标签:
隐藏单元:节点的输出在网络内部
输出单元:节点的输出是整个网络的输出(PS:输出单元一般有多个,最终系统采取的决策是所有输出单元中最“合理”的)
输入单元:节点的输入是整个网络的输入,节点的输出是隐藏单元的输入(带权重)
感知器
感知器的训练法则:
感知器法则(线性可分):wi=wi+?(t-o)xi;注意此处的o取值空间是{0,1},这就是它不同于下面要提到的随机梯度对应delta法则部分
delta法则(梯度下降,非线性可分):训练的是一个线性单元而不是感知器(感知器的输出是{0,1}),线性单元的输出为: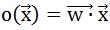
误差函数和根据梯度下降法得到权重学习方法如下:
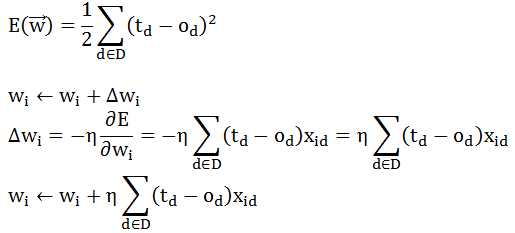
随机梯度的误差函数和权重学习方法如下:
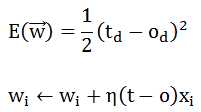
随机梯度的训练法则(权重更新公式)被称为增量法则(delta法则)或LMS法则(least-mean-square,最小均方)
随机梯度的权重更新公式恰好和感知器法则的相同,只是o的取值不一样,一个是wx,一个是sgn(wx)
简单的神经网络图
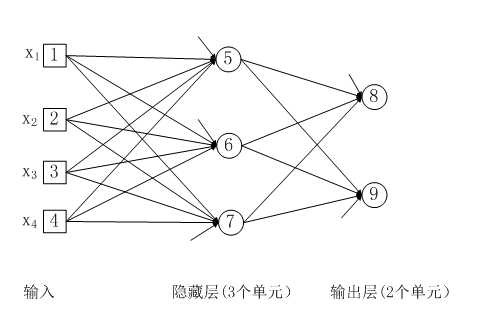
图说明:
1、这个神经网络包含两层sigmoid单元(图中的圆圈都是sigmoid单元)
2、图中每个单元旁边都有一个额外的输入,即阈值
3、每一条边都有一个权重wij(图中没有表示)
4、隐藏层的每个单元的输出的值域是(0,1),而隐藏层的输出是输出层的输入。所以输出层的每个单元的输入和输出的值域都是(0,1)
所谓反向传播是指,先计算输出单元的误差,然后再用输出单元的误差计算隐藏单元的误差,最后根据这两个误差分别更新相应的权重。
标签:
原文地址:http://www.cnblogs.com/xiangzhi/p/4735205.html