标签:
1.HDFS的Block块概念
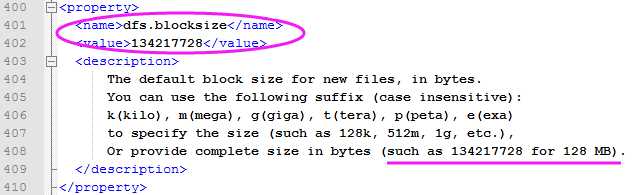
HDFS默认的Block块大小为128 MB。为何HDFS中的一个块那么大?
HDFS的block块比磁盘的块大,目的是为了减小寻址开销。通过让一个块足够大,从磁盘转移数据的时间能够远远大于定位这个块开始端的时间。因此,传送一个由多个块组成的文件的时间就取决于磁盘传输送率。
HDFS中 fsck 指令会显示块的信息:
% hadoop fsck / -files -blocks
2.NN主要功能
1)NN提供名称查询服务,它是一个Jetty服务器。
2)NN维护着整个HDFS系统的元数据信息。包括内存元数据和元数据文件两种。其中NN在内存中维护整个文件系统的元数据镜像,用于HDFS的管理;元数据文件 fsimage 和edits 则用于持久化存储。
3)NN也记录着每个文件的数据块存储的DN,但它并不永久保存块的位置信息,因为这些信息由DN通过每6小时发送一次Block-Report时重建。
3.NN目录结构
NN被格式化之后(区别于DN:使用前不用格式化),将产生如下所示的目录结构:
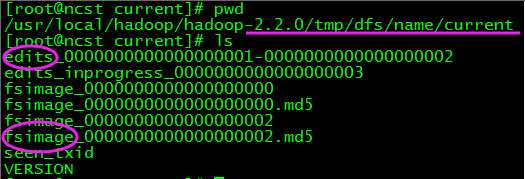
1)实际生产环境中为了安全机制,将dfs.name.dir配置成以逗号隔开的一组目录,各个目录存储的内容相同。这个机制使得系统具备一定的还原能力,特别是当其中一个目录位于NFS之上时(推荐配置)。
2)其中,edits和fsimage是使用Hadoop的writable对象作为其序列化格式的二进制文件。
4.SNN主要功能
每个集群都有一个,SNN只有一个职责:合并NN中的edits到fsimage中。
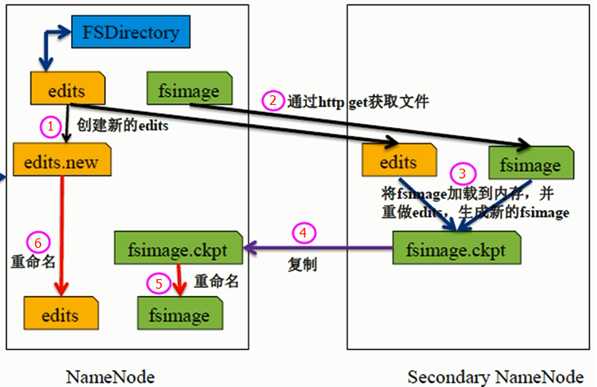
除此之外,当NN处于安全模式时,管理员也可以调用以下命令来手动执行合并两文件:
hadoop dfsadmin –saveNamespace
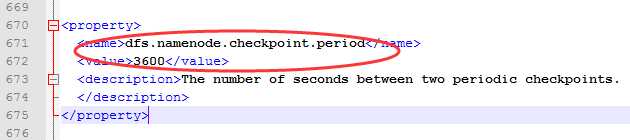
从配置文件hdfs-default.xml中,可以看出SNN定期 3600s=1h 触发一次CheckPoint,可保证各个CheckPoint阶段的元数据的可靠性,同时,进行fsimage与edits的合并,可以有效限制edits的大小,防止其无限制增长。
5.DN节点( 向NN 发送heartbeat 和DirectoryScan)
DN响应来自HDFS客户端的读写请求,还响应来自NN的创建、删除和复制块的命令。


6.DN目录结构
DN的存储目录是启动时自动创建的,不需要额外的格式化【区别于DN】。通过hdfs-default.xml参数dfs.datanode.data.dir 配置。
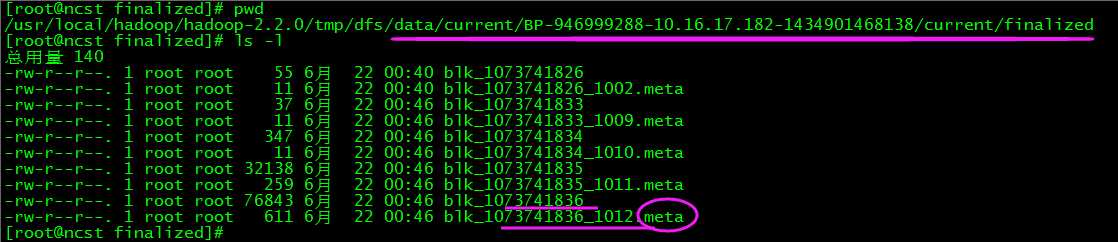
