大数据公司挖掘数据价值的49个典型案例 对于企业来说,100条理论确实不如一个成功的标杆有实践意义,本文的主旨就是寻找“正在做”大数据的49个样本。 力图从企业运营和管理的角度,梳理出发掘大数据价值的一般规律:一是以数据驱动的决策,主要通过提高预测概率,来提高决策成功率;二是以数据驱动的流程,主要是 ...
分类:
其他好文 时间:
2018-09-03 12:13:20
阅读次数:
194
导读:本文是近年来不同行业、不同领域的大数据公司的一些经典案例总结。尽管有些已经是几年前的案例,但其中的深层逻辑对于未来仍有启发。 本文力图从企业运营和管理的角度,梳理出发掘大数据价值的一般规律:一是以数据驱动的决策,主要通过提高预测概率,来提高决策成功率;二是以数据驱动的流程,主要是形成营销闭环战 ...
分类:
其他好文 时间:
2018-08-08 12:06:36
阅读次数:
199
Pandas Pandas是 Python下最强大的数据分析和探索工具。它包含高级的数据结构和精巧的工具,使得在 Python中处理数据非常快速和简单。 Pandas构建在 Numpy之上,它使得以 Numpy为中心的应用很容易使用。Pandas的功能非常强大,支持类似于SQL的数据增、删、查、改, ...
分类:
编程语言 时间:
2018-04-23 12:24:59
阅读次数:
4391
基础概念 类别不均衡是指在分类学习算法中,不同类别样本的比例相差悬殊,它会对算法的学习过程造成重大的干扰。比如在一个二分类的问题上,有1000个样本,其中5个正样本,995个负样本,在这种情况下,算法只需将所有的样本预测为负样本,那么它的精度也可以达到99.5%,虽然结果的精度很高,但它依然没有价值 ...
分类:
其他好文 时间:
2018-04-20 00:19:17
阅读次数:
456
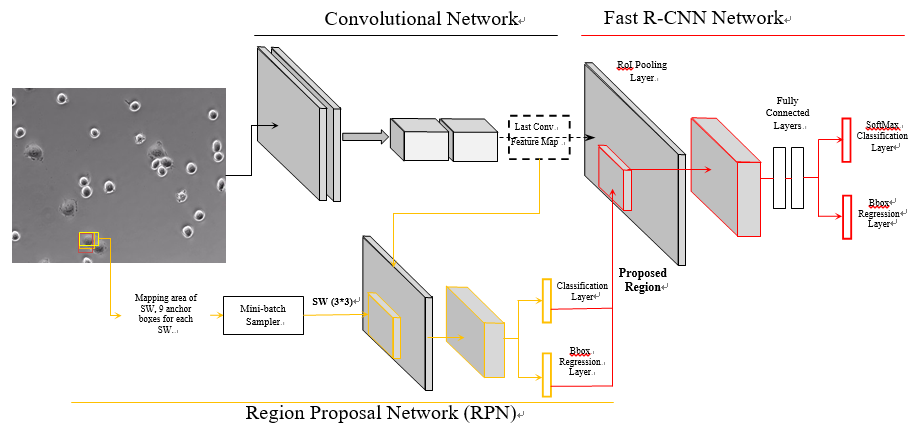?Faster R-CNN,由两个模块组成:第一个模块是深度全卷积网络 RPN,用于 region ... ...
分类:
其他好文 时间:
2018-04-03 17:17:13
阅读次数:
8664
集成学习实践部分也分成三块来讲解: sklearn官方文档:http://scikit-learn.org/stable/modules/ensemble.html#ensemble 1、GBDT 2、XGBoost 3、Adaboost 在sklearn中Adaboost库分成两个,分别是分类和回 ...
分类:
其他好文 时间:
2018-03-17 10:49:31
阅读次数:
290
昨天的序言引发了许多关注 今天我们就推出第一题 【模型评估】 引言 “没有测量,就没有科学。”这是科学家门捷列夫的名言。在计算机科学中,特别是在机器学习的领域,对模型的测量和评估同样至关重要。只有选择与问题相匹配的评估方法,我们才能够快速的发现在模型选择和训练过程中可能出现的问题,迭代地对模型进行优 ...
分类:
其他好文 时间:
2018-02-27 21:24:00
阅读次数:
279
选取预测概率的分割点 cutoff=0.02) { model.predfu 0.2 + i 0.001] ...
分类:
编程语言 时间:
2018-01-17 00:04:03
阅读次数:
142
learn2rank目前基本两个分支,1是神经网络学派ranknet,lamdarank,另一个是决策树学派如gbrank,lamdamart 05年提出ranknet,算分模块是简单的全连接网络,loss函数有些意思。 ...
分类:
Web程序 时间:
2017-11-24 16:56:34
阅读次数:
195
代码及数据:https://github.com/zle1992/MachineLearningInAction logistic regression 优点:计算代价不高,易于理解实现,线性模型的一种。 缺点:容易欠拟合,分类精度不高。但是可以用于预测概率。 适用数据范围:数值型和标称型。 准备数 ...
分类:
编程语言 时间:
2017-05-25 17:17:39
阅读次数:
378