标签:
脚本和其他自动化组件下载 最新Redis 标准发行版本tarball下载 http://download.redis.io/redis-stable.tar.gz. 最新Redis标准发行版本源代码浏览这里, 使用src/version.h文件来自动获得版本信息。
Github 镜像 redis-hashes 包含了README文件,文件中有发行版本tarball的SHA1值。
下载,解压,编译:
$ wget http://download.redis.io/releases/redis-3.0.3.tar.gz
$ tar xzf redis-3.0.3.tar.gz
$ cd redis-3.0.3
$ make二进制文件是编译完成后在src目录下. 运行如下:
$ src/redis-serverYou can interact with Redis using the built-in client:
$ src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"你刚开始接触Redis? 试试我们的 在线交互教程.http://try.redis.io/
http://www.redis.cn/download.html
http://cygwin.com/install.html
前几天微博发生了一起大的系统故障,很多技术的朋友都比较关心,其中的原因不会超出James Hamilton在On Designing and Deploying Internet-Scale Service(1)概括的那几个范围,James第一条经验“Design for failure”是所有互联网架构成功的一个关键。互联网系统的工程理论其实非常简单,James paper中内容几乎称不上理论,而是多条实践经验分享,每个公司对这些经验的理解及执行力决定了架构成败。
题外话说完,最近又研究了Redis。去年曾做过一个MemcacheDB, Tokyo Tyrant, Redis performance test,到目前为止,这个benchmark结果依然有效。这1年我们经历了很多眼花缭乱的key value存储产品的诱惑,从Cassandra的淡出(Twitter暂停在主业务使用)到HBase的兴起(Facebook新的邮箱业务选用HBase(2)),当再回头再去看Redis,发现这个只有1万多行源代码的程序充满了神奇及大量未经挖掘的特性。Redis性能惊人,国内前十大网站的子产品估计用1台Redis就可以满足存储及Cache的需求。除了性能印象之外,业界其实普遍对Redis的认识存在一定误区。本文提出一些观点供大家探讨。
这个问题的结果影响了我们怎么用Redis。如果你认为Redis是一个key value store, 那可能会用它来代替MySQL;如果认为它是一个可以持久化的cache, 可能只是它保存一些频繁访问的临时数据。Redis是REmote DIctionary Server的缩写,在Redis在官方网站的的副标题是A persistent key-value database with built-in net interface written in ANSI-C for Posix systems,这个定义偏向key value store。还有一些看法则认为Redis是一个memory database,因为它的高性能都是基于内存操作的基础。另外一些人则认为Redis是一个data structure server,因为Redis支持复杂的数据特性,比如List, Set等。对Redis的作用的不同解读决定了你对Redis的使用方式。
互联网数据目前基本使用两种方式来存储,关系数据库或者key value。但是这些互联网业务本身并不属于这两种数据类型,比如用户在社会化平台中的关系,它是一个list,如果要用关系数据库存储就需要转换成一种多行记录的形式,这种形式存在很多冗余数据,每一行需要存储一些重复信息。如果用key value存储则修改和删除比较麻烦,需要将全部数据读出再写入。Redis在内存中设计了各种数据类型,让业务能够高速原子的访问这些数据结构,并且不需要关心持久存储的问题,从架构上解决了前面两种存储需要走一些弯路的问题。
很多开发者都认为Redis不可能比Memcached快,Memcached完全基于内存,而Redis具有持久化保存特性,即使是异步的,Redis也不可能比Memcached快。但是测试结果基本是Redis占绝对优势。一直在思考这个原因,目前想到的原因有这几方面。
Redis的数据全部放在内存带来了高速的性能,但是也带来一些不合理之处。比如一个中型网站有100万注册用户,如果这些资料要用Redis来存储,内存的容量必须能够容纳这100万用户。但是业务实际情况是100万用户只有5万活跃用户,1周来访问过1次的也只有15万用户,因此全部100万用户的数据都放在内存有不合理之处,RAM需要为冷数据买单。
这跟操作系统非常相似,操作系统所有应用访问的数据都在内存,但是如果物理内存容纳不下新的数据,操作系统会智能将部分长期没有访问的数据交换到磁盘,为新的应用留出空间。现代操作系统给应用提供的并不是物理内存,而是虚拟内存(Virtual Memory)的概念。
基于相同的考虑,Redis 2.0也增加了VM特性。让Redis数据容量突破了物理内存的限制。并实现了数据冷热分离。
Redis的VM依照之前的epoll实现思路依旧是自己实现。但是在前面操作系统的介绍提到OS也可以自动帮程序实现冷热数据分离,Redis只需要OS申请一块大内存,OS会自动将热数据放入物理内存,冷数据交换到硬盘,另外一个知名的“理解了现代操作系统(3)”的Varnish就是这样实现,也取得了非常成功的效果。
作者antirez在解释为什么要自己实现VM中提到几个原因(6)。主要OS的VM换入换出是基于Page概念,比如OS VM1个Page是4K, 4K中只要还有一个元素即使只有1个字节被访问,这个页也不会被SWAP, 换入也同样道理,读到一个字节可能会换入4K无用的内存。而Redis自己实现则可以达到控制换入的粒度。另外访问操作系统SWAP内存区域时block进程,也是导致Redis要自己实现VM原因之一。
作为一个key value存在,很多开发者自然的使用set/get方式来使用Redis,实际上这并不是最优化的使用方法。尤其在未启用VM情况下,Redis全部数据需要放入内存,节约内存尤其重要。
假如一个key-value单元需要最小占用512字节,即使只存一个字节也占了512字节。这时候就有一个设计模式,可以把key复用,几个key-value放入一个key中,value再作为一个set存入,这样同样512字节就会存放10-100倍的容量。
这就是为了节约内存,建议使用hashset而不是set/get的方式来使用Redis,详细方法见参考文献(7)。
Redis有两种存储方式,默认是snapshot方式,实现方法是定时将内存的快照(snapshot)持久化到硬盘,这种方法缺点是持久化之后如果出现crash则会丢失一段数据。因此在完美主义者的推动下作者增加了aof方式。aof即append only mode,在写入内存数据的同时将操作命令保存到日志文件,在一个并发更改上万的系统中,命令日志是一个非常庞大的数据,管理维护成本非常高,恢复重建时间会非常长,这样导致失去aof高可用性本意。另外更重要的是Redis是一个内存数据结构模型,所有的优势都是建立在对内存复杂数据结构高效的原子操作上,这样就看出aof是一个非常不协调的部分。
其实aof目的主要是数据可靠性及高可用性,在Redis中有另外一种方法来达到目的:Replication。由于Redis的高性能,复制基本没有延迟。这样达到了防止单点故障及实现了高可用。
要想成功使用一种产品,我们需要深入了解它的特性。Redis性能突出,如果能够熟练的驾驭,对国内很多大型应用具有很大帮助。希望更多同行加入到Redis使用及代码研究行列。
http://www.cnblogs.com/redcreen/archive/2011/02/15/1955623.html
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文 件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务 器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
官方网站:http://redis.io/ 官方下载:http://redis.io/download 可以根据需要下载不同版本
windows 版 32、64位下载(比较低): https://github.com/dmajkic/redis/downloads
64位下载:https://github.com/mythz/redis-windows
github的资源可以ZIP直接下载的(这个是给不知道的同学友情提示下)。
以 https://github.com/dmajkic/redis/downloads 下的redis-2.4.5-win32-win64.zip 为例,讲一下32位的安装方法。
下载完成后 可以右键解压到某个硬盘下 比如 F:\redis-2.4.5-win32-win64
复制下面的32bit到安装目录下,这里我安装到 F 盘的根目录下,重命名文件夹为 redis
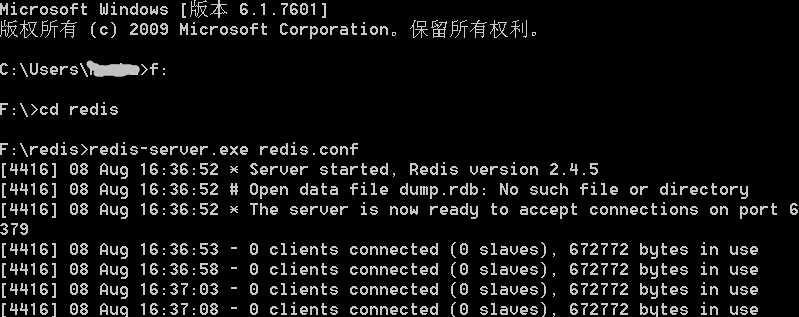
cmd进入redis目录后 开启服务 (注意加上redis.conf)
redis-server.exe redis.conf
这个窗口要保持开启 关闭时redis服务会自动关闭
开着刚才的窗口不要关闭.
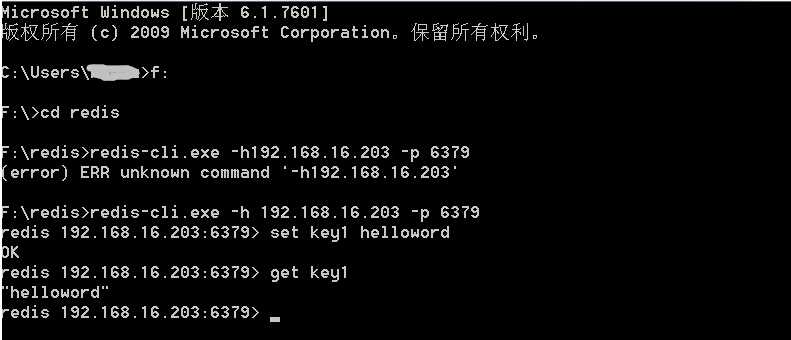
再另起一个窗口 cmd进入redis目录后 输入下面的命令,注意-h后面的是自己的ip地址也可以是127.0.0.1
redis-cli.exe -h 127.0.0.1 -p 6379
其中 127.0.0.1是本地ip,6379是redis服务端的默认端口。
连接成功后,设置键值对:
set key1 helloworld
获取
get key1
每次打开命令行启动Redis会很麻烦,把Redis设为windows启动项就不用每次都入命令行了 在redis的目录下新建一个start.bat文件内容为
F: cd F:\redis redis-server.exe redis.conf
再新建一个文件redis_run.vbs内容为
createobject("wscript.shell").run "F:\redis\start.bat",0
把redis_run.vbs拖到windows启动里运行一下,关闭原来的redis启动cmd窗,在连接窗里输入 get key1 发现OK了,下次开机就会自动启动
http://www.cnblogs.com/mbailing/p/3899965.html
