标签:
树是一种数据结构,其中一个元素可以有两个或者多个数据元素,具有一对多的特点,用树结构来存储文件。

层次: 图中我们已经表出来了,根为第一层,根的孩子为第二层,依此类推,若某结点在第i层,则其孩子结点在第i+1层。0层、1层、2层、3层。
总结点=所有度结点的和+1(应该是父结点)
优点:parent(tree, x)操作可以在常量时间内实现
缺点:求结点的孩子时需要遍历整个结构
用一组连续的存储空间来存储树的结点,同时在每个结点中附加一个指示器(整数域) ,用以指示双亲结点的位置(下标值) 。

树中每个结点有多个指针域,每个指针指向其一棵子树的根结点。有两种结点结构。
指针域的数目就是树的度。
其特点是:链表结构简单,但指针域的浪费明显。结点结构如下图(a)所示。在一棵有n个结点,度为k的树中必有n(k-1)+1空指针域。
树中每个结点的指针域数量不同,是该结点的度,如图(b) 所示。没有多余的指针域,但操作不便。

对于树中的每个结点,其孩子结点用带头结点的单链表表示,表结点和头结点的结构如下图所示。
n个结点的树有n个(孩子)单链表(叶子结点的孩子链表为空),而n个头结点又组成一个线性表且以顺序存储结构表示。


以二叉链表作为树的存储结构。

两个指针域:分别指向结点的第一个子结点和下一个兄弟结点。
由树结构的定义可知,树的遍历有二种方法。
⑴ 先序遍历:先访问根结点,然后依次先序遍历完每棵子树。如图的树,先序遍历的次序是: ABCDEFGIJHK
⑵ 后序遍历:先依次后序遍历完每棵子树,然后访问根结点。如图的树,后序遍历的次序是: CDBFGIJHEKA

说明:
◆ 树的先序遍历实质上与将树转换成二叉树后对二叉树的先序遍历相同。
◆ 树的后序遍历实质上与将树转换成二叉树后对二叉树的中序遍历相同。
2 森林的遍历
设F={T1, T2,?,Tn}是森林,对F的遍历有二种方法。
⑴ 先序遍历:按先序遍历树的方式依次遍历F中的每棵树。
⑵ 中序遍历:按后序遍历树的方式依次遍历F中的每棵树。
树结构包括:二叉查找树(二叉排序树)、平衡二叉树(AVL树)、红黑树、B-树、B+树、字典树(trie树)、后缀树、广义后缀树。
1、二叉查找树(二叉排序树)
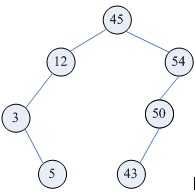 (图a)
(图a)
二叉查找树是一种动态查找表(图a),具有这些性质:
(1)若它的左子树不为空,则左子树上的所有节点的值都小于它的根节点的值;
(2)若它的右子树不为空,则右子树上所有节点的值都大于它的根节点的值;
(3)其他的左右子树也分别为二叉查找树;
(4)二叉查找树是动态查找表,在查找的过程中可见添加和删除相应的元素,在这些操作中需要保持二叉查找树的以上性质。
2、平衡二叉树(AVL树)
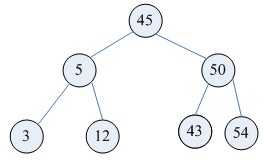 (图b)
(图b)
含有相同节点的二叉查找树可以有不同的形态,而二叉查找树的平均查找长度与树的深度有关,所以需要找出一个查找平均长度最小的一棵,那就是平衡二叉树(图b),具有以下性质:
(1)要么是棵空树,要么其根节点左右子树的深度之差的绝对值不超过1;
(2)其左右子树也都是平衡二叉树;
(3)二叉树节点的平衡因子定义为该节点的左子树的深度减去右子树的深度。则平衡二叉树的所有节点的平衡因子只可能是-1,0,1。
3、红黑树
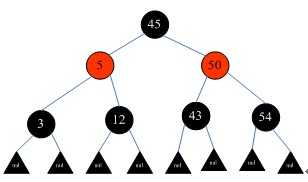 (图c)
(图c)
红黑树是一种自平衡二叉树,在平衡二叉树的基础上每个节点又增加了一个颜色的属性,节点的颜色只能是红色或黑色。具有以下性质:
(1)根节点只能是黑色;
(2)红黑树中所有的叶子节点后面再接上左右两个空节点,这样可以保持算法的一致性,而且所有的空节点都是黑色;
(3)其他的节点要么是红色,要么是黑色,红色节点的父节点和左右孩子节点都是黑色,及黑红相间;
(4)在任何一棵子树中,从根节点向下走到空节点的路径上所经过的黑节点的数目相同,从而保证了是一个平衡二叉树。
4、B-树
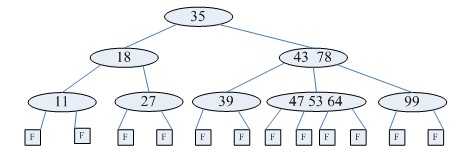 (图d)
(图d)
B-树是一种平衡多路查找树,它在文件系统中很有用。一棵m阶B-树(图d为4阶B-树),具有下列性质:
(1)树中每个节点至多有m棵子树;
(2)若根节点不是叶子节点,则至少有2棵子树;
(3)除根节点之外的所有非终端节点至少有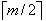 棵子树;
棵子树;
(4)每个节点中的信息结构为(A0,K1,A1,K2......Kn,An),其中n表示关键字个数,Ki为关键字,Ai为指针;
(5)所有的叶子节点都出现在同一层次上,且不带任何信息,也是为了保持算法的一致性。
5、B+树
 (图e)
(图e)
B+数是B-树的一种变形,它与B-树的差别在于(图e为3阶B+树):
(1)有n棵子树的节点含有n个关键字;
(2)所有的叶子节点包含了全部关键字的信息,及指向这些关键字记录的指针,且叶子节点本身按关键字大小自小到大顺序链接;
(3)所有非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中最大(或最小)关键字,所有B+树更像一个索引顺序表;
(4)对B+树进行查找运算,一是从最小关键字起进行顺序查找,二是从根节点开始,进行随机查找。
6、字典树(trie树)
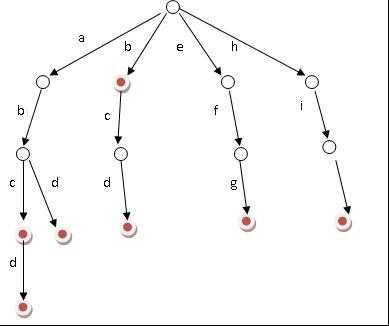 (图f)
(图f)
字典树是一种以树形结构保存大量字符串。以便于字符串的统计和查找,经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。具有以下特点(图f):
(1)根节点为空;
(2)除根节点外,每个节点包含一个字符;
(3)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
(4)每个字符串在建立字典树的过程中都要加上一个区分的结束符,避免某个短字符串正好是某个长字符串的前缀而淹没。
7、后缀树
后缀树则是一个字符串的所有后缀组成的字典树。具体内容再前几章已讲过。
8、广义后缀树
广义后缀树是好几个字符串的的所有后缀组成的字典树,同样每个字符串的所有后缀都具有一个相同的结束符,不同字符串的结束符不同。
标签:
原文地址:http://www.cnblogs.com/polly333/p/4739567.html