其中,对于以.meta结尾的元数据文件,是以二进制形式保存的,本人以读取二进制的命令od 试过。
Block副本放置策略:
7.文件的读取
文件读取的过程如下:
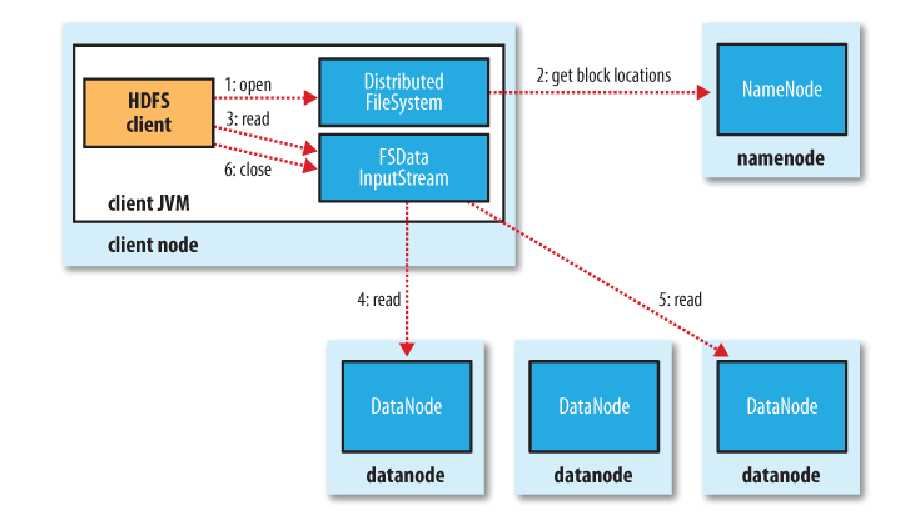
1) 使用HDFS提供的客户端Client,向远程的NN发起RPC请求。
2) NN会视情况返回请求文件的部分或者全部Blcok列表,对于每个Blcok,NN都会返回所有存储该Blcok副本的DN地址;
3) 客户端Client会选择距离最近的DN来读取Blcok;如果客户端本身就是DN,将直接从本地读取数据。
4) 读取完当前Blcok的数据后,关闭与当前DN的连接,并寻找读取下一个Blcok块的最佳DN;
5) 当读完列表中的Blcok后,如若文件读取还没有结束,客户端会继续向NN获取下一批Blcok块的列表。
6) 每读取完一个Blcok都会进行CheckSum验证,如果CheckSum验证出现错误,客户端会通知NN,然后再从列表中选择下一个拥有该Blcok副本的DN继续读取。
8.文件的写入
文件写入的过程,相对读取更为复杂,如下:
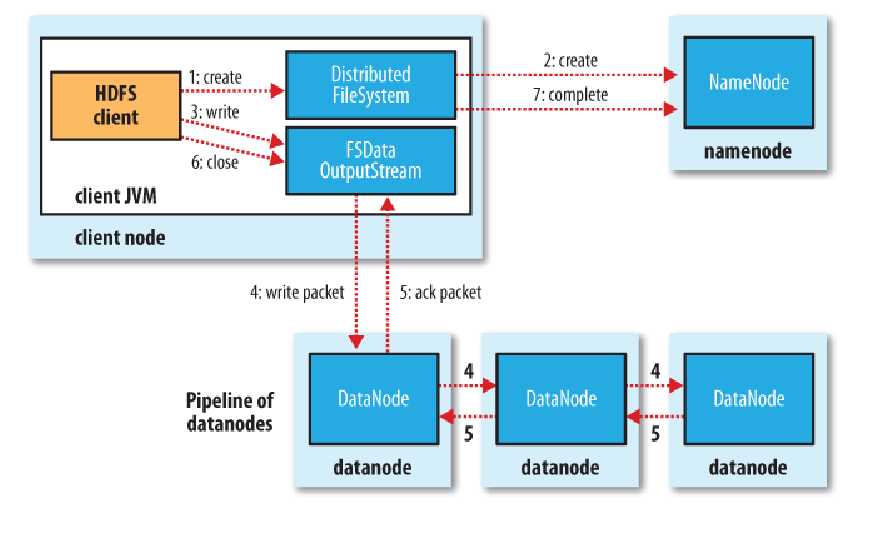
1) 使用HDFS提供的客户端,向远程的NN发起RPC请求;
2) NN会检查要创建的文件是否已经存在,创建者是否有权限进行操作,检查通过则会为文件创建一个写入记录,否则让客户端抛出异常;
3) 当客户端开始写入文件的时候,客户端会将文件切分成多个Packet,并在内部以数据列队"data queue"的形式管理这些Packet,并向NN申请新的Block,获取用来存储Replicas的合适的DN列表,列表的大小根据在NN中对Replication值的设置而定。
4) 开始以管道(Pipeline)的形式将Packet写入所有的Replicas中。首先,客户端把Packet以流的方式写入第一个DN,该DN把该Packet存储之后,再将此Packet从管道(Pipeline)中传递到下一个DN,直到最后一个DN,这种写数据的方式呈流水线的形式(这种方式,相对于Client启动三个线程并行写入三个节点的好处为:将网络瓶颈平摊到四个节点之间)。
5) 最后一个DN成功存储之后会返回一个ack--packet,由管道(Pipeline)传递回客户端,在客户端的内部维护着"ack queue"队列,成功收到DN返回的ack--packet后会从"ack queue"队列移除相应的packet。
6) 如果传输过程中,有某个DN出现了故障,那么当前的管道(Pipeline)会被关闭,出现故障的DN会从当前的管道(Pipeline)中移除,剩余的block会继续在剩下的DN中继续以管道(Pipeline)的形式传输,同时NN会分配一个新的DN,保持Replicas设定的数量。
标签:
原文地址:http://www.cnblogs.com/skyl/p/4744623.html