Running Redis as a Service ========================== If you installed Redis using the MSI package, then Redis was already installed as a Windows service. Nothing further to do. If you would like to change its settings, you can update the *redis.windows.conf* file and then restart the Redis service (Run -\> services.msc -\> Redis -\> Restart). During installation of the MSI you can either use the installer’s user interface to update the port that Redis listens at and the firewall exception or run it silently without a UI. The following examples show how to install from the command line: **default install (port 6379 and firewall exception ON):** *msiexec /i Redis-x64.msi * **set port and turn OFF firewall exception:** *msiexec /i Redis-x64.msi PORT=1234 FIREWALL\_ON=""* **set port and turn ON firewall exception:** *msiexec /i Redis-x64.msi PORT=1234 FIREWALL\_ON=1* **install with no user interface:** *msiexec /quiet /i Redis-x64.msi* If you did *not* install Redis using the MSI package, then you still run Redis as a Windows service by following these instructions: In order to better integrate with the Windows Services model, new command line arguments have been introduced to Redis. These service arguments require an elevated user context in order to connect to the service control manager. If these commands are invoked from a non-elevated context, Redis will attempt to create an elevated context in which to execute these commands. This will cause a User Account Control dialog to be displayed by Windows and may require Administrative user credentials in order to proceed. Installing the Service ---------------------- *--service-install* This must be the first argument on the redis-server command line. Arguments after this are passed in the order they occur to Redis when the service is launched. The service will be configured as Autostart and will be launched as "NT AUTHORITY\\NetworkService". Upon successful installation a success message will be displayed and Redis will exit. This command does not start the service. For instance: redis-server --service-install redis.windows.conf --loglevel verbose Uninstalling the Service ------------------------ *--service-uninstall* This will remove the Redis service configuration information from the registry. Upon successful uninstallation a success message will be displayed and Redis will exit. This does command not stop the service. For instance: redis-server --service-uninstall Starting the Service -------------------- *--service-start* This will start the Redis service. Upon successful start, a success message will be displayed and Redis will begin running. For instance: redis-server --service-start Stopping the Service -------------------- *--service-stop* This will stop the Redis service. Upon successful termination a success message will be displayed and Redis will exit. For instance: redis-server --service-stop Naming the Service ------------------ *--service-name **name*** This optional argument may be used with any of the preceding commands to set the name of the installed service. This argument should follow the service-install, service-start, service-stop or service-uninstall commands, and precede any arguments to be passed to Redis via the service-install command. The following would install and start three separate instances of Redis as a service: redis-server --service-install –service-name redisService1 –port 10001 redis-server --service-start –service-name redisService1 redis-server --service-install –service-name redisService2 –port 10002 redis-server --service-start –service-name redisService2 redis-server --service-install –service-name redisService3 –port 10003 redis-server --service-start –service-name redisService3
https://raw.githubusercontent.com/MSOpenTech/redis/2.8/Windows%20Service%20Documentation.md
redis配置文件redis.conf详细说明
# By default Redis does not run as a daemon. Use ‘yes‘ if you need it. # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. #Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程(守护进程(daemon)是指在UNIX或其他多任务操作系统中在后台执行的电脑程序,并不会接受电脑用户的直接操控。) daemonize no
# When running daemonized, Redis writes a pid file in /var/run/redis.pid by # default. You can specify a custom pid file location here. #当 Redis 以守护进程的方式运行的时候,Redis 默认会把 pid 文件放在/var/run/redis.pid,你可以配置到其他地址。当运行多个 redis 服务时,需要指定不同的 pid 文件和端口 pidfile /var/run/redis.pid # Accept connections on the specified port, default is 6379. # If port 0 is specified Redis will not listen on a TCP socket. #端口没什么好说的 port 6379 # If you want you can bind a single interface, if the bind option is not # specified all the interfaces will listen for incoming connections. #指定Redis可接收请求的IP地址,不设置将处理所有请求,建议生产环境中设置 # bind 127.0.0.1 # Close the connection after a client is idle for N seconds (0 to disable) #客户端连接的超时时间,单位为秒,超时后会关闭连接 timeout 0 # Specify the log file name. Also ‘stdout‘ can be used to force # Redis to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null #配置 log 文件地址,默认打印在命令行终端的窗口上 logfile stdout # Set the number of databases. The default database is DB 0, you can select # a different one on a per-connection basis using SELECT <dbid> where # dbid is a number between 0 and ‘databases‘-1 #设置数据库的个数,可以使用 SELECT <dbid>命令来切换数据库。默认使用的数据库是 0 databases 16
# # Save the DB on disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving at all commenting all the "save" lines. #设置 Redis 进行数据库镜像的频率。 #900秒之内有1个keys发生变化时 #30秒之内有10个keys发生变化时 #60秒之内有10000个keys发生变化时 save 900 1 save 300 10 save 60 10000 # Compress string objects using LZF when dump .rdb databases? # For default that‘s set to ‘yes‘ as it‘s almost always a win. # If you want to save some CPU in the saving child set it to ‘no‘ but # the dataset will likely be bigger if you have compressible values or keys. #在进行镜像备份时,是否进行压缩 rdbcompression yes # The filename where to dump the DB #镜像备份文件的文件名 dbfilename dump.rdb # The working directory. # # The DB will be written inside this directory, with the filename specified # above using the ‘dbfilename‘ configuration directive. # # Also the Append Only File will be created inside this directory. # # Note that you must specify a directory here, not a file name. #数据库镜像备份的文件放置的路径。