布式文件系统,介于内存和磁盘之间的存储介质
http://tachyon-project.org/index.html
架构图:
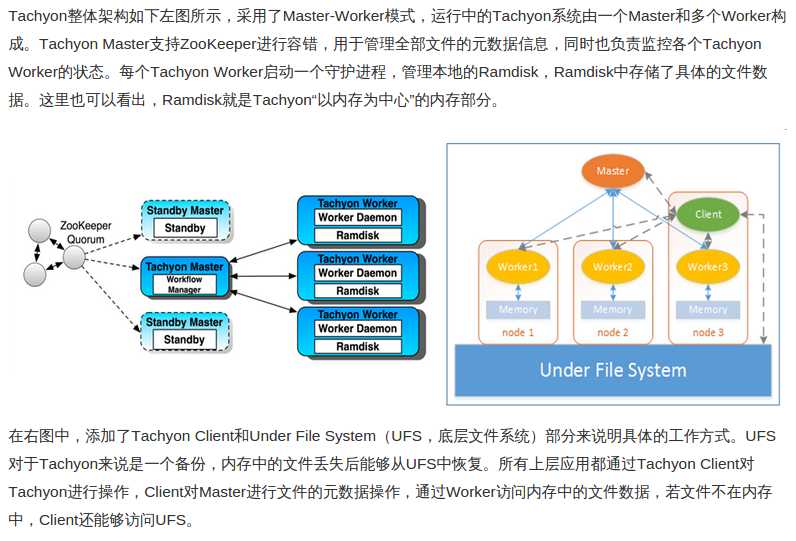
目前在spark中主要作为spark shuffle处理后 从各个解决拉取shuffle数据
. 配置SPARK_HOME/conf/spark-env.sh文件

. 配置SPARK_HOME/conf/slaves文件
. 启动spark&验证

标签:
原文地址:http://www.cnblogs.com/abapscript/p/4734501.html