这里的路径跟文件名要分开配置是因为 Redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该该临时文件替换为上面所指定的文件, #而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中 dir ./ # Master-Slave replication. Use slaveof to make a Redis instance a copy of # another Redis server. Note that the configuration is local to the slave # so for example it is possible to configure the slave to save the DB with a # different interval, or to listen to another port, and so on. #设置该数据库为其他数据库的从数据库 # slaveof <masterip> <masterport> # If the master is password protected (using the "requirepass" configuration # directive below) it is possible to tell the slave to authenticate before # starting the replication synchronization process, otherwise the master will # refuse the slave request. #指定与主数据库连接时需要的密码验证 # masterauth <master-password> # Require clients to issue AUTH <PASSWORD> before processing any other # commands. This might be useful in environments in which you do not trust # others with access to the host running redis-server. # # This should stay commented out for backward compatibility and because most # people do not need auth (e.g. they run their own servers). # # Warning: since Redis is pretty fast an outside user can try up to # 150k passwords per second against a good box. This means that you should # use a very strong password otherwise it will be very easy to break. #设置客户端连接后进行任何其他指定前需要使用的密码。 警告:redis速度相当快,一个外部的用户可以在一秒钟进行150K次的密码尝试,你需要指定非常非常强大的密码来防止暴力破解。 # requirepass foobared
# Set the max number of connected clients at the same time. By default there # is no limit, and it‘s up to the number of file descriptors the Redis process # is able to open. The special value ‘0‘ means no limits. # Once the limit is reached Redis will close all the new connections sending # an error ‘max number of clients reached‘. #限制同时连接的客户数量。当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到 error 信息 # maxclients 128 # Don‘t use more memory than the specified amount of bytes. # When the memory limit is reached Redis will try to remove keys # accordingly to the eviction policy selected (see maxmemmory-policy). # # If Redis can‘t remove keys according to the policy, or if the policy is # set to ‘noeviction‘, Redis will start to reply with errors to commands # that would use more memory, like SET, LPUSH, and so on, and will continue # to reply to read-only commands like GET. # # This option is usually useful when using Redis as an LRU cache, or to set # an hard memory limit for an instance (using the ‘noeviction‘ policy). # # WARNING: If you have slaves attached to an instance with maxmemory on, # the size of the output buffers needed to feed the slaves are subtracted # from the used memory count, so that network problems / resyncs will # not trigger a loop where keys are evicted, and in turn the output # buffer of slaves is full with DELs of keys evicted triggering the deletion # of more keys, and so forth until the database is completely emptied. # # In short… if you have slaves attached it is suggested that you set a lower # limit for maxmemory so that there is some free RAM on the system for slave # output buffers (but this is not needed if the policy is ‘noeviction‘). #设置redis能够使用的最大内存。当内存满了的时候,如果还接收到set命令,redis将先尝试剔除设置过expire信息的key,而不管该key的过期时间还没有到达。 #在删除时,将按照过期时间进行删除,最早将要被过期的key将最先被删除。如果带有expire信息的key都删光了,那么将返回错误。 #这样,redis将不再接收写请求,只接收get请求。maxmemory的设置比较适合于把redis当作于类似memcached 的缓存来使用 # maxmemory <bytes> # By default Redis asynchronously dumps the dataset on disk. If you can live # with the idea that the latest records will be lost if something like a crash # happens this is the preferred way to run Redis. If instead you care a lot # about your data and don‘t want to that a single record can get lost you should # enable the append only mode: when this mode is enabled Redis will append # every write operation received in the file appendonly.aof. This file will # be read on startup in order to rebuild the full dataset in memory. # # Note that you can have both the async dumps and the append only file if you # like (you have to comment the "save" statements above to disable the dumps). # Still if append only mode is enabled Redis will load the data from the # log file at startup ignoring the dump.rdb file. # # IMPORTANT: Check the BGREWRITEAOF to check how to rewrite the append # log file in background when it gets too big. #默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。 #所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。 #开 启append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当redis重新启动时,会从该文件恢复出之前的状态。 #但是这样会造成 appendonly.aof 文件过大,所以redis还支持了BGREWRITEAOF 指令,对appendonly.aof进行重新整理 appendonly no # The fsync() call tells the Operating System to actually write data on disk # instead to wait for more data in the output buffer. Some OS will really flush # data on disk, some other OS will just try to do it ASAP. # # Redis supports three different modes: # # no: don‘t fsync, just let the OS flush the data when it wants. Faster. # always: fsync after every write to the append only log . Slow, Safest. # everysec: fsync only if one second passed since the last fsync. Compromise. # # The default is "everysec" that‘s usually the right compromise between # speed and data safety. It‘s up to you to understand if you can relax this to # "no" that will will let the operating system flush the output buffer when # it wants, for better performances (but if you can live with the idea of # some data loss consider the default persistence mode that‘s snapshotting), # or on the contrary, use "always" that‘s very slow but a bit safer than # everysec. # # If unsure, use "everysec". #设置对 appendonly.aof 文件进行同步的频率。always 表示每次有写操作都进行同步,everysec 表示对写操作进行累积,每秒同步一次。 # appendfsync always appendfsync everysec # appendfsync no # Virtual Memory allows Redis to work with datasets bigger than the actual # amount of RAM needed to hold the whole dataset in memory. # In order to do so very used keys are taken in memory while the other keys # are swapped into a swap file, similarly to what operating systems do # with memory pages. # # To enable VM just set ‘vm-enabled‘ to yes, and set the following three # VM parameters accordingly to your needs. #是否开启虚拟内存支持。因为 redis 是一个内存数据库,而且当内存满的时候,无法接收新的写请求,所以在redis2.0中,提供了虚拟内存的支持。 #但是需要注意的是,redis中,所有的key都会放在内存中,在内存不够时,只会把value 值放入交换区。 #这样保证了虽然使用虚拟内存,但性能基本不受影响,同时,你需要注意的是你要把vm-max-memory设置到足够来放下你的所有的key vm-enabled no # vm-enabled yes # This is the path of the Redis swap file. As you can guess, swap files # can‘t be shared by different Redis instances, so make sure to use a swap # file for every redis process you are running. Redis will complain if the # swap file is already in use. # # The best kind of storage for the Redis swap file (that‘s accessed at random) # is a Solid State Disk (SSD). # # *** WARNING *** if you are using a shared hosting the default of putting # the swap file under /tmp is not secure. Create a dir with access granted # only to Redis user and configure Redis to create the swap file there. #设置虚拟内存的交换文件路径 vm-swap-file /tmp/redis.swap # vm-max-memory configures the VM to use at max the specified amount of # RAM. Everything that deos not fit will be swapped on disk *if* possible, that # is, if there is still enough contiguous space in the swap file. # # With vm-max-memory 0 the system will swap everything it can. Not a good # default, just specify the max amount of RAM you can in bytes, but it‘s # better to leave some margin. For instance specify an amount of RAM # that‘s more or less between 60 and 80% of your free RAM. #这里设置开启虚拟内存之后,redis将使用的最大物理内存的大小。默认为0,redis将把他所有的能放到交换文件的都放到交换文件中,以尽量少的使用物理内存。 #在生产环境下,需要根据实际情况设置该值,最好不要使用默认的 0 vm-max-memory 0 # Redis swap files is split into pages. An object can be saved using multiple # contiguous pages, but pages can‘t be shared between different objects. # So if your page is too big, small objects swapped out on disk will waste # a lot of space. If you page is too small, there is less space in the swap # file (assuming you configured the same number of total swap file pages). # # If you use a lot of small objects, use a page size of 64 or 32 bytes. # If you use a lot of big objects, use a bigger page size. # If unsure, use the default #设置虚拟内存的页大小,如果你的 value 值比较大,比如说你要在 value 中放置博客、新闻之类的所有文章内容,就设大一点,如果要放置的都是很小的内容,那就设小一点 vm-page-size 32 # Number of total memory pages in the swap file. # Given that the page table (a bitmap of free/used pages) is taken in memory, # every 8 pages on disk will consume 1 byte of RAM. # # The total swap size is vm-page-size * vm-pages # # With the default of 32-bytes memory pages and 134217728 pages Redis will # use a 4 GB swap file, that will use 16 MB of RAM for the page table. # # It‘s better to use the smallest acceptable value for your application, # but the default is large in order to work in most conditions. #设置交换文件的总的 page 数量,需要注意的是,page table信息会放在物理内存中,每8个page 就会占据RAM中的 1 个 byte。 #总的虚拟内存大小 = vm-page-size * vm-pages vm-pages 134217728 # Max number of VM I/O threads running at the same time. # This threads are used to read/write data from/to swap file, since they # also encode and decode objects from disk to memory or the reverse, a bigger # number of threads can help with big objects even if they can‘t help with # I/O itself as the physical device may not be able to couple with many # reads/writes operations at the same time. # # The special value of 0 turn off threaded I/O and enables the blocking # Virtual Memory implementation. #设置 VM IO 同时使用的线程数量。 vm-max-threads 4 # Hashes are encoded in a special way (much more memory efficient) when they # have at max a given numer of elements, and the biggest element does not # exceed a given threshold. You can configure this limits with the following # configuration directives. #redis 2.0 中引入了 hash 数据结构。 #hash 中包含超过指定元素个数并且最大的元素当没有超过临界时,hash 将以zipmap(又称为 small hash大大减少内存使用)来存储,这里可以设置这两个临界值 hash-max-zipmap-entries 512 hash-max-zipmap-value 64 # Active rehashing uses 1 millisecond every 100 milliseconds of CPU time in # order to help rehashing the main Redis hash table (the one mapping top-level # keys to values). The hash table implementation redis uses (see dict.c) # performs a lazy rehashing: the more operation you run into an hash table # that is rhashing, the more rehashing "steps" are performed, so if the # server is idle the rehashing is never complete and some more memory is used # by the hash table. # # The default is to use this millisecond 10 times every second in order to # active rehashing the main dictionaries, freeing memory when possible. # # If unsure: # use "activerehashing no" if you have hard latency requirements and it is # not a good thing in your environment that Redis can reply form time to time # to queries with 2 milliseconds delay. # # use "activerehashing yes" if you don‘t have such hard requirements but # want to free memory asap when possible. #开启之后,redis 将在每 100 毫秒时使用 1 毫秒的 CPU 时间来对 redis 的 hash 表进行重新 hash,可以降低内存的使用。 #当你的使用场景中,有非常严格的实时性需要,不能够接受 Redis 时不时的对请求有 2 毫秒的延迟的话,把这项配置为 no。 #如果没有这么严格的实时性要求,可以设置为 yes,以便能够尽可能快的释放内存 activerehashing yes
http://www.cnblogs.com/linjiqin/archive/2013/05/27/3102040.html
一、server端安装
1、下载
https://github.com/MSOpenTech/redis
可看到当前可下载版本:redis2.6

下载windows平台文件:


解压后,选择当前64位win7系统对应的版本:

2、安装
1)解压后将里面所有文件拷贝至redis安装目录:

几个exe程序的功能:
redis-benchmark.exe:性能测试,用以模拟同时由N个客户端发送M个 SETs/GETs 查询 (类似于 Apache 的ab 工具).
redis-check-aof.exe:更新日志检查
redis-check-dump.exe:本地数据库检查
redis-server.exe:服务端
2)将路径添加至系统环境变量:过程略
3)cmd下启动redis-server

注:由于此处未指定配置文件,系统采用默认参数
3、下载对应的配置文件
由上面cmd输出可知,当前版本为2.6.12
原页面上打开所有发布版本,找到2.6.12:

下载zip文件:

拷贝出redis.conf配置文件至安装目录:


配置文件各字段含义:http://cardyn.iteye.com/blog/794194
ps:如果配置文件的版本和当前exe程序的版本不匹配,很容易
由于参数不一致导致server端无法启动。
4、通过指定的配置文件启动服务端

5、客户端访问测试
另起一个cmd窗口:

二、基本功能测试
1、程序基本结构

2、主要类
1)功能类

package com.redis;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.JedisShardInfo;
import redis.clients.jedis.ShardedJedis;
import redis.clients.jedis.ShardedJedisPool;
import redis.clients.jedis.SortingParams;
public class RedisClient {
private Jedis jedis;//非切片额客户端连接
private JedisPool jedisPool;//非切片连接池
private ShardedJedis shardedJedis;//切片额客户端连接
private ShardedJedisPool shardedJedisPool;//切片连接池
public RedisClient()
{
initialPool();
initialShardedPool();
shardedJedis = shardedJedisPool.getResource();
jedis = jedisPool.getResource();
}
/**
* 初始化非切片池
*/
private void initialPool()
{
// 池基本配置
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxActive(20);
config.setMaxIdle(5);
config.setMaxWait(1000l);
config.setTestOnBorrow(false);
jedisPool = new JedisPool(config,"127.0.0.1",6379);
}
/**
* 初始化切片池
*/
private void initialShardedPool()
{
// 池基本配置
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxActive(20);
config.setMaxIdle(5);
config.setMaxWait(1000l);
config.setTestOnBorrow(false);
// slave链接
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add(new JedisShardInfo("127.0.0.1", 6379, "master"));
// 构造池
shardedJedisPool = new ShardedJedisPool(config, shards);
}
public void show() {
KeyOperate();
StringOperate();
ListOperate();
SetOperate();
SortedSetOperate();
HashOperate();
jedisPool.returnResource(jedis);
shardedJedisPool.returnResource(shardedJedis);
}
private void KeyOperate() {
。。。
}
private void StringOperate() {
。。。
}
private void ListOperate() {
。。。
}
private void SetOperate() {
。。。
}
private void SortedSetOperate() {
。。。
}
private void HashOperate() {
。。。
}
}
2)测试类
package com.redis;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
new RedisClient().show();
}
}
3、各个功能函数
1)key功能
private void KeyOperate()
{
System.out.println("======================key==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
// 判断key否存在
System.out.println("判断key999键是否存在:"+shardedJedis.exists("key999"));
System.out.println("新增key001,value001键值对:"+shardedJedis.set("key001", "value001"));
System.out.println("判断key001是否存在:"+shardedJedis.exists("key001"));
// 输出系统中所有的key
System.out.println("新增key002,value002键值对:"+shardedJedis.set("key002", "value002"));
System.out.println("系统中所有键如下:");
Set<String> keys = jedis.keys("*");
Iterator<String> it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
// 删除某个key,若key不存在,则忽略该命令。
System.out.println("系统中删除key002: "+jedis.del("key002"));
System.out.println("判断key002是否存在:"+shardedJedis.exists("key002"));
// 设置 key001的过期时间
System.out.println("设置 key001的过期时间为5秒:"+jedis.expire("key001", 5));
try{
Thread.sleep(2000);
}
catch (InterruptedException e){
}
// 查看某个key的剩余生存时间,单位【秒】.永久生存或者不存在的都返回-1
System.out.println("查看key001的剩余生存时间:"+jedis.ttl("key001"));
// 移除某个key的生存时间
System.out.println("移除key001的生存时间:"+jedis.persist("key001"));
System.out.println("查看key001的剩余生存时间:"+jedis.ttl("key001"));
// 查看key所储存的值的类型
System.out.println("查看key所储存的值的类型:"+jedis.type("key001"));
/*
* 一些其他方法:1、修改键名:jedis.rename("key6", "key0");
* 2、将当前db的key移动到给定的db当中:jedis.move("foo", 1)
*/
}
运行结果:
======================key========================== 清空库中所有数据:OK 判断key999键是否存在:false 新增key001,value001键值对:OK 判断key001是否存在:true 新增key002,value002键值对:OK 系统中所有键如下: key002 key001 系统中删除key002: 1 判断key002是否存在:false 设置 key001的过期时间为5秒:1 查看key001的剩余生存时间:3 移除key001的生存时间:1 查看key001的剩余生存时间:-1 查看key所储存的值的类型:string
2)String功能
private void StringOperate()
{
System.out.println("======================String_1==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
jedis.set("key001","value001");
jedis.set("key002","value002");
jedis.set("key003","value003");
System.out.println("已新增的3个键值对如下:");
System.out.println(jedis.get("key001"));
System.out.println(jedis.get("key002"));
System.out.println(jedis.get("key003"));
System.out.println("=============删=============");
System.out.println("删除key003键值对:"+jedis.del("key003"));
System.out.println("获取key003键对应的值:"+jedis.get("key003"));
System.out.println("=============改=============");
//1、直接覆盖原来的数据
System.out.println("直接覆盖key001原来的数据:"+jedis.set("key001","value001-update"));
System.out.println("获取key001对应的新值:"+jedis.get("key001"));
//2、直接覆盖原来的数据
System.out.println("在key002原来值后面追加:"+jedis.append("key002","+appendString"));
System.out.println("获取key002对应的新值"+jedis.get("key002"));
System.out.println("=============增,删,查(多个)=============");
/**
* mset,mget同时新增,修改,查询多个键值对
* 等价于:
* jedis.set("name","ssss");
* jedis.set("jarorwar","xxxx");
*/
System.out.println("一次性新增key201,key202,key203,key204及其对应值:"+jedis.mset("key201","value201",
"key202","value202","key203","value203","key204","value204"));
System.out.println("一次性获取key201,key202,key203,key204各自对应的值:"+
jedis.mget("key201","key202","key203","key204"));
System.out.println("一次性删除key201,key202:"+jedis.del(new String[]{"key201", "key202"}));
System.out.println("一次性获取key201,key202,key203,key204各自对应的值:"+
jedis.mget("key201","key202","key203","key204"));
System.out.println();
//jedis具备的功能shardedJedis中也可直接使用,下面测试一些前面没用过的方法
System.out.println("======================String_2==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============新增键值对时防止覆盖原先值=============");
System.out.println("原先key301不存在时,新增key301:"+shardedJedis.setnx("key301", "value301"));
System.out.println("原先key302不存在时,新增key302:"+shardedJedis.setnx("key302", "value302"));
System.out.println("当key302存在时,尝试新增key302:"+shardedJedis.setnx("key302", "value302_new"));
System.out.println("获取key301对应的值:"+shardedJedis.get("key301"));
System.out.println("获取key302对应的值:"+shardedJedis.get("key302"));
System.out.println("=============超过有效期键值对被删除=============");
// 设置key的有效期,并存储数据
System.out.println("新增key303,并指定过期时间为2秒"+shardedJedis.setex("key303", 2, "key303-2second"));
System.out.println("获取key303对应的值:"+shardedJedis.get("key303"));
try{
Thread.sleep(3000);
}
catch (InterruptedException e){
}
System.out.println("3秒之后,获取key303对应的值:"+shardedJedis.get("key303"));
System.out.println("=============获取原值,更新为新值一步完成=============");
System.out.println("key302原值:"+shardedJedis.getSet("key302", "value302-after-getset"));
System.out.println("key302新值:"+shardedJedis.get("key302"));
System.out.println("=============获取子串=============");
System.out.println("获取key302对应值中的子串:"+shardedJedis.getrange("key302", 5, 7));
}
运行结果:
======================String_1========================== 清空库中所有数据:OK =============增============= 已新增的3个键值对如下: value001 value002 value003 =============删============= 删除key003键值对:1 获取key003键对应的值:null =============改============= 直接覆盖key001原来的数据:OK 获取key001对应的新值:value001-update 在key002原来值后面追加:21 获取key002对应的新值value002+appendString =============增,删,查(多个)============= 一次性新增key201,key202,key203,key204及其对应值:OK 一次性获取key201,key202,key203,key204各自对应的值:[value201, value202, value203, value204] 一次性删除key201,key202:2 一次性获取key201,key202,key203,key204各自对应的值:[null, null, value203, value204] ======================String_2========================== 清空库中所有数据:OK =============新增键值对时防止覆盖原先值============= 原先key301不存在时,新增key301:1 原先key302不存在时,新增key302:1 当key302存在时,尝试新增key302:0 获取key301对应的值:value301 获取key302对应的值:value302 =============超过有效期键值对被删除============= 新增key303,并指定过期时间为2秒OK 获取key303对应的值:key303-2second 3秒之后,获取key303对应的值:null =============获取原值,更新为新值一步完成============= key302原值:value302 key302新值:value302-after-getset =============获取子串============= 获取key302对应值中的子串:302
3)List功能
private void ListOperate()
{
System.out.println("======================list==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "ArrayList");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "LinkedList");
shardedJedis.lpush("stringlists", "MapList");
shardedJedis.lpush("stringlists", "SerialList");
shardedJedis.lpush("stringlists", "HashList");
shardedJedis.lpush("numberlists", "3");
shardedJedis.lpush("numberlists", "1");
shardedJedis.lpush("numberlists", "5");
shardedJedis.lpush("numberlists", "2");
System.out.println("所有元素-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("所有元素-numberlists:"+shardedJedis.lrange("numberlists", 0, -1));
System.out.println("=============删=============");
// 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈
System.out.println("成功删除指定元素个数-stringlists:"+shardedJedis.lrem("stringlists", 2, "vector"));
System.out.println("删除指定元素之后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
// 删除区间以外的数据
System.out.println("删除下标0-3区间之外的元素:"+shardedJedis.ltrim("stringlists", 0, 3));
System.out.println("删除指定区间之外元素后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
// 列表元素出栈
System.out.println("出栈元素:"+shardedJedis.lpop("stringlists"));
System.out.println("元素出栈后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("=============改=============");
// 修改列表中指定下标的值
shardedJedis.lset("stringlists", 0, "hello list!");
System.out.println("下标为0的值修改后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("=============查=============");
// 数组长度
System.out.println("长度-stringlists:"+shardedJedis.llen("stringlists"));
System.out.println("长度-numberlists:"+shardedJedis.llen("numberlists"));
// 排序
/*
* list中存字符串时必须指定参数为alpha,如果不使用SortingParams,而是直接使用sort("list"),
* 会出现"ERR One or more scores can‘t be converted into double"
*/
SortingParams sortingParameters = new SortingParams();
sortingParameters.alpha();
sortingParameters.limit(0, 3);
System.out.println("返回排序后的结果-stringlists:"+shardedJedis.sort("stringlists",sortingParameters));
System.out.println("返回排序后的结果-numberlists:"+shardedJedis.sort("numberlists"));
// 子串: start为元素下标,end也为元素下标;-1代表倒数一个元素,-2代表倒数第二个元素
System.out.println("子串-第二个开始到结束:"+shardedJedis.lrange("stringlists", 1, -1));
// 获取列表指定下标的值
System.out.println("获取下标为2的元素:"+shardedJedis.lindex("stringlists", 2)+"\n");
}
运行结果:
======================list========================== 清空库中所有数据:OK =============增============= 所有元素-stringlists:[HashList, SerialList, MapList, LinkedList, vector, vector, ArrayList, vector] 所有元素-numberlists:[2, 5, 1, 3] =============删============= 成功删除指定元素个数-stringlists:2 删除指定元素之后-stringlists:[HashList, SerialList, MapList, LinkedList, ArrayList, vector] 删除下标0-3区间之外的元素:OK 删除指定区间之外元素后-stringlists:[HashList, SerialList, MapList, LinkedList] 出栈元素:HashList 元素出栈后-stringlists:[SerialList, MapList, LinkedList] =============改============= 下标为0的值修改后-stringlists:[hello list!, MapList, LinkedList] =============查============= 长度-stringlists:3 长度-numberlists:4 返回排序后的结果-stringlists:[LinkedList, MapList, hello list!] 返回排序后的结果-numberlists:[1, 2, 3, 5] 子串-第二个开始到结束:[MapList, LinkedList] 获取下标为2的元素:LinkedList
4)Set功能
private void SetOperate()
{
System.out.println("======================set==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
System.out.println("向sets集合中加入元素element001:"+jedis.sadd("sets", "element001"));
System.out.println("向sets集合中加入元素element002:"+jedis.sadd("sets", "element002"));
System.out.println("向sets集合中加入元素element003:"+jedis.sadd("sets", "element003"));
System.out.println("向sets集合中加入元素element004:"+jedis.sadd("sets", "element004"));
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));
System.out.println();
System.out.println("=============删=============");
System.out.println("集合sets中删除元素element003:"+jedis.srem("sets", "element003"));
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));
/*System.out.println("sets集合中任意位置的元素出栈:"+jedis.spop("sets"));//注:出栈元素位置居然不定?--无实际意义
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));*/
System.out.println();
System.out.println("=============改=============");
System.out.println();
System.out.println("=============查=============");
System.out.println("判断element001是否在集合sets中:"+jedis.sismember("sets", "element001"));
System.out.println("循环查询获取sets中的每个元素:");
Set<String> set = jedis.smembers("sets");
Iterator<String> it=set.iterator() ;
while(it.hasNext()){
Object obj=it.next();
System.out.println(obj);
}
System.out.println();
System.out.println("=============集合运算=============");
System.out.println("sets1中添加元素element001:"+jedis.sadd("sets1", "element001"));
System.out.println("sets1中添加元素element002:"+jedis.sadd("sets1", "element002"));
System.out.println("sets1中添加元素element003:"+jedis.sadd("sets1", "element003"));
System.out.println("sets1中添加元素element002:"+jedis.sadd("sets2", "element002"));
System.out.println("sets1中添加元素element003:"+jedis.sadd("sets2", "element003"));
System.out.println("sets1中添加元素element004:"+jedis.sadd("sets2", "element004"));
System.out.println("查看sets1集合中的所有元素:"+jedis.smembers("sets1"));
System.out.println("查看sets2集合中的所有元素:"+jedis.smembers("sets2"));
System.out.println("sets1和sets2交集:"+jedis.sinter("sets1", "sets2"));
System.out.println("sets1和sets2并集:"+jedis.sunion("sets1", "sets2"));
System.out.println("sets1和sets2差集:"+jedis.sdiff("sets1", "sets2"));//差集:set1中有,set2中没有的元素
}
运行结果:
======================set========================== 清空库中所有数据:OK =============增============= 向sets集合中加入元素element001:1 向sets集合中加入元素element002:1 向sets集合中加入元素element003:1 向sets集合中加入元素element004:1 查看sets集合中的所有元素:[element001, element002, element003, element004] =============删============= 集合sets中删除元素element003:1 查看sets集合中的所有元素:[element001, element002, element004] =============改============= =============查============= 判断element001是否在集合sets中:true 循环查询获取sets中的每个元素: element001 element002 element004 =============集合运算============= sets1中添加元素element001:1 sets1中添加元素element002:1 sets1中添加元素element003:1 sets1中添加元素element002:1 sets1中添加元素element003:1 sets1中添加元素element004:1 查看sets1集合中的所有元素:[element001, element002, element003] 查看sets2集合中的所有元素:[element002, element003, element004] sets1和sets2交集:[element002, element003] sets1和sets2并集:[element001, element002, element003, element004] sets1和sets2差集:[element001]
5)SortedSet功能(有序集合)
private void SortedSetOperate()
{
System.out.println("======================zset==========================");
// 清空数据
System.out.println(jedis.flushDB());
System.out.println("=============增=============");
System.out.println("zset中添加元素element001:"+shardedJedis.zadd("zset", 7.0, "element001"));
System.out.println("zset中添加元素element002:"+shardedJedis.zadd("zset", 8.0, "element002"));
System.out.println("zset中添加元素element003:"+shardedJedis.zadd("zset", 2.0, "element003"));
System.out.println("zset中添加元素element004:"+shardedJedis.zadd("zset", 3.0, "element004"));
System.out.println("zset集合中的所有元素:"+shardedJedis.zrange("zset", 0, -1));//按照权重值排序
System.out.println();
System.out.println("=============删=============");
System.out.println("zset中删除元素element002:"+shardedJedis.zrem("zset", "element002"));
System.out.println("zset集合中的所有元素:"+shardedJedis.zrange("zset", 0, -1));
System.out.println();
System.out.println("=============改=============");
System.out.println();
System.out.println("=============查=============");
System.out.println("统计zset集合中的元素中个数:"+shardedJedis.zcard("zset"));
System.out.println("统计zset集合中权重某个范围内(1.0——5.0),元素的个数:"+shardedJedis.zcount("zset", 1.0, 5.0));
System.out.println("查看zset集合中element004的权重:"+shardedJedis.zscore("zset", "element004"));
System.out.println("查看下标1到2范围内的元素值:"+shardedJedis.zrange("zset", 1, 2));
}
运行结果:
======================zset========================== OK =============增============= zset中添加元素element001:1 zset中添加元素element002:1 zset中添加元素element003:1 zset中添加元素element004:1 zset集合中的所有元素:[element003, element004, element001, element002] =============删============= zset中删除元素element002:1 zset集合中的所有元素:[element003, element004, element001] =============改============= =============查============= 统计zset集合中的元素中个数:3 统计zset集合中权重某个范围内(1.0——5.0),元素的个数:2 查看zset集合中element004的权重:3.0 查看下标1到2范围内的元素值:[element004, element001]
6)Hash功能
private void HashOperate()
{
System.out.println("======================hash==========================");
//清空数据
System.out.println(jedis.flushDB());
System.out.println("=============增=============");
System.out.println("hashs中添加key001和value001键值对:"+shardedJedis.hset("hashs", "key001", "value001"));
System.out.println("hashs中添加key002和value002键值对:"+shardedJedis.hset("hashs", "key002", "value002"));
System.out.println("hashs中添加key003和value003键值对:"+shardedJedis.hset("hashs", "key003", "value003"));
System.out.println("新增key004和4的整型键值对:"+shardedJedis.hincrBy("hashs", "key004", 4l));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============删=============");
System.out.println("hashs中删除key002键值对:"+shardedJedis.hdel("hashs", "key002"));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============改=============");
System.out.println("key004整型键值的值增加100:"+shardedJedis.hincrBy("hashs", "key004", 100l));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============查=============");
System.out.println("判断key003是否存在:"+shardedJedis.hexists("hashs", "key003"));
System.out.println("获取key004对应的值:"+shardedJedis.hget("hashs", "key004"));
System.out.println("批量获取key001和key003对应的值:"+shardedJedis.hmget("hashs", "key001", "key003"));
System.out.println("获取hashs中所有的key:"+shardedJedis.hkeys("hashs"));
System.out.println("获取hashs中所有的value:"+shardedJedis.hvals("hashs"));
System.out.println();
}
运行结果:
======================hash========================== OK =============增============= hashs中添加key001和value001键值对:1 hashs中添加key002和value002键值对:1 hashs中添加key003和value003键值对:1 新增key004和4的整型键值对:4 hashs中的所有值:[value001, value002, value003, 4] =============删============= hashs中删除key002键值对:1 hashs中的所有值:[value001, value003, 4] =============改============= key004整型键值的值增加100:104 hashs中的所有值:[value001, value003, 104] =============查============= 判断key003是否存在:true 获取key004对应的值:104 批量获取key001和key003对应的值:[value001, value003] 获取hashs中所有的key:[key004, key003, key001] 获取hashs中所有的value:[value001, value003, 104]
三、常用命令 1)连接操作命令 quit:关闭连接(connection) auth:简单密码认证 help cmd: 查看cmd帮助,例如:help quit 2)持久化 save:将数据同步保存到磁盘 bgsave:将数据异步保存到磁盘 lastsave:返回上次成功将数据保存到磁盘的Unix时戳 shundown:将数据同步保存到磁盘,然后关闭服务 3)远程服务控制 info:提供服务器的信息和统计 monitor:实时转储收到的请求 slaveof:改变复制策略设置 config:在运行时配置Redis服务器 4)对value操作的命令 exists(key):确认一个key是否存在 del(key):删除一个key type(key):返回值的类型 keys(pattern):返回满足给定pattern的所有key randomkey:随机返回key空间的一个 keyrename(oldname, newname):重命名key dbsize:返回当前数据库中key的数目 expire:设定一个key的活动时间(s) ttl:获得一个key的活动时间 select(index):按索引查询 move(key, dbindex):移动当前数据库中的key到dbindex数据库 flushdb:删除当前选择数据库中的所有key flushall:删除所有数据库中的所有key 5)String set(key, value):给数据库中名称为key的string赋予值value get(key):返回数据库中名称为key的string的value getset(key, value):给名称为key的string赋予上一次的value mget(key1, key2,…, key N):返回库中多个string的value setnx(key, value):添加string,名称为key,值为value setex(key, time, value):向库中添加string,设定过期时间time mset(key N, value N):批量设置多个string的值 msetnx(key N, value N):如果所有名称为key i的string都不存在 incr(key):名称为key的string增1操作 incrby(key, integer):名称为key的string增加integer decr(key):名称为key的string减1操作 decrby(key, integer):名称为key的string减少integer append(key, value):名称为key的string的值附加value substr(key, start, end):返回名称为key的string的value的子串 6)List rpush(key, value):在名称为key的list尾添加一个值为value的元素 lpush(key, value):在名称为key的list头添加一个值为value的 元素 llen(key):返回名称为key的list的长度 lrange(key, start, end):返回名称为key的list中start至end之间的元素 ltrim(key, start, end):截取名称为key的list lindex(key, index):返回名称为key的list中index位置的元素 lset(key, index, value):给名称为key的list中index位置的元素赋值 lrem(key, count, value):删除count个key的list中值为value的元素 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。 brpop(key1, key2,… key N, timeout):rpop的block版本。 rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,
并将该元素添加到名称为dstkey的list的头部 7)Set sadd(key, member):向名称为key的set中添加元素member srem(key, member) :删除名称为key的set中的元素member spop(key) :随机返回并删除名称为key的set中一个元素 smove(srckey, dstkey, member) :移到集合元素 scard(key) :返回名称为key的set的基数 sismember(key, member) :member是否是名称为key的set的元素 sinter(key1, key2,…key N) :求交集 sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合 sunion(key1, (keys)) :求并集 sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合 sdiff(key1, (keys)) :求差集 sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合 smembers(key) :返回名称为key的set的所有元素 srandmember(key) :随机返回名称为key的set的一个元素 8)Hash hset(key, field, value):向名称为key的hash中添加元素field hget(key, field):返回名称为key的hash中field对应的value hmget(key, (fields)):返回名称为key的hash中field i对应的value hmset(key, (fields)):向名称为key的hash中添加元素field hincrby(key, field, integer):将名称为key的hash中field的value增加integer hexists(key, field):名称为key的hash中是否存在键为field的域 hdel(key, field):删除名称为key的hash中键为field的域 hlen(key):返回名称为key的hash中元素个数 hkeys(key):返回名称为key的hash中所有键 hvals(key):返回名称为key的hash中所有键对应的value hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
参考:http://blog.csdn.net/ithomer/article/details/9213185
http://www.cnblogs.com/edisonfeng/p/3571870.html
标签:
原文地址:http://www.cnblogs.com/softidea/p/4743